
一、向量数据库简介
1、简介
向量数据库是一种专门用于存储和查询向量数据的数据库。
向量数据也就是embedding向量。
典型结构是一个一维教组,其中的元素是教值(通常是浮点数)。这些数值表示对象或数据点在多维空间中的位置、特征或属性。
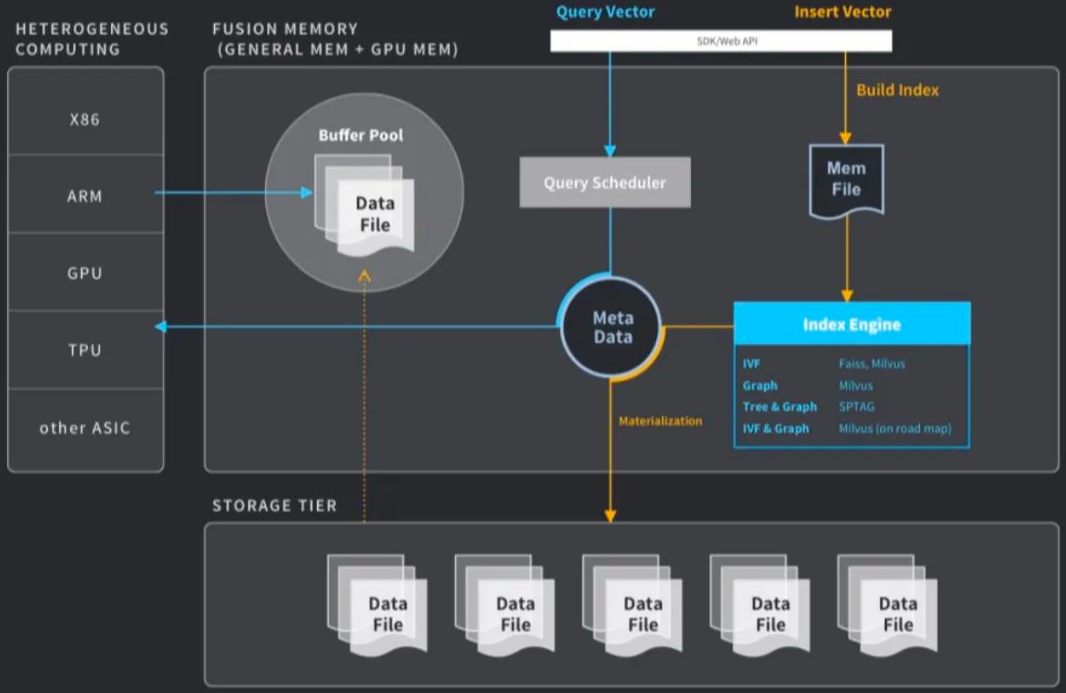
2、常用的数据向量
- 图像向量,通过深度学习模型提取的图像特征向量,这些特征向量捕捉了图像的重要信息,如颜色、形状、纹理等,可以用于图像识别、检索等任务;
- 文本向量,通过词嵌入技术如Word2Vec、BERT等生成的文本特征向量,这些向量包含了文本的语义信息,可以用于文本分类、情感分析等任务;
- 语音向量,通过声学模型从声音信号中提取的特征向量,这些向量捕捉了声音的重要特性,如音调、节奏、音色等,可以用于语音识别、声纹识别等任务。
3、向量数据库的主要功能
- 管理:向量数据库以原始数据形式处理数据,能够有效地组织和管理数据,便于AI模型应用。
- 存储:能够存储向量数据,包括各种AI模型需要使用到的高维数据。
- 检索:向量数据库特别擅长高效地检索数据,这一个特点能够确保AI模型在需要的时候快速获得所需的数据。这也是向量数据库能够在一些推荐系统或者检索系统中得到应用的重要原因。
向量数据库的主要优点是,它允许基于数据的向量距离或相似性进行快速准确的相似性搜索和检索。这意味着,可以使用向量数据库,根据其语义或上下文含义查找最相似或最相关的数据,而不是使用基于精确匹配或预定义标准查询数据库的传统方法。向量数据库可以搜索非结构化数据,但也可以处理半结构化甚至结构化数据。例如,可以使用向量数据库执行以下操作,根据视觉内容和风格查找与给定图像相似的图像,根据主题和情感查找与给定文档相似的文档,以及根据功能和评级查找与给定产品相似的产品。
4、向量数据库如何工作
向量数据库专门用于存储和查询向量数据。
假设一个图书馆就是一个数据库,而书就是数据库中的数据,在传统的教据库中,我们通过书名、作者、出版日期等关键词去搜索我们想要的书籍,这个过程类似于我们在数据库中通过关键词检索需要的数据。
在一个向是数据库中,假设读者不仅想找到一本特定的书,还想找到所有和这本书类似的书,例如内容、风格、主题都相似的书。这在传统图书馆中可能是一项极具挑战的任务,因为这需要逐一浏览和对比每一本书的内容。
在“向量“图书馆中,每本书都会被转换成一个向量,它像书的指纹,包含了书的所有特征信息。然后,我们可以通过计算这些向量之间的距离或相似度,找到与特定书最相似的其他书籍。这就是向量数据库的核心工作原理。
5、向量检索核心步骤
向量教据库的核心思想是将非结构化的文本信息转换为向量数据表示,再将转换后的向量数据以及原始文本一并存储在向量数据库。
当用户输入问题时,将问题描述转换为向量数据,在向量数据库中进行相似性计算,检索出与目标值最相似的向量以及上下文信息,最后将文本返回给用户。
下面是具体的操作流程:
1、生成并写入向量数据
向量数据可以来自各种数据源,例如文本、图像、音频等,每个向量数据都可以通过Embedding模型生成一个对应的特征表示,即向量数据。
向量数据库采用专门的数据结构和算法来存储和管理向量数据,以便快速地进行检索和分析。
2、建立向量索引
为了加速向量搜索,向量数据库通常会构建向量索引,通过计算和比较向量之间的相似度或距离,将向量数据有效地组织起来。
以便数据库快速地定位和检索与查询条件最相关的向量集合。
FLAT 索引:
将向量以列表的形式存储,不进行任何压缩或聚类。检索时,通过计算查询向量与索引中每个向量的相似度来找到最近邻,这种方法简单但效率较低,适用于数据量较小的情况。
倒排文件索引(Inverted File Index,IVF):
传统倒排索引由两部分组成:单词词典和倒排列表
单词词典:包含了文档集合中所有出现过的唯一单词,也称为词条(Term),每个词条会关联一个或多个文档ID。
倒排列表:记录了每个单词出现在哪些文档中,以及在文档中的位置信息。
IVF是一种优化的倒排索引,是一种聚类索引方法,将原始数据划分为多个簇,然后为每个簇建立倒排索引,从而加快检索速度IVF的变体索引。
包括IVF_FLAT、IVF_PQ和IVF_SQ
IVF_FLAT在聚类的基础上使用FLAT结构存储向量,适用于数据集不大且需要高精度的场景。
IVF_PQ使用乘积量化来压缩向量,以加快搜索速度并减少存储空间。
KD树索引:
KD树是一种二叉树结构,用于存储多维向是数据。它通过将向是空间划分为多个子空间,并将向量按照某种规则逐层分割,从而实现高效的向量搜索。
Ball树索引:
Ball树是一种非平衡的树结构,用于存储多维向量数据。它通过将向量空间划分为球形区域,并将向量按照某种规则逐层分割,从而实现高效的向量搜索。
HNSW 索引:
全称为 Hierarchical Navigable Small World,是一种图结构索引,通过构建分层图来组织数据。
它在每一层中将向量连接成图,查询时从高层开始,逐步下降到低层,直到找到最近邻。
HNSW在性能和召回率之间取得了良好的平衡。
局部敏感哈希(Locality Sensitive Hashing, LSH):
LSH是一种哈希技术,通过将相似的向量映射到相同的桶中来加速检索。它适用于高维稀疏向量数据。
乘积量化(Product Quantization,PQ):
PQ是一种向量压缩技术,通过将向量分割并量化来减少存储需求和提高检索速度。
3、向量搜索
在向量搜索中,用户输入一个查询向量,向量数据库通过相似性计算,会返回与查询向量最相似的向量,向量相似度通常使用余弦相似度、欧几里得距离等度量方式进行计算。
6、与传统数据库区别
向量数据库更适用于 AI运算、检索场景,数据接入效率是传统方案的10倍。
相较传统数据库具体有以下几个特点:
数据规模不同:
能够高效处理大规模数据;
对于传统数据库而言,1亿条数据已经是很大的业务流量,然而在向量数据库面向的场景中,单索引数据量可能达到千万级、甚至亿级别,单条向量数据的维度也会达到上千维。
查询方式不同:
传统数据库的查找方式都属于精确査找,而向量数据库通常是近似査找,即返回和输入内容最相近的 TOP K条数据
7、主要应用场景
RAG系统:企业知识库,行业知识库,知识沉淀等。
人脸识别:向量数据库存储大量的人脸向量数据,并通过向量索引技术实现快速的人脸识别和比对。
图像搜索:存储大量的图像向量数据,并通过向量索引技术实现高效相似度计算,返回与检索图像最相似的图像结果。
音频识别:存储大量的音频向量数据,并通过向量索引技术实现快速的音频识别和匹配。
自然语言处理:在自然语言处理(NLP)中,向量数据库通过存储文本向量并运用高效索引,极大提升文本数据的快速搜索和相似度匹配。
推荐系统:将用户行为特征向是化存储在向量数据库,当发起推荐请求时,系统会基于用户特征进行相似度计算,最终筛选用户可能感兴趣的物品推荐给用户。
数据挖掘:向量数据库可以存储大量的向量数据,并通过向量索引技术实现快速的数据挖掘和分析。
8、向量库(FAISS、HNSWLib、ANNOY)
向量数据库与向量库的区别在于,向量库主要用于存储静态数据,其中索引数据是不可变的,这是因为向量库只存储向量嵌入,而不存储生成这些向量嵌入的关联对象。
与向量数据库不同,向量库不支持CRUD(创建、读取、更新、删除)操作。
在FAISS或ANNOY等向量库中向现有索引添加新文档可能比较难做到。
HNSWLib是个例外,它有CRUD功能,同时独特地支持并发读写操作。
作为一个向量库的局限性,即不提供部署生态系统、复制实例的能力以及容错性。
二、基本原理
1、相似性测量(Similarity Measurement)
在相似性搜索中,需要计算两个向量之间的距离,然后根据距离来判断它们的相似度。
而如何计算向量在高维空间的距离呢?
有三种常见的向量相似度算法:欧几里德距离、余弦相似度和点积相似度。
(1)欧几里得距离(Euclidean Distance)
欧几里得距离(Eucidean Distance),也称为欧氏距离,是数学中最常见的距离度量方式之一,用于计算两个点在欧几里得空间中的直线距离。
在二维空间中,如果有两个点 P1(x1,y1)和 P2(x2,y2)那么它们之间的欧几里得距离 d 可以通过下面的公式计算:
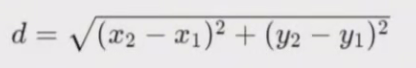
在三维空间中,如
转载自CSDN-专业IT技术社区
版权声明:本文为博主原创文章,遵循 CC 4.0 BY-SA 版权协议,转载请附上原文出处链接和本声明。
原文链接:https://blog.csdn.net/A_art_xiang/article/details/146005455

