
随着Deepseek-R1的爆火,市面上出现了许多 本地部署deepseek的教程,但是看了一圈发现都是用ollama部署模型。ollama框架虽然上手简单,容易部署,但是其对于高并发的处理不够完善,大部分模型都是量化后的版本,多多少少会影响使用。因此,在企业级的模型部署上需要寻找其他的推理框架。本篇文章就是记录了 最近工作中真实的模型部署与前端部署流程。
一 大模型部署
1.1 推荐框架:Xinference / GPUstack
1.1.1 Xinference :
官网:欢迎来到 Xinference! — Xinference
个人认为是用过最好用的框架,没有之一!docker部署简单,界面操作容易。缺点是要求CUDA>=12.4,且不支持国产硬件。
1.1.2 GPUstack :
官网:GPUStack.ai
github: GitHub - gpustack/gpustack: Manage GPU clusters for running AI models
界面操作容易,部署也较为简单,支持多个cuda版本,且适配了国产npu和rocm,非常适合国产企业部署模型。同时可以将多个服务器组成集群,布更大的模型(满血版deepseek-r1 需要两台16卡A100)
由于笔者的工作需要用到国产的硬件,因此选择了GPUstack,本文也记录GPUstack的部署流程。
1.2 部署方式:
1.2.1 docker部署(推荐)
1.2.1.1 CUDA部署命令:
docker run -d --name gpustack \
--restart=unless-stopped \
--gpus all \
--network=host \
--ipc=host \
-v gpustack-data:/var/lib/gpustack \
-v {模型本地路径}:/app/models \
gpustack/gpustack
如果出现端口冲突,可调整端口号:
docker run -d --name gpustack \
--restart=unless-stopped \
--gpus all \
-p 80:80 \
-p 10150:10150 \
-p 40000-41024:40000-41024 \
-p 50000-51024:50000-51024 \
--ipc=host \
-v gpustack-data:/var/lib/gpustack \
-v {模型本地路径}:/app/models \
gpustack/gpustack --worker-ip your_host_ip
1.2.1.2 Amd ROCm:
docker run -d --name gpustack \
--restart=unless-stopped \
-p 80:80 \
--ipc=host \
--group-add=video \
--security-opt seccomp=unconfined \
--device /dev/kfd \
--device /dev/dri \
-v gpustack-data:/var/lib/gpustack \
gpustack/gpustack:latest-rocm
1.2.1.3 Ascend CANN ( 貌似只能910B)
docker run -d --name gpustack \
--restart=unless-stopped \
-e ASCEND_VISIBLE_DEVICES=0 \
-p 80:80 \
--ipc=host \
-v gpustack-data:/var/lib/gpustack \
gpustack/gpustack:latest-npu
1.2.2 源码部署
Linux/Macos:
curl -sfL https://get.gpustack.ai | sh -s -
Windowns:
Invoke-Expression (Invoke-WebRequest -Uri "https://get.gpustack.ai" -UseBasicParsing).Content
1.3 部署模型
输入:
docker exec -it gpustack cat /var/lib/gpustack/initial_admin_password
获取初始密码,需记住,一会有用
访问http://localhost:80 进行登录(根据你的端口进行调整)
初始用户名为 admin 初始密码为刚刚获取的字符串
登录后会看到如下界面:
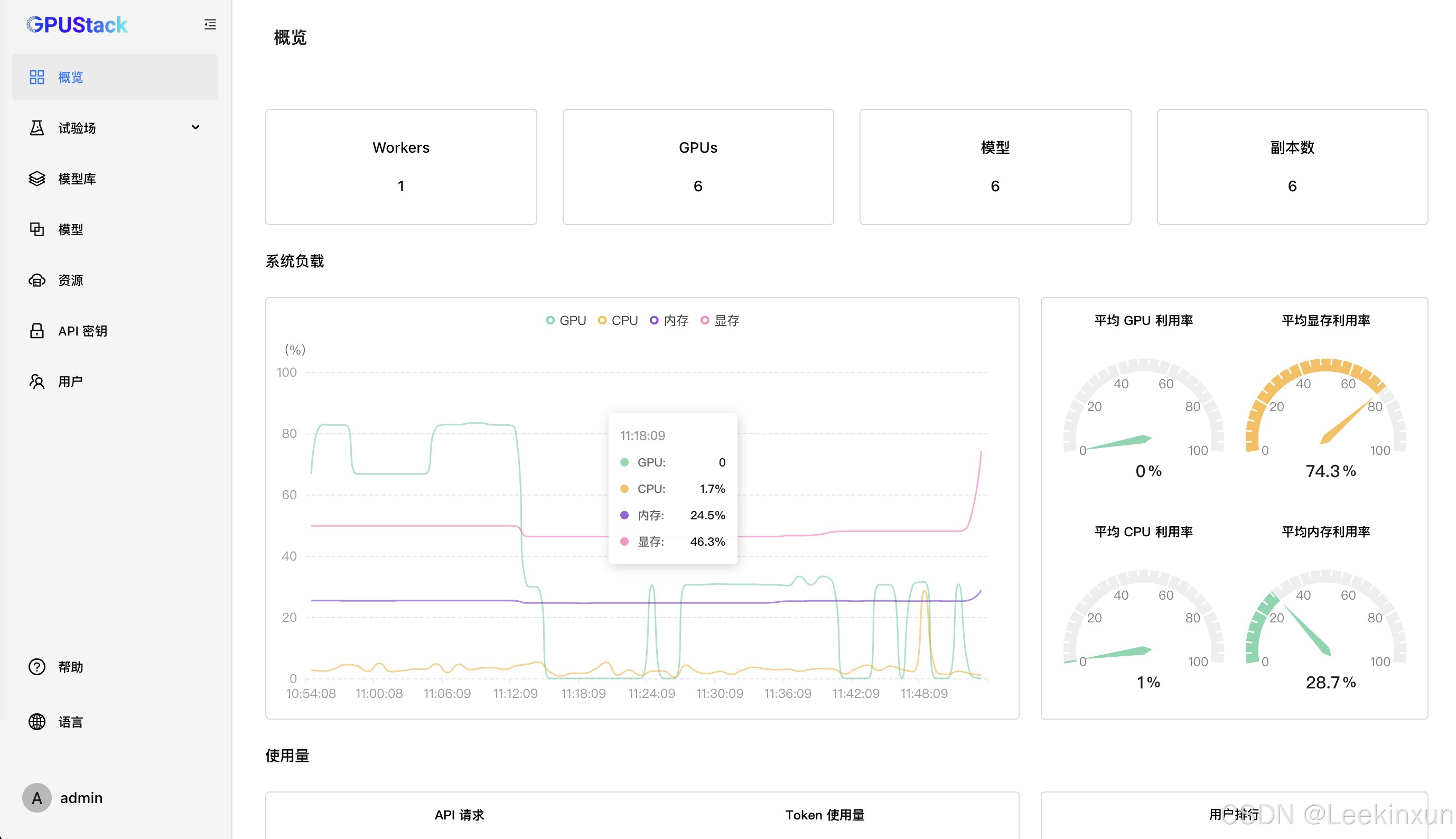
此时点击左侧的模型,进行部署:
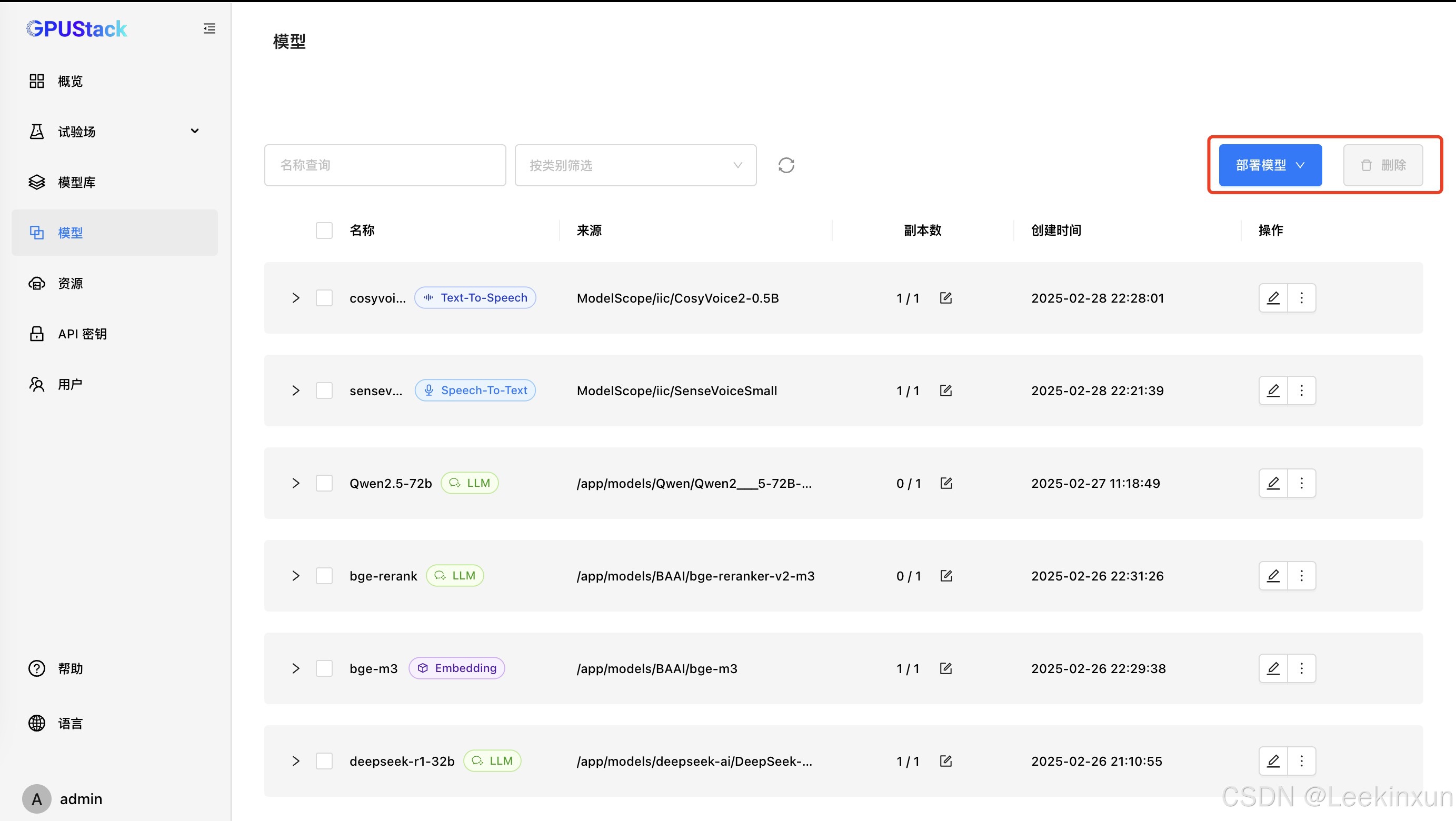
推荐本地部署或modelscope下载部署
1.3.1 modelscope下载部署步骤:
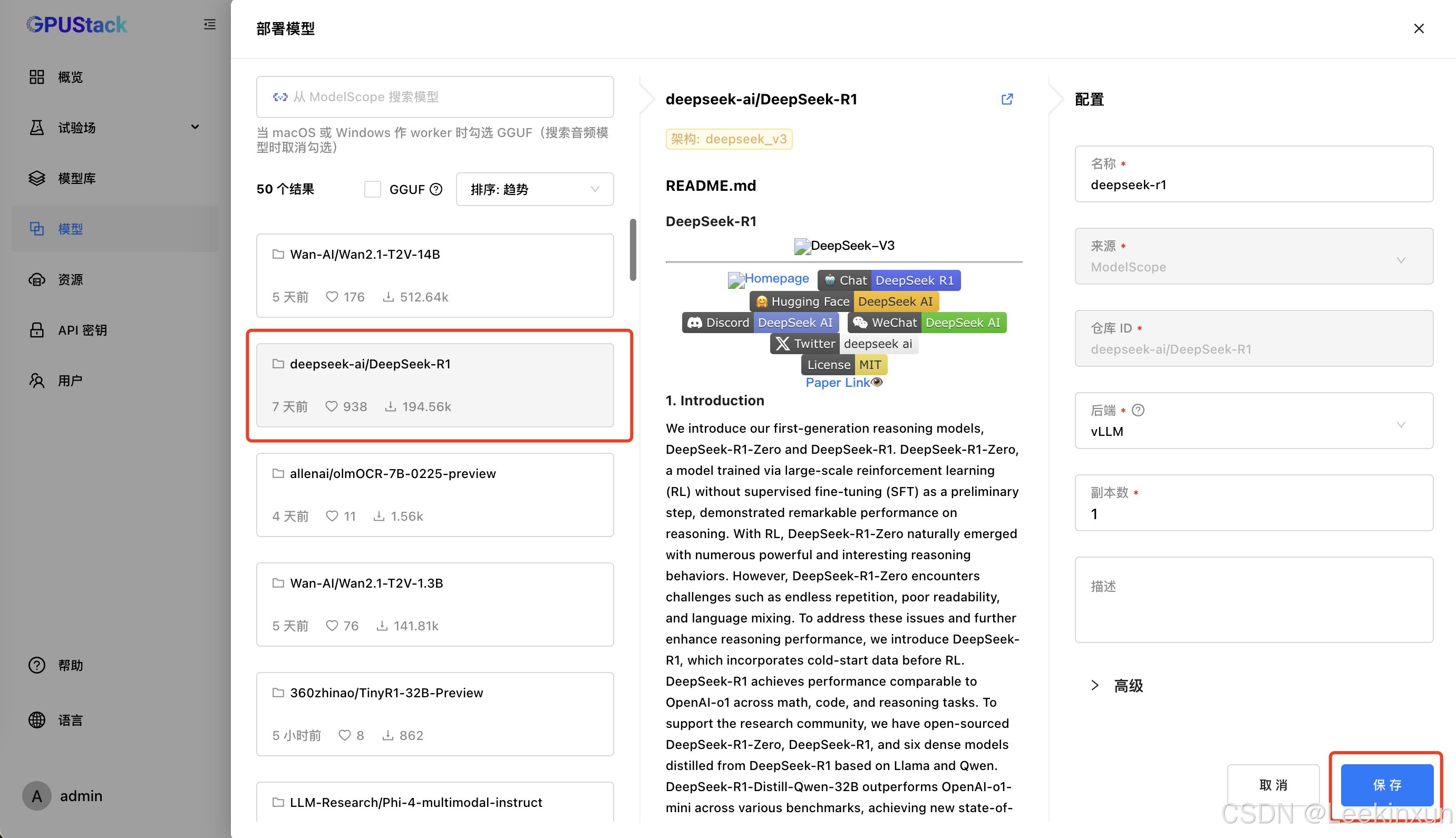
等待下载完成即可
1.3.2 本地部署:
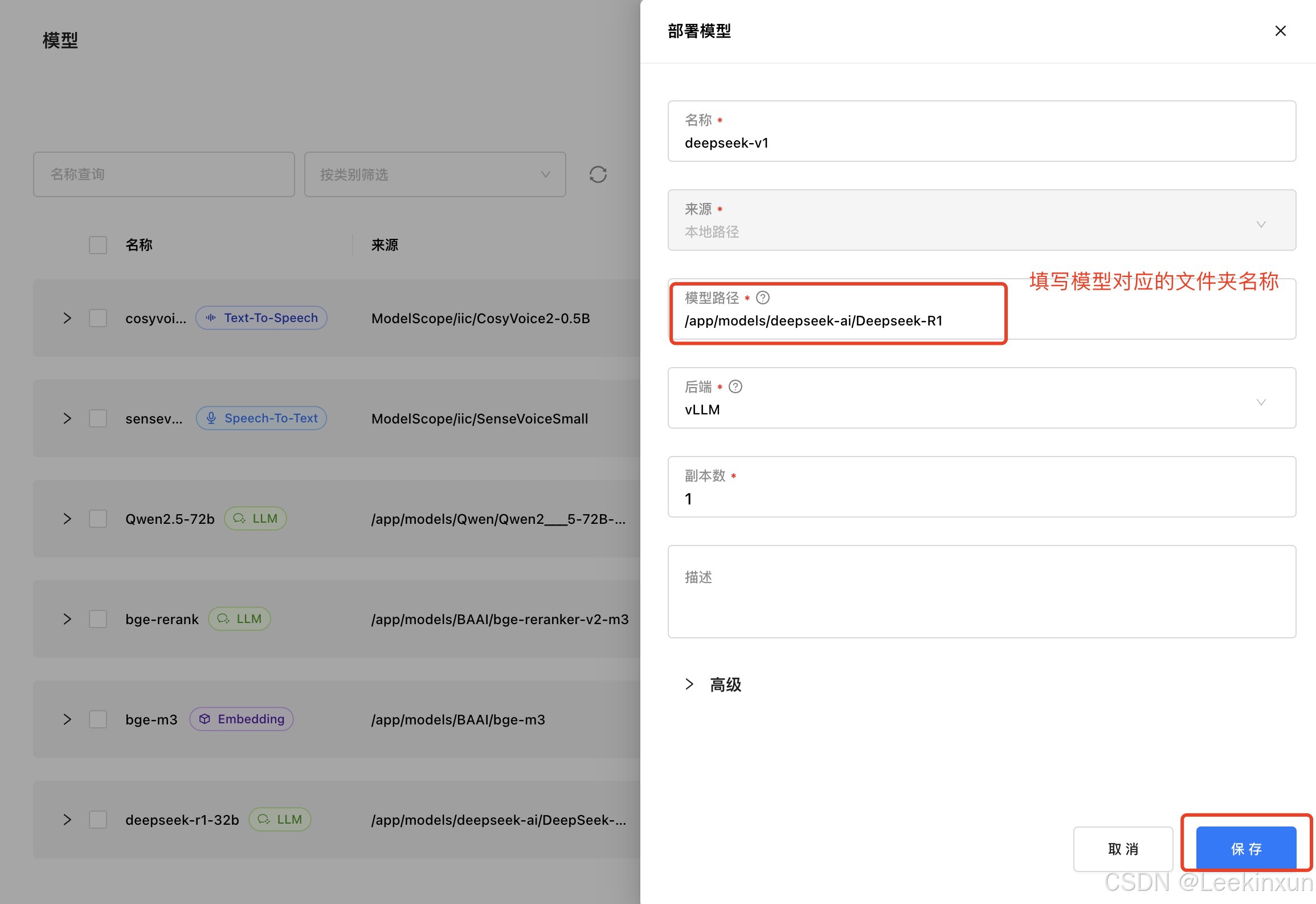
模型显示正在runing即部署完成:

例如我的显示:
0cc86760222f
172.17.0.2:40158
GPU 序号: [1,2]
后端: vllm
后续部署前端界面需要这个端口号
1.4 获取API密钥
左侧 API密钥——新建API密钥——保存
此时会获得一个类似 gpustack_*********** 的密钥,注意保存,此后不会再出现
至此模型部署完成
二 前端界面部署
前端界面使用 open-webui 的开源项目
github : https://github.com/open-webui/open-webui
2.1 部署方式
2.1.1 docker(开箱即用)
docker run -d -p 3000:8080 -e WEBUI_AUTH=False -e HF_ENDPOINT=HF-Mirror -e HF_HOME={模型存放地址} --gpus all --add-host=host.docker.internal:host-gateway -v open-webui:/app/backend/data --name open-webui --restart always ghcr.io/open-webui/open-webui:cuda
(若需启动登录验证可设置 WEBUI_AUTH=True)
等待前端部署(大概需要2~5分钟不等)
ps:可通过 docker ps 查看进度,若出现 healthy,则为部署成功;若是starting则还在部署,若出现unhealthy 也不必慌乱,也许是自带的向量模型没找到位置,不影响启动,继续等待即可。
随后访问:http://localhost:3000 进行登录或直接进入界面
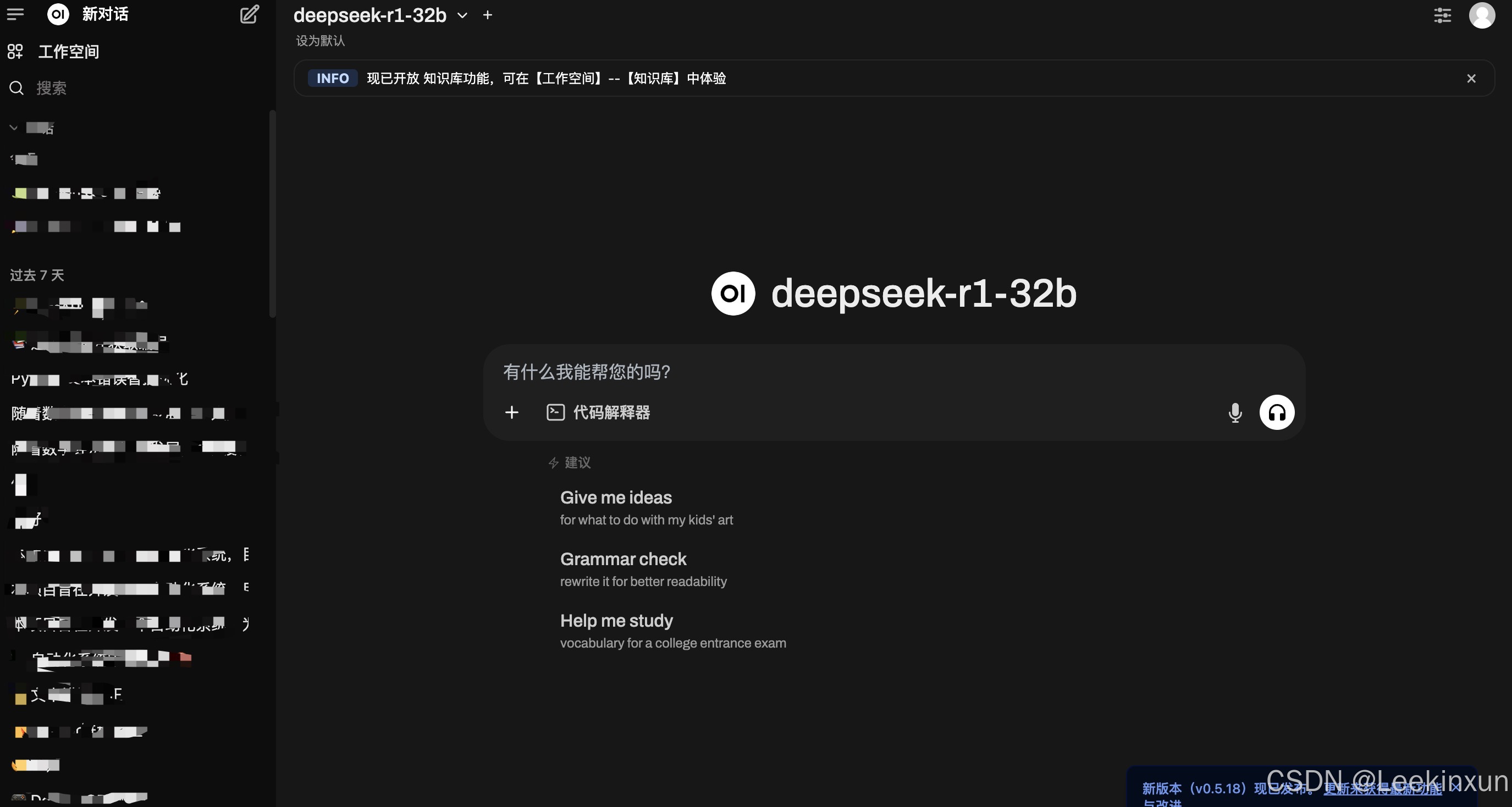
出现界面即部署成功
2.1.2 源码安装(二次开发)
1.创建虚拟环境 :
conda create -n openwebui python=3.11
2.拉取源码:
git clone https://github.com/open-webui/open-webui.git
3.配置环境变量
cd open-webui
cp .env.example .env
4.安装前端依赖:
sudo apt install nodejs npm -y
npm install -g cnpm --registry=https://registry.npmmirror.com
cnpm install
npm run build
5.安装后端依赖:
cd backend
conda activate openwebui
pip install -i https://pypi.tuna.tsinghua.edu.cn/simple -r requirements.txt -U
6.启动服务
open-webui serve
等待即可
2.2 模型对接

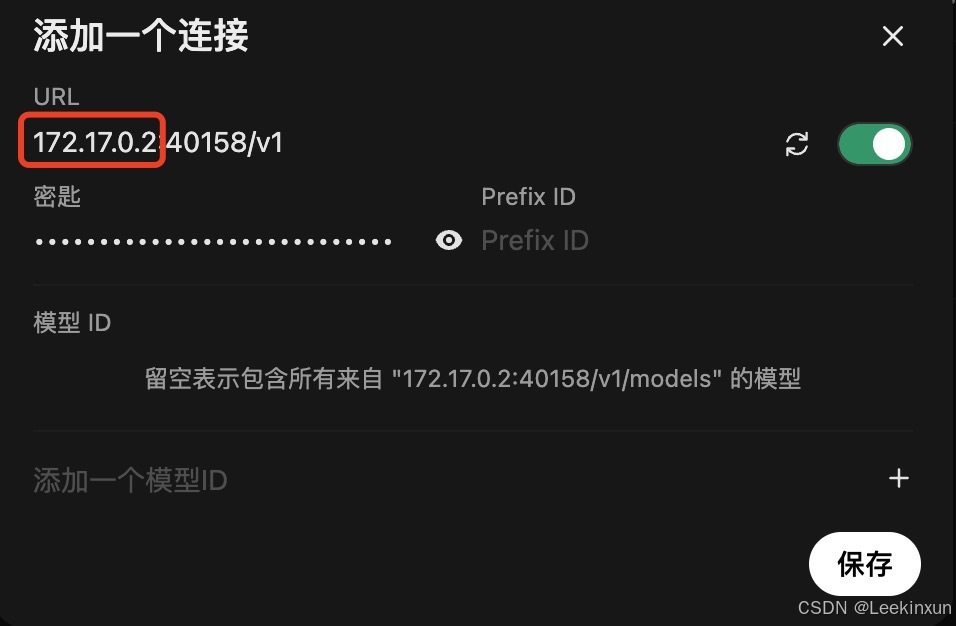
红框部分为Gpustack部署的服务器的ip地址,端口要与之前获取的一致,密钥输入gpustack_*****那串东西即可,随后点击保存。返回首页即可看到部署的模型。
至此可以开始与deepseek愉快的玩耍了
转载自CSDN-专业IT技术社区
版权声明:本文为博主原创文章,遵循 CC 4.0 BY-SA 版权协议,转载请附上原文出处链接和本声明。
原文链接:https://blog.csdn.net/Leekinxun/article/details/146010851

