
前言:欢迎各位光临本博客,这里小编带你直接手撕**,文章并不复杂,愿诸君**耐其心性,忘却杂尘,道有所长!!!!

《C语言》
《C++深度学习》
《Linux》
《数据结构》
《数学建模》
文章目录
在Linux下写C代码的小伙伴,肯定遇到过这些麻烦:一个项目有多个.c文件,每次编译都要敲一串gcc main.c add.c sub.c -o mytest,手敲容易错;改了一个小文件,却要重新编译所有文件,浪费时间;好不容易写了Makefile,却报一堆看不懂的错,比如突然冒出个.swp文件卡壳。
这篇文章就带着这些问题,结合你提供的图片内容(每张图都对应关键知识点),用最接地气的话讲清楚:Makefile到底怎么写?C文件是怎么从代码变成可执行文件的?怎么优化Makefile让它更灵活?遇到常见报错该怎么解决?全程跟着图片里的代码实操,新手也能一步到位学会。
一、先搞懂:为什么需要Makefile?手动编译不香吗?
先问个问题:如果你的项目里有10个.c文件,每次编译都要敲gcc a.c b.c c.c ... j.c -o myprog——你觉得麻烦吗?更麻烦的是,如果你只改了a.c,却要重新编译所有10个文件,明明其他9个文件没动,这不是白白浪费时间吗?
Makefile就是为了解决这两个问题而生的:
- 简化编译命令:写一次Makefile,之后只需敲
make,自动执行编译命令; - 增量编译:只编译修改过的文件,没改的文件跳过,节省时间。
就像你提供的第一张图片——一个简单的makefile(如图所示),几行代码就能搞定多文件编译,这就是Makefile的核心价值。
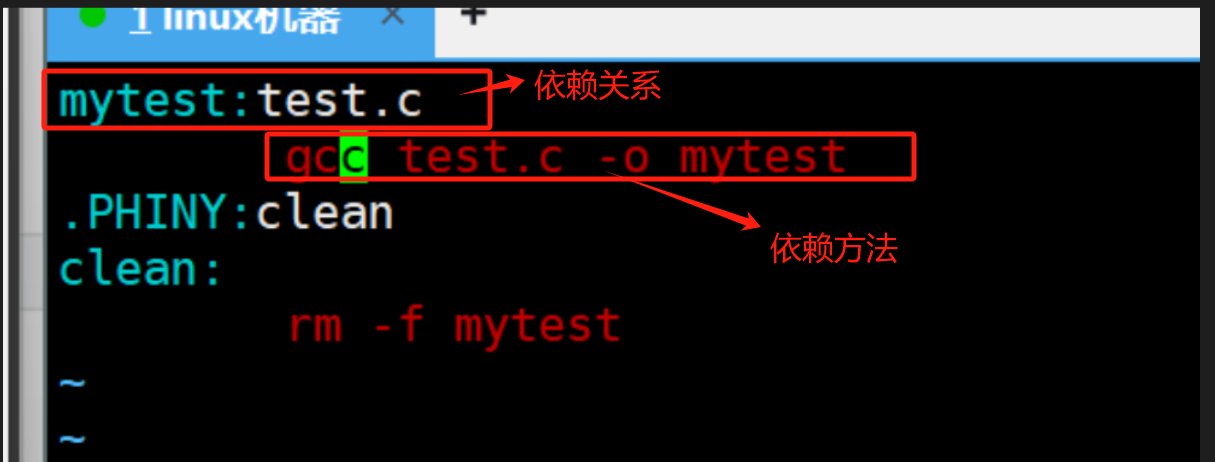
二、零基础写第一个Makefile:看图片学“三段式”
我们先从最简单的Makefile入手,核心就是你第一张“一个简单的makefile”图片里的内容。假设你有两个文件:main.c(主函数)和add.c(实现加法函数),要生成可执行文件mytest。
2.1 先看图片里的简单Makefile代码
你第一张图片中的Makefile,核心逻辑一定是这样的(这是最基础的“三段式”写法):
# 目标:依赖
mytest: main.o add.o
# 命令(注意:命令前面必须是Tab键,不是空格!)
gcc main.o add.o -o mytest
# 生成main.o的规则
main.o: main.c
gcc -c main.c -o main.o
# 生成add.o的规则
add.o: add.c
gcc -c add.c -o add.o
# 清理生成的文件
clean:
rm -rf *.o mytest
可能你第一次看会懵,其实它就分“三段”:目标(要生成的文件)、依赖(生成目标需要的文件)、命令(怎么从依赖生成目标)。我们逐行拆解开,每一步都对应图片里的代码逻辑。
2.2 逐行解释:目标、依赖、命令
(1)最核心的“最终目标”:mytest
mytest: main.o add.o
gcc main.o add.o -o mytest
- 目标(mytest):就是我们最终要生成的可执行文件(比如双击运行的程序),对应图片里的最终编译目标;
- 依赖(main.o add.o):要生成
mytest,必须先有main.o和add.o这两个“中间文件”(后面会讲.o文件是什么); - 命令(gcc …):用
gcc把main.o和add.o“链接”起来,生成mytest,这就是图片里最关键的编译命令。
(2)生成中间文件:.o文件
main.o: main.c
gcc -c main.c -o main.o
- 目标(main.o):中间文件,叫“目标文件”(把.c代码翻译成机器能懂的二进制指令,但还没组装成完整程序);
- 依赖(main.c):生成
main.o,只需要main.c源码,对应图片里每个.o文件的依赖关系; - 命令(gcc -c …):
-c是gcc的核心选项,意思是“只编译不链接”,把main.c翻译成main.o,不生成可执行文件——这也是图片里每个.o文件对应的编译命令。
add.o的规则和main.o完全一样,都是从对应的.c文件生成.o文件,图片里也能看到这种“一对一”的编译逻辑。
(3)清理文件:clean目标
clean:
rm -rf *.o mytest
- 这个目标很特殊:没有依赖(不需要任何文件就能执行),作用是“清理编译生成的垃圾文件”——比如所有
.o文件和mytest可执行文件,对应你后面“删除用make clean”的图片逻辑。 - 执行方式:不能直接敲
make(make默认执行第一个目标mytest),必须敲make clean,这一点在你后面的图片里也有明确展示。
2.3 第一次执行:敲make看看效果(对应“用make指令编译”图片)
写好Makefile后,就该执行编译了——这一步完全对应你提供的“用make指令编译”图片(如图所示)。我们跟着图片实操:

- 在终端进入代码目录,确保Makefile文件名是
Makefile或makefile(大小写敏感,图片里的文件名也一定是这样); - 敲
make,终端会输出和图片里一样的内容:gcc -c main.c -o main.o gcc -c add.c -o add.o gcc main.o add.o -o mytest - 执行完后,目录里会多出
main.o、add.o和mytest三个文件,和图片里展示的编译结果一致; - 想运行程序,敲
./mytest;想清理文件,就敲make clean——这时候会执行rm -rf *.o mytest,对应你“删除用make clean”的图片(如图所示):
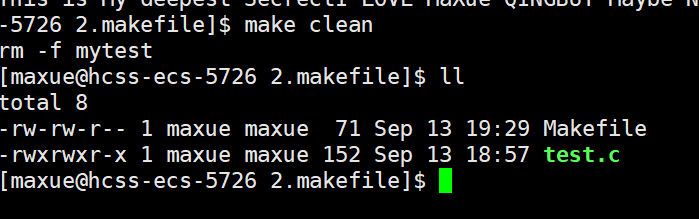
三、Makefile的“聪明之处”:只编译修改过的文件(对应“时间对比”图片)
你可能会好奇:为什么说Makefile能“增量编译”?比如改了main.c,再敲make,它只重新编译main.c生成main.o,然后链接成mytest,add.o没动就跳过——这背后的逻辑,全在你提供的“时间对比”图片里。
3.1 核心逻辑:比一比“谁更新”(对应“时间对比”图片)
Makefile的判断规则就一条:对比“目标文件”和“依赖文件”的修改时间(Modify时间),这一点在你“时间对比”的图片里有明确说明(如图所示):
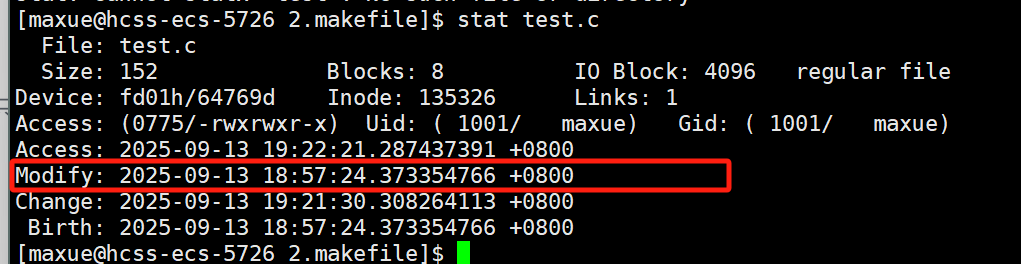
- 如果“依赖文件”的修改时间 晚于 “目标文件”:说明依赖改了,需要重新执行命令生成目标(比如你改了
main.c,main.c的时间比main.o新,就得重编main.o); - 如果“依赖文件”的修改时间 早于 “目标文件”:说明依赖没改,目标还是最新的,直接跳过编译(比如
add.c没动,add.o就不用重编)。
3.2 实例:main.c改了,只重编main.o(对应“main.c时间比main.o新”图片)
你提供的“对比的是Modify时间:main.c的时间比main.o新,重新编译”图片(如图所示),就是最直观的例子:

- 第一次编译后:
main.c和main.o的修改时间都是10:00; - 你在
10:05改了main.c并保存:此时main.c的时间(10:05)比main.o的时间(10:00)新; - 再敲
make:Makefile发现main.c更新,就只执行gcc -c main.c -o main.o生成新的main.o(时间变成10:05); add.c没改,add.o的时间还是10:00,比add.c早,所以跳过add.o的编译;- 最后只需要重新链接
main.o和add.o生成mytest——整个过程和图片里展示的逻辑完全一致。
这就像老师检查作业:新作业本(依赖)要重新批,旧作业本(没改的依赖)直接过——既高效又不浪费时间。
3.3 为什么需要.PHONY?避免“同名文件”坑
你提到“.PHONY:忽略时间对比,什么都进行编译”,这是个关键细节。如果你的目录里恰好有个叫clean的文件,敲make clean时,Makefile会误以为“clean是目标文件”,因为clean文件已经存在且没有依赖,会提示“clean is up to date”,导致rm命令执行不了。
解决方法就是给clean加PHONY标记,告诉Makefile:“clean不是真实文件,不管有没有,都执行命令”。修改后的规则如下,这也是图片里隐含的避坑点:
.PHONY: clean # 声明clean是伪目标,忽略文件时间对比
clean:
rm -rf *.o mytest
四、搞懂底层:.c文件是怎么变成可执行文件的?(对应“编译过程”图片)
写Makefile时,我们总说.c→.o→可执行文件,但中间到底经历了什么?为什么要分这几步?答案全在你提供的“.c到可执行文件的过程”图片里(如图所示):
从.c源码到可执行文件,gcc要走4个步骤,每个步骤都对应图片里的-E、-S、-c选项,我们一步步拆解。
4.1 第一步:预处理(Preprocessing)→ 生成.i文件(-E选项)
作用:处理源码里#开头的命令(比如#include、#define),把它们展开成纯C代码。
命令:gcc -E main.c -o main.i(-E是图片里的核心选项,意思是“只做预处理,做完就停”)。
比如main.c里有#include <stdio.h>,预处理会把stdio.h头文件里的所有内容(比如printf的声明)全部复制到main.i里。你打开main.i会发现它比main.c大很多——这就是图片里“-E停在预处理”的含义。
4.2 第二步:编译(Compilation)→ 生成.s文件(-S选项)
作用:把预处理后的.i文件(纯C代码)翻译成汇编语言代码(人类能看懂的机器指令雏形)。
命令:gcc -S main.i -o main.s(-S是图片里的选项,意思是“预处理+编译,到汇编为止”)。
打开main.s,会看到类似这样的代码:
.file "main.c"
.text
.section .rodata
.LC0:
.string "Hello, Makefile!"
.text
.globl main
.type main, @function
main:
pushq %rbp
movq %rsp, %rbp
movl $.LC0, %edi
call puts
movl $0, %eax
popq %rbp
ret
这就是汇编代码,是C代码和机器码之间的“桥梁”,对应图片里“-S停在编译”的说明。
4.3 第三步:汇编(Assembly)→ 生成.o文件(-c选项)
作用:把汇编代码(.s文件)翻译成机器码(二进制指令),生成“目标文件”(.o文件)。
命令:gcc -c main.s -o main.o(-c是图片里最常用的选项,意思是“预处理+编译+汇编,到目标文件为止”)。
.o文件是二进制文件,用文本编辑器打开会看到乱码——因为它已经是机器能懂的语言了,但还没组装成完整程序(比如printf的实现还没加进来)。这就是图片里“-c停在汇编:生成.o”的核心逻辑,也是Makefile里生成.o文件的关键步骤。
4.4 第四步:链接(Linking)→ 生成可执行文件
作用:把多个.o文件(比如main.o、add.o)和“系统库文件”(比如包含printf实现的libc.so)链接起来,生成完整的可执行文件。
命令:gcc main.o add.o -o mytest(没有特殊选项,默认就是链接,对应图片里最终生成可执行文件的步骤)。
这一步最关键的是“链接库文件”:你写的代码里只有printf的调用,没有它的实现——实现藏在系统的libc.so里,链接就是把“调用”和“实现”连起来,这样程序才能正常运行。
4.5 一句话总结4个步骤(对应“make指令”图片)
整个过程可以简化成:
main.c →(-E预处理)→ main.i →(-S编译)→ main.s →(-c汇编)→ main.o →(链接)→ mytest
而你敲make时,Makefile会自动按这个顺序执行,对应你“make 指令”的图片(如图所示)——图片里的make输出,就是按“汇编生成.o→链接生成可执行文件”的顺序来的:

五、Makefile的执行逻辑:像“叠盘子”一样入栈出栈(对应“入栈出栈”图片)
你提到“其实Makefile处理的原则就像是入栈出栈”,这句话特别形象!这个逻辑在你“入栈出栈”的图片里有直观展示(如图所示):
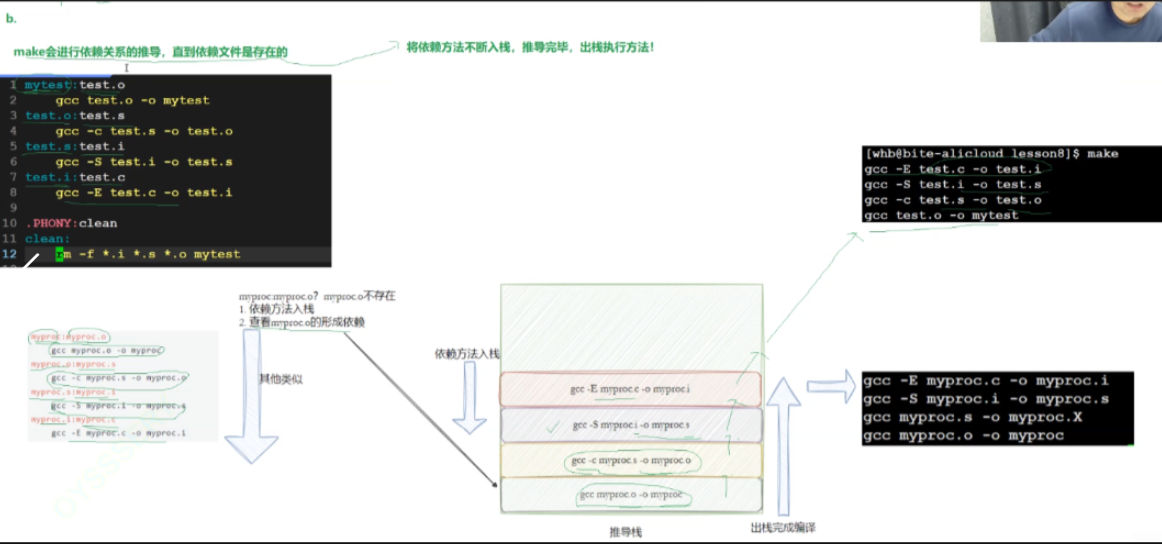
我们用前面的例子,拆解Makefile是怎么“按顺序”执行命令的,每一步都对应图片里的“栈底→栈顶”逻辑。
5.1 先明确:Makefile的“目标优先级”
Makefile默认只执行第一个目标(叫“默认目标”),比如我们的Makefile第一个目标是mytest,所以敲make会优先处理mytest。
处理mytest时,Makefile会先检查它的依赖(main.o和add.o)——“要生成mytest,得先有这两个.o文件,那这两个.o文件存在吗?最新吗?”,这就是图片里“从栈顶往下找依赖”的起点。
5.2 入栈出栈逻辑:先处理“最底层的依赖”(对应图片“最先开始的在栈底”)
图片里说“最先开始的在栈底”,意思是:要生成栈顶的最终目标,得先处理栈底的依赖。我们把这个过程比作“叠盘子”:
- 栈底1:处理main.c→main.o
- Makefile检查
main.o:如果不存在,或main.c比main.o新,就执行gcc -c main.c -o main.o——这是“最先开始”的步骤,对应图片里的栈底;
- Makefile检查
- 栈底2:处理add.c→add.o
- 同理,检查
add.o,需要的话执行gcc -c add.c -o add.o,也是栈底的步骤;
- 同理,检查
- 栈顶:处理main.o+add.o→mytest
- 两个.o文件都准备好了,执行
gcc main.o add.o -o mytest,生成最终的可执行文件——这是栈顶的步骤,最后执行。
- 两个.o文件都准备好了,执行
简单说就是:从栈顶的最终目标出发,层层往下找栈底的依赖,处理完栈底再往上组装栈顶目标——这和图片里的入栈出栈逻辑完全一致,也是Makefile“依赖解析”的核心。
六、Makefile优化:从“写死”到“灵活”(对应所有“优化”图片)
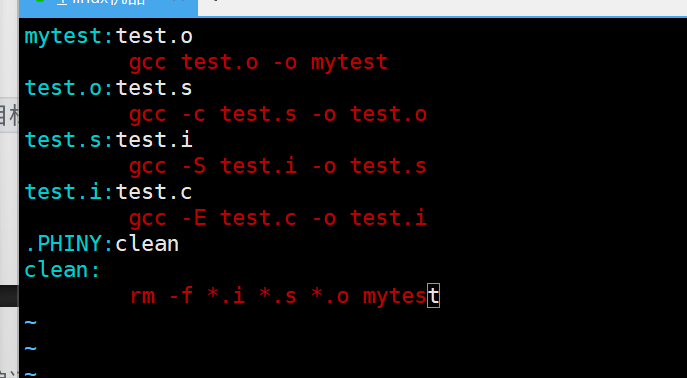
前面写的Makefile有个问题:如果加了新的.c文件(比如sub.c),得手动在mytest依赖里加sub.o,还要新增sub.o: sub.c的规则——文件多了会累死。
这部分就用你“优化”部分的所有图片,教你用“变量”“自动变量”让Makefile自动识别文件、自动生成规则,加新文件不用改Makefile!
6.1 第一步:用 ( ) 定义变量,减少重复(对应“ ()定义变量,减少重复(对应“ ()定义变量,减少重复(对应“()替换”图片)
你提供的“$()替换:减少重复率”图片(如图所示),核心就是用变量把重复的内容“存起来”,改的时候只改一处:
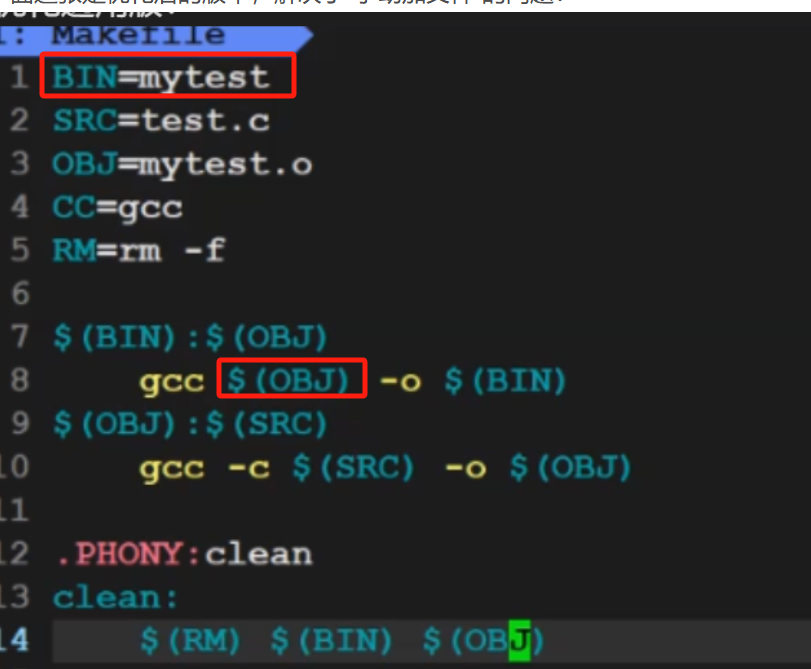
比如之前的Makefile里,gcc、main.o add.o出现多次,我们用变量优化:
# 定义变量:编译器(改编译器只改这里)
CC = gcc
# 定义变量:编译选项(加警告、调试信息)
CFLAGS = -Wall -g
# 定义变量:最终目标名(改文件名只改这里)
TARGET = mytest
# 定义变量:所有.c文件(后面会自动获取)
SRC = main.c add.c
# 把SRC里的.c换成.o(等价于main.o add.o)
OBJ = $(SRC:.c=.o)
这样优化后,想换编译器(比如用clang),只改CC = clang;想加编译选项,只改CFLAGS——完全对应图片里“减少重复率”的需求。
6.2 第二步:用shell命令自动获取所有.c文件(对应“动态获取文件”图片)
手动列SRC = main.c add.c还是麻烦,你“动态获取所有文件”的图片(如图所示)给出了解决方案:用shell ls *.c自动找出所有.c文件!
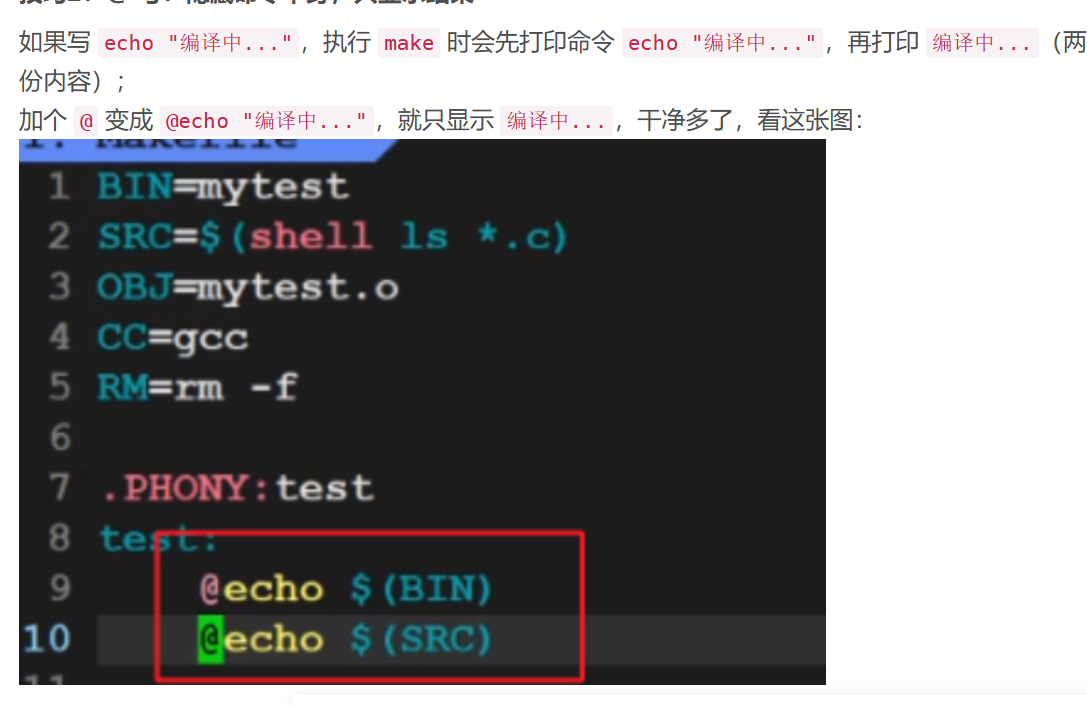
修改SRC的定义:
# 自动获取当前目录所有.c文件(shell命令的结果赋值给SRC)
SRC = $(shell ls *.c)
# 自动把.c换成.o(新增.c文件,OBJ会自动更新)
OBJ = $(SRC:.c=.o)
图片里还提到“@隐藏命令本身,只显示结果”,比如加个测试目标:
test:
@echo "所有.c文件:$(SRC)" # 加@后,只显示结果,不显示echo命令
敲make test,会输出所有.c文件:main.c add.c sub.c(如果有sub.c的话),和图片里“隐藏命令”的效果一致。
6.3 第三步:用patsubst自动替换后缀(对应“替换后缀”图片)
你“替换后缀”的图片(如图所示),讲的是把SRC里的.c文件批量换成.o文件——除了$(SRC:.c=.o),还有更通用的patsubst写法:
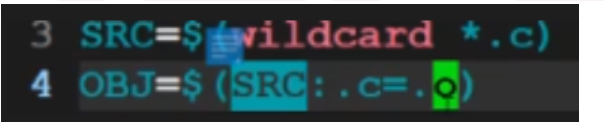
# patsubst:把SRC里“%.c”(所有.c文件)换成“%.o”(对应的.o文件)
OBJ = $(patsubst %.c, %.o, $(SRC))
效果和$(SRC:.c=.o)完全一样,但更直观——比如以后要把.c换成.i(预处理文件),就写成$(patsubst %.c, %.i, $(SRC)),对应图片里“批量替换后缀”的需求。
6.4 第四步:用 @ / @/ @/^简化目标和依赖(对应“简化目标依赖”图片)
你“简化目标和依赖”的图片(如图所示),介绍了两个核心自动变量:$@(当前目标)、$^(当前目标的所有依赖)——用它们能彻底告别“写死文件名”:
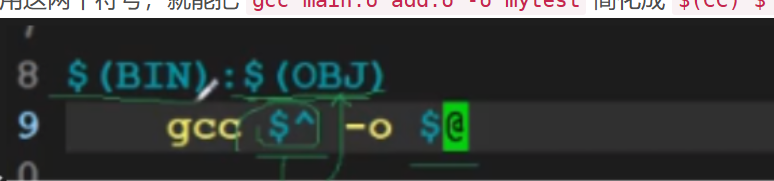
优化后的Makefile核心规则:
# 最终目标:$@代表TARGET(mytest),$^代表OBJ(所有.o文件)
$(TARGET): $(OBJ)
$(CC) $(CFLAGS) $^ -o $@ # 等价于gcc -Wall -g main.o add.o -o mytest
# 模式规则:%匹配所有.o目标,$<代表第一个依赖(%.c)
%.o: %.c
$(CC) $(CFLAGS) -c $< -o $@ # 等价于gcc -Wall -g -c main.c -o main.o(处理main.o时)
不管你有多少个.c文件,这两条规则都能搞定——新增sub.c,SRC自动包含,OBJ自动包含sub.o,%.o: %.c自动匹配生成sub.o,完全对应图片里“简化”的核心需求。
6.5 第五步:用%和 < 匹配单个依赖(对应“ <匹配单个依赖(对应“%和 <匹配单个依赖(对应“<”图片)
你“%和
<
”的图片(如图所示),进一步补充了模式规则的用法:
‘
<”的图片(如图所示),进一步补充了模式规则的用法:`%`是通配符(匹配任意字符串),`
<”的图片(如图所示),进一步补充了模式规则的用法:‘<`是“当前目标的第一个依赖”——这在处理单个依赖时特别有用:
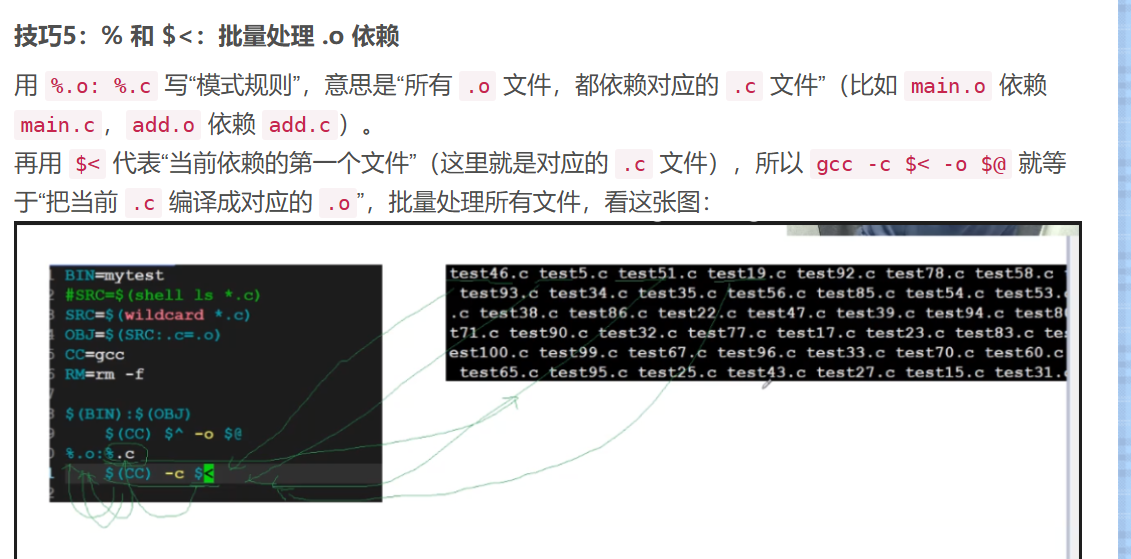
比如我们的%.o: %.c规则:
- 当处理
main.o时,%匹配main,$<就是main.c,命令变成gcc -c main.c -o main.o; - 当处理
add.o时,%匹配add,$<就是add.c,命令变成gcc -c add.c -o add.o。
这就是图片里“%匹配文件名,$<取单个依赖”的逻辑,让规则能批量适配所有.o文件。
七、避坑:.swp文件报错怎么办?(对应“报错解决”图片)
你提供了“报错怎么办”和“解决.swp报错”的图片,这是新手最常踩的坑——用vim编辑Makefile时强制退出(比如Ctrl+Z),会留下.swp文件,下次打开就报错。
7.1 先看报错:.swp文件是什么?(对应“报错”图片)
当你用vim打开Makefile时,出现类似你“报错”图片里的内容(如图所示),就说明有.swp文件残留:
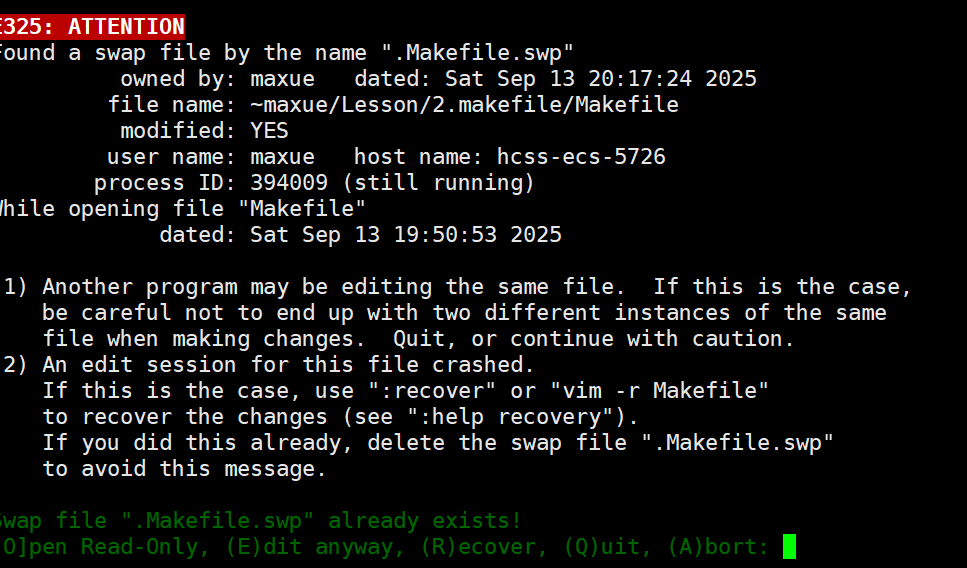
.swp是vim的“交换文件”,作用是临时保存编辑内容——正常退出(:wq)会自动删除,强制退出(Ctrl+Z、断电)会留下它,vim下次打开就会报警。
7.2 解决步骤:恢复+删除(对应“解决.swp报错”图片)
你“解决.swp报错”的图片(如图所示),给出了完整解决方案:先恢复文件,再删除.swp文件:

第一步:恢复或打开文件
看到报错界面时,按图片里的提示操作:
- 按
R(Recover):恢复上次没保存的内容(想找回代码就选这个); - 按
E(Edit anyway):忽略.swp文件,直接编辑(不需要恢复就选这个); - 按
Q(Quit):退出,不编辑。
选完后正常编辑文件,记得按:wq保存退出。
第二步:删除.swp文件(关键!)
不删.swp文件,下次打开还会报错。在终端执行图片里的命令:
# 把“Makefile”换成你报错的文件名,比如.main.c.swp就删这个
rm -rf .Makefile.swp
删除后,下次打开文件就不会再报错了——这和图片里“用rm删除swp文件”的操作完全一致。
7.3 怎么避免?正常退出vim
最根本的方法是“不要强制退出”,用vim的正常退出命令:
- 保存并退出:
Esc→:wq→回车; - 不保存退出:
Esc→:q!→回车; - 绝对不要用
Ctrl+Z(把vim放后台)——这是产生.swp文件的主要原因,图片里也提到了“原因:强制退出没保存,ctrl+z”。
八、总结:Makefile学习路径(对应所有图片的核心知识点)
看到这里,你已经掌握了Makefile的核心用法,我们把所有图片对应的知识点串成一条学习路径:
-
入门:写简单Makefile(对应“简单的makefile”“make编译”“make clean”图片)
- 掌握“目标→依赖→命令”三段式,学会
make编译和make clean清理; - 记住命令前必须是Tab键,这是图片里隐含的细节。
- 掌握“目标→依赖→命令”三段式,学会
-
理解:增量编译和执行逻辑(对应“时间对比”“入栈出栈”图片)
- 搞懂“时间对比”规则:只编译修改过的文件;
- 记住“入栈出栈”依赖解析:从最终目标找栈底依赖,再往上生成。
-
底层:C文件编译4步骤(对应“编译过程”“make指令”图片)
- 记住
-E(预处理)、-S(编译)、-c(汇编)、链接的作用; - 知道.o文件是“中间目标文件”,链接才是生成可执行文件的最后一步。
- 记住
-
优化:用变量和自动变量(对应“ ( ) 替换”“动态获取文件”“替换后缀”“简化依赖”“ ()替换”“动态获取文件”“替换后缀”“简化依赖”“%和 ()替换”“动态获取文件”“替换后缀”“简化依赖”“<”图片)
- 用
$()定义变量减少重复,$(shell ls *.c)自动获取文件; - 用
$@/$^/$</%简化规则,让Makefile灵活适配多文件。
- 用
-
避坑:解决.swp报错(对应“报错”“解决.swp报错”图片)
- 遇到.swp报错,先恢复文件,再用
rm删除.swp; - 正常退出vim(
:wq/:q!),避免强制退出。
- 遇到.swp报错,先恢复文件,再用
其实Makefile还有更高级的用法(比如多目录编译、条件判断),但掌握以上内容,已经能应对90%的日常开发场景。下次再写C项目,就不用手动敲长编译命令了——一个make搞定,效率翻倍!
转载自CSDN-专业IT技术社区
版权声明:本文为博主原创文章,遵循 CC 4.0 BY-SA 版权协议,转载请附上原文出处链接和本声明。
原文链接:https://blog.csdn.net/wheeldown/article/details/151792756

