
计算机系统原理
大作业
题 目 程序人生-Hello’s P2P
专 业 AI+先进技术领军班
学 号 2024113177
班 级 24Q0303
学 生 张天亮
指 导 教 师 史先俊
计算学部
2025年12月
本报告以Hello程序为研究对象,系统剖析其“从程序到进程”的全生命周期及“从源码到输出”的端到端流程。实验基于Ubuntu 22.04环境,借助gcc、gdb、readelf、objdump等工具,完成了Hello程序从预处理、编译、汇编到链接的静态处理过程,生成系列中间文件并解析其格式与作用;后续深入探究了程序加载为进程后的动态运行机制,包括进程创建与调度、存储地址空间映射、IO操作实现等核心环节。通过实验分析,揭示了高级语言程序通过软硬件协同转化为进程执行的内在逻辑,验证了计算机系统分层架构的设计思想。本次实验与分析清晰呈现了Hello程序从静态代码到动态执行的完整链路,深化了对计算机系统底层工作原理的理解,为后续深入学习系统开发与优化奠定了基础。
关键词:Hello程序;编译链接;进程管理;存储管理;IO机制;ELF格式
(摘要0分,缺失-1分,根据内容精彩称都酌情加分0-1分)
目 录
第1章 概述
1.1 Hello简介
Hello程序是计算机领域最基础、最经典的入门程序,核心功能是通过标准输出函数打印“Hello World”字符串,其代码简洁、逻辑清晰,却完整涵盖了高级语言程序从编写到执行的全链路核心环节,是剖析计算机系统底层工作机制的理想研究载体。
Hello程序的“P2P”过程是计算机系统程序执行的典型链路:始于Hello.c源码文件,经预处理、编译、汇编、链接四大静态处理步骤,将高级语言代码转化为可执行二进制文件;随后在Shell中执行时,操作系统通过fork创建新进程,经execve加载程序到内存,分配CPU、内存等资源并调度执行,通过IO操作输出“Hello World”结果,最终进程终止并释放资源,完成从“程序”到“进程”的完整转化。“O2O”过程则聚焦端到端逻辑:以开发者编写的C语言源码为输入,借助编译器、汇编器、链接器等工具链及操作系统的资源管理能力,最终通过显示设备输出目标结果,直观呈现了高级语言与硬件执行之间的映射关系。
1.2 环境与工具
1.2.1 硬件环境
CPU:Intel Core i9-13900HX;
内存:16GB ;
存储:1TB ;
操作系统:Windows 11 。
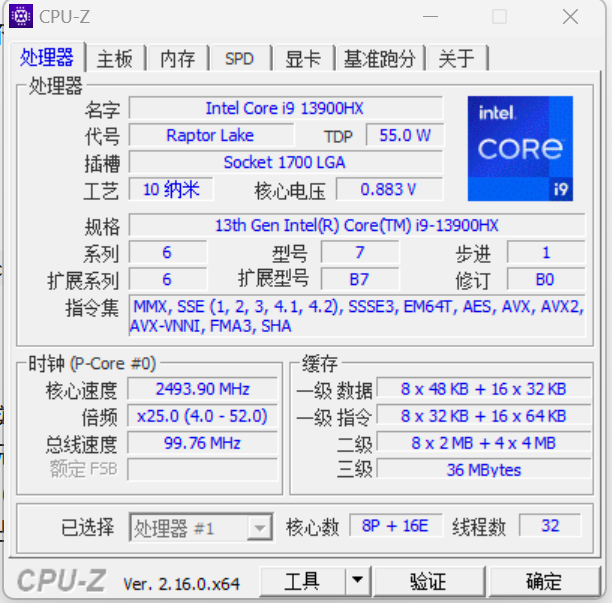
图1-1 CPUZ下CPU的基本信息
linux虚拟机系统下的配置:
CPU个数: 2 物理核数: 48 逻辑处理器个数: 96
MEM Total: 1.9Gi Used: 822Mi Swap: 2.1Gi
1.2.2 软件环境
虚拟机软件:VMware Workstation 17 Pro;
客户机操作系统:Ubuntu 22.04 LTS;
编译器套件:gcc;
调试工具:gdb(源码级调试);
ELF分析工具:objdump;
代码编辑器:Visual Studio 2022。
1.3 中间结果
1) hello.c:原始C语言源码文件,包含Hello程序的核心逻辑;
2) hello.i:预处理后的C语言文件,展开了头文件、替换了宏定义、删除了注释,为编译阶段提供标准化输入;
生成指令:gcc -E hello.c -o hello.i
3)hello.s:汇编语言文件,由编译阶段生成,将C语言代码转化为x86-64架构的汇编指令;
生成指令:gcc -S hello.i -o hello.s
4)hello.o:可重定位目标文件(ELF格式),由汇编阶段生成,包含机器码、数据及重定位信息,未解析外部符号;
生成指令:gcc -c hello.s -o hello.o
5)hello:可执行目标文件(ELF格式),由链接阶段生成,合并hello.o与系统库,解决符号重定位,可独立执行;
生成指令:gcc hello.o -o hello
1.4 本章小结
本章明确了Hello程序"P2P"与"O2O"的核心流程,界定了实验研究范围;详细梳理了实验所需的软硬件环境及工具链,确保实验的可复现性;列出了实验全流程的中间产物及其核心作用。通过本章内容,读者能够建立对实验整体框架的认知,为后续章节分阶段剖析Hello程序的生命周期奠定基础。
(第1章0.5分)
第2章 预处理
2.1 预处理的概念与作用
预处理是编译器对C语言源代码进行的前期处理过程,发生在正式编译之前,本质上是一种"文本替换与代码清理"的操作。其主要功能包括:
首先,展开头文件,将#include指令指定的头文件(如stdio.h)内容完整插入到源代码的相应位置,确保编译阶段能够正确识别库函数的声明;
其次,替换宏定义,将#define定义的宏名称替换为对应的值(例如#define N 10会将源代码中所有的N替换为10),从而简化代码编写;
再次,删除注释,移除//(单行注释)和/*...*/(多行注释),减少代码冗余,避免注释对编译过程造成干扰;
最后,处理条件编译,根据#ifdef、#ifndef等指令有选择地保留代码段。
预处理阶段不进行语法分析,仅对源代码文本进行格式化处理,最终生成.i文件,为后续编译阶段提供统一格式的输入。
2.2在Ubuntu下预处理的命令
Ubuntu环境下,使用gcc编译器的-E选项执行预处理操作,核心命令为:
gcc -E hello.c -o hello.i
命令说明:-E选项指定仅执行预处理操作,不进行后续的编译、汇编、链接;-o选项指定输出文件名为hello.i,若省略则预处理结果默认输出到终端。
执行过程如下图所示:
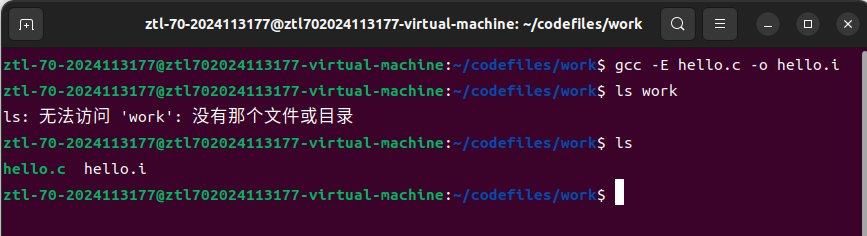
图2-1 Ubuntu下Hello程序预处理命令执行结果
2.3 Hello的预处理结果解析
打开以Hello.c的核心代码片段为例,对比预处理前后的差异,解析预处理效果:
原始Hello.c中包含#include <stdio.h>和// hello.c注释,预处理后的hello.i文件中,stdio.h头文件的全部内容(约1000余行)被完整展开,包含printf、getchar等函数的声明,如图所示;
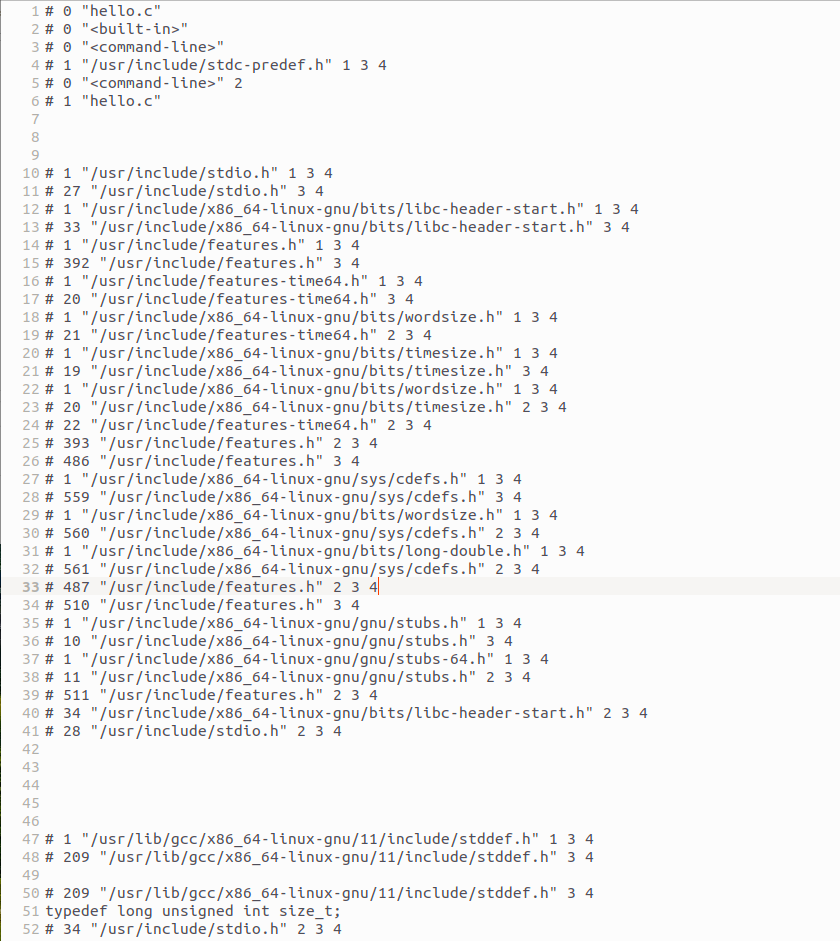
图2-2 stdio.h头文件展开部分内容截图
如图所示,源码中的注释被完全删除;若存在宏定义(如#define MSG "Hello"),则源码中所有MSG会被替换为"Hello"。hello.c仅二十几行,而hello.i文件行数为3089行,核心差异在于头文件的展开。此外,预处理后的代码不再包含预处理指令(#include、#define等),语法格式更统一,为后续编译阶段的语法分析提供了便利。
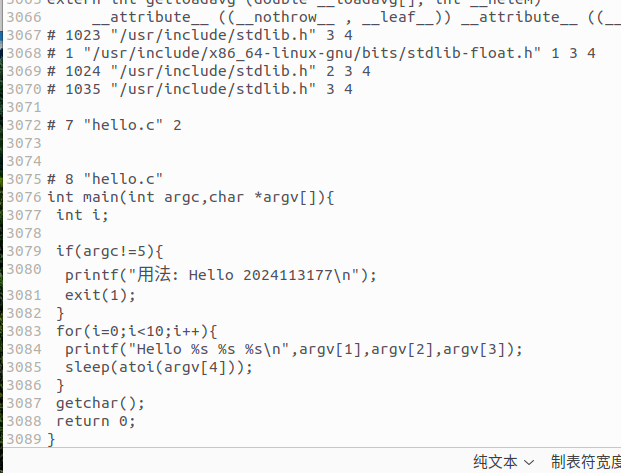
图2-3 Hello.i文件最后面内容截图
2.4 本章小结
本章阐述了预处理的概念与核心作用,明确了预处理作为“文本格式化工具”的本质;掌握了Ubuntu环境下预处理的核心命令及操作流程;通过对比分析Hello.c与hello.i文件,验证了预处理的头文件展开、宏替换、注释删除等功能。预处理阶段消除了源码中的语法差异,生成标准化的.i文件,为后续编译阶段的顺利开展提供了基础保障。
(第2章0.5分)
第3章 编译
3.1 编译的概念与作用
编译是指从预处理后的.i文件到.s汇编语言文件的转化过程,是高级语言向机器语言过渡的关键环节。其核心作用是对预处理后的C语言代码进行语法分析、语义分析,最终将C语言的抽象语法(数据类型、运算、控制结构、函数调用等)映射为特定架构(x86-64)的汇编指令。编译过程需完成词法分析(识别关键字、标识符、常量等)、语法分析、语义分析(检查类型匹配、变量未定义等错误)、中间代码生成、代码优化及目标代码生成等步骤,最终输出汇编语言程序,实现了高级语言逻辑到底层指令的初步转化。
3.2 在Ubuntu下编译的命令
Ubuntu环境下,使用gcc编译器的-S选项执行编译操作,核心命令为:
gcc -S hello.i -o hello.s
命令说明:-S选项指定仅执行编译操作,生成汇编语言文件后停止,不进行后续的汇编阶段;-o选项指定输出文件名为hello.s。若直接对hello.c执行编译,可使用命令gcc -S hello.c -o hello.s,此时gcc会自动先执行预处理再进行编译。
执行过程如图所示:

图3-1 Ubuntu下Hello程序编译命令执行结果
3.3 Hello的编译结果解析
首先配上hello.s的内容:
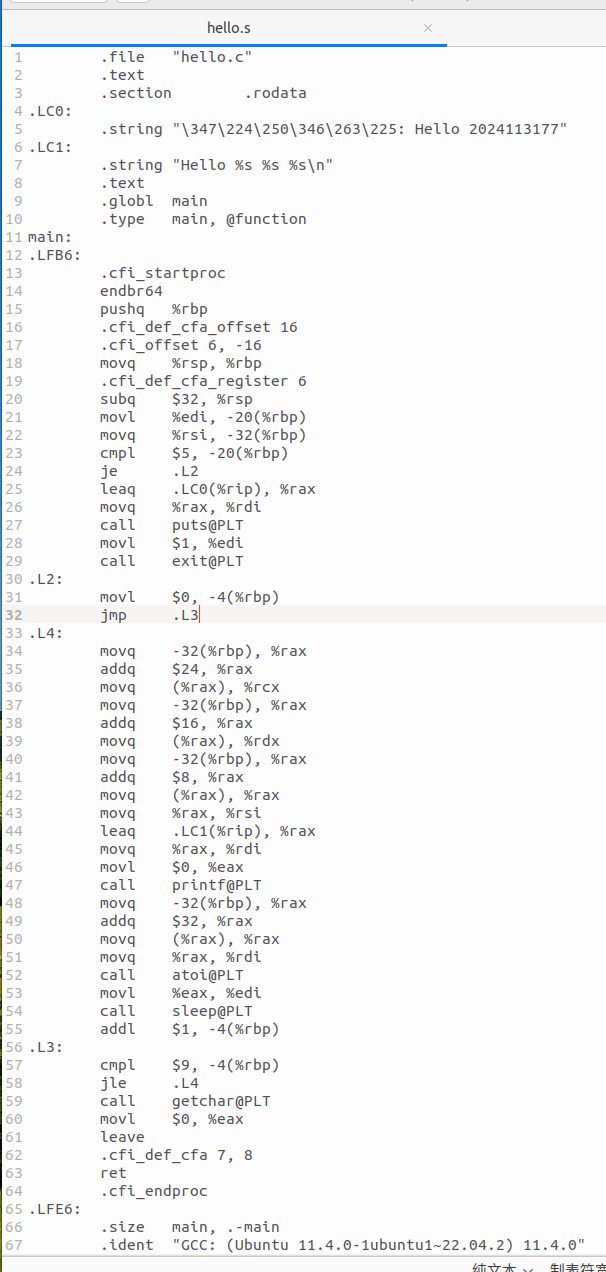
图3-2 hello.s文件内容截图
结合hello.s文件,按C语言核心语法元素分类解析编译器的转化逻辑,从数据、操作、控制、函数等方面分析,具体如下:
3.3.1 基础数据元素的转化
1. 常量
字符串常量:汇编中.LC0("\347\224\250\346\263\225: Hello 2024113177")和.LC1("Hello %s %s %s\n")存储在.rodata节(只读数据节,属于.data 节的只读子集)。
整型常量:检查参数个数的cmpl $5, -20(%rbp)中,$5是立即数嵌入指令,对应C中argc == 5的常量5;
2. 变量
局部变量:
main函数中argc被存储到栈:movl %edi, -20(%rbp);
argv被存储到栈:movq %rsi, -32(%rbp);
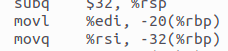
循环变量i:movl $0, -4(%rbp)。
3.3.2 赋值与类型转换的转化
1. 赋值操作
循环变量初始化movl $0, -4(%rbp):对应C中int i = 0;

函数参数传递中的赋值(如movq %rax, %rdi):本质是将寄存器值赋值给函数调用约定的参数寄存器,属于赋值操作的延伸。
2. 类型转换
汇编中call atoi@PLT:将argv[4](字符串类型)转为整型,对应C中(int)argv[4]的显式类型转换。
3.3.3 sizeof运算符的转化
编译阶段直接计算结果为立即数,如sizeof(char)=1($1)、sizeof(int)=4($4);int arr[5]的sizeof(arr)=20($20)。
本汇编代码中未直接出现sizeof运算符。
3.3.4 算术操作的转化
1. 基础运算
指针偏移计算:
addq $8, %rax(argv基地址+8字节取argv[1])、addq $16, %rax(取argv[2])、addq $24, %rax(取argv[3])。

循环变量自增addl $1, -4(%rbp)。
2. 自增自减
循环变量i的自增addl $1, -4(%rbp)。

3.3.5 逻辑与位操作的转化
1. 逻辑操作:如a&&b用testl+je实现短路求值;!a用testl+sete组合。
2. 位操作:如a&0x0F对应andl $0x0F, %eax;a>>2(有符号)对应sarl $2, %eax。3. 复合位赋值:如a&=0x0F对应andl $0x0F, -4(%rbp)。
3.3.6 关系操作的转化
相等判断:cmpl $5, -20(%rbp);对应 C 中 if (argc == 5)。

小于等于判断:cmpl $9, -4(%rbp); jle .L4:对应 C 中 i <= 9。
3.3.7 控制转移结构的转化
1. if-else
汇编中:
asm
cmpl $5, -20(%rbp)
je .L2 # argc==5则跳转到循环逻辑
leaq .LC0(%rip), %rax; call puts@PLT # else分支:打印字符串
movl $1, %edi; call exit@PLT # else分支:退出程序
.L2: # if分支:循环逻辑
对应 C 中:
if ((argc == 5) {
// 循环逻辑
} else {
puts(("您好: Hello 2024113177");
exit((1);
}
2. 循环(for)
汇编中 for 循环的完整转化:
| 汇编指令 | 对应C逻辑 | 符合的循环转化规则 |
| movl $0, -4(%rbp) | int i = 0 | 循环初始化 |
| jmp .L3 | 跳转到循环条件判断 | 循环先判断后执行 |
| .L3: cmpl $9, -4(%rbp); jle .L4 | i <= 9 | cmpl+jge/jle 实现循环条件 |
| .L4: 循环体(printf/sleep) | 循环体逻辑 | 循环体执行 |
| addl $1, -4(%rbp) | i++ | addl 实现自增 |
| 执行完后回到.L3 | jmp 条件判断 | 跳转回条件判断 |
3.3.8 数组 / 指针 操作的转化
1. 数组
movq -32(%rbp), %rax:取 argv 基地址(argv 是 char*[] 类型,存储在栈偏移 -32 处);
addq $8, %rax:argv 基地址 + 8 字节,对应 argv[1];
addq $16, %rax:对应 argv[2](2*8);
addq $24, %rax:对应 argv[3](3*8);
addq $32, %rax:对应 argv[4](4*8);
2. 指针
leaq .LC0(%rip), %rax:取字符串常量的地址;
movq (%rax), %rax:对指针解引用(如 argv[1] 是 char*,(%rax) 取指针指向的字符串)。
3.3.9 函数操作的转化
1. 参数传递
x86_64 下函数调用遵循 System V AMD64 约定,前 6 个整型/指针参数依次存 %rdi、%rsi、%rdx、%rcx、%r8、%r9。
puts 调用:leaq .LC0(%rip), %rax; movq %rax, %rdi → %rdi 传递字符串参数;
printf 调用:
leaq .LC1(%rip), %rax; movq %rax, %rdi → %rdi传递格式化字符串;
movq %rax, %rsi → %rsi传递第一个可变参数argv[1];
movq (%rax), %rdx → %rdx传递第二个可变参数argv[2];
movq (%rax), %rcx → %rcx传递第三个可变参数argv[3];
exit调用:movl $1, %edi → %rdi传递退出码 1;
atoi调用:movq %rax, %rdi → %rdi传递argv[4]字符串;
sleep调用:movl %eax, %edi → %rdi传递atoi转换后的整型值。
2. 函数调用
call puts@PLT/call printf@PLT/call exit@PLT等:均为call指令调用函数,
3. 栈帧管理
函数入口:
pushq %rbp # 保存旧的rbp
movq %rsp, %rbp # 新rbp指向当前rsp,建立栈帧
subq $32, %rsp # 分配32字节栈空间(局部变量)
函数返回:
leave # 等价于movq %rbp, %rsp + popq %rbp
ret # 弹出返回地址,跳转返回
4. 返回值
movl $0, %eax:main函数返回0;
其他函数(如atoi)的返回值:call atoi@PLT后返回值存%eax,再传递给sleep
3.4 本章小结
本章明确了编译阶段的核心定位——实现高级语言到汇编指令的映射;掌握了Ubuntu环境下编译的核心命令;重点分析了编译器对C语言各类数据类型及操作的转化逻辑,揭示了高级语言抽象语法与底层汇编指令的对应关系。编译阶段通过多步语法、语义分析及代码优化,生成了可被汇编器识别的汇编程序,为后续汇编阶段生成机器码奠定了基础。
(第3章2分)
第4章 汇编
4.1 汇编的概念与作用
汇编是指从.s汇编语言文件到.o可重定位目标文件的转化过程,本质是“汇编指令到机器码”的翻译过程。其核心作用是将汇编语言编写的指令序列,逐行翻译为对应架构的二进制机器码(如x86-64架构的机器码为1-15字节不等),同时生成ELF格式的可重定位目标文件。该文件包含代码段(.text,存储机器码)、数据段(.data,存储已初始化数据)、重定位信息段(.rel.text、.rel.data,存储未解析的外部符号信息)、符号表(.symtab,存储变量、函数名及对应地址)等。汇编阶段不解决外部符号引用(如printf函数),仅完成汇编指令到机器码的直接映射,生成的.o文件需经链接阶段处理后才能执行。
4.2 在Ubuntu下汇编的命令
Ubuntu环境下,使用gcc编译器的-c选项执行汇编操作,核心命令为:
gcc -c hello.s -o hello.o
命令说明:-c选项指定仅执行汇编操作,生成可重定位目标文件后停止,不进行后续的链接阶段;-o选项指定输出文件名为hello.o。若直接对hello.c执行汇编,可使用命令gcc -c hello.c -o hello.o,此时gcc会自动依次执行预处理、编译、汇编三个阶段。
执行过程:
图4-1 Ubuntu下Hello程序汇编命令执行结果
4.3 可重定位目标elf格式
使用readelf -a hello.o命令分析hello.o的ELF格式,结果如下:
1.ELF头:
ELF头(ELF header)作为ELF格式文件的核心元数据结构,以16字节的固定长度标识序列起始,该序列精准定义了文件所属系统的字长(32/64位)与字节序(小端/大端模式)。ELF头后续字段则承载了链接器解析目标文件的关键信息,包括ELF头自身的字节大小、目标文件的功能类型(可重定位文件、可执行文件或共享库)、目标架构的机器类型(如x86-64)、节头部表在文件中的偏移地址,以及节头部表的条目尺寸与总数量。值得注意的是,目标文件中各节的物理位置与内存大小均由节头部表统一描述,表内每个条目对应一个节,且所有条目保持固定的字节长度。
ELF头展示如下:
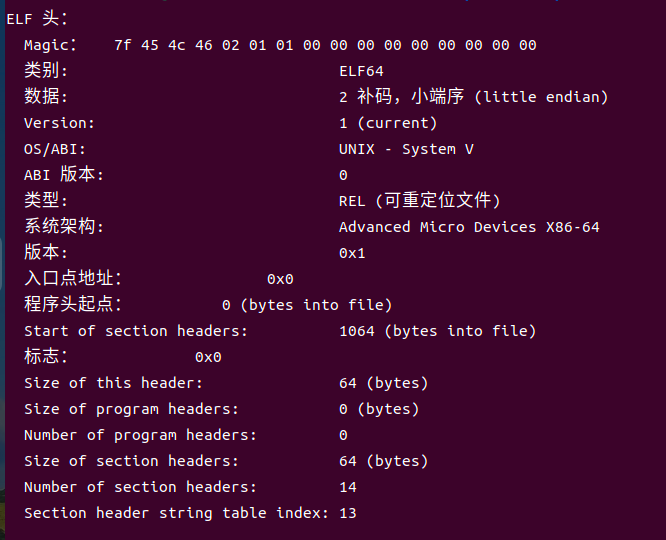
图4-2:ELF头截图
节区表(Section Header Table)记录了文件中所有节的属性信息,包括各节的名称、类型、大小、在文件中的偏移量、读写权限标志及对齐方式。每个节区表条目固定占用40字节,包含节名称字符串表索引、节地址对齐要求及链接时所需的重定位信息标记。
通过readelf -a hello.o命令可查看.text、.data、.bss、.rodata等节的具体信息,其中.text节包含编译生成的机器指令,.data节存储已初始化的全局和静态变量,.bss节预留未初始化变量的内存空间,.rodata节存放只读数据如字符串常量。节区表还指明各节在内存中的对齐策略,确保访问效率与系统兼容性。通过对节区表的解析,链接器能够准确定位代码与数据位置,完成符号解析与重定位计算,为后续的链接过程奠定基础。
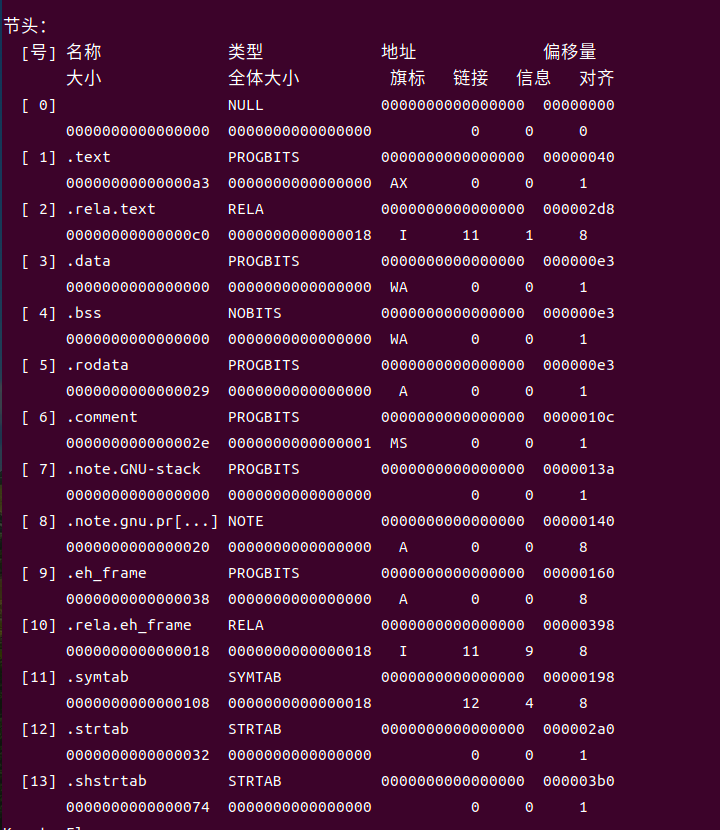
图4-3:节区表截图
3.重定位信息:
重定位信息是ELF文件实现符号动态解析的核心机制,其本质是记录程序中未决外部符号(如跨模块函数、全局变量)的位置标记与修正规则。在编译阶段,编译器仅能确定符号的相对引用关系,无法预知其最终内存地址,因此会在目标文件中插入重定位条目,详细标注符号所在的代码/数据偏移、符号类型及修正方式。当程序进行链接(静态/动态)或加载时,链接器/加载器会依据这些重定位信息,将符号引用替换为实际内存地址,最终完成程序的地址空间绑定,确保跨模块资源访问的正确性。
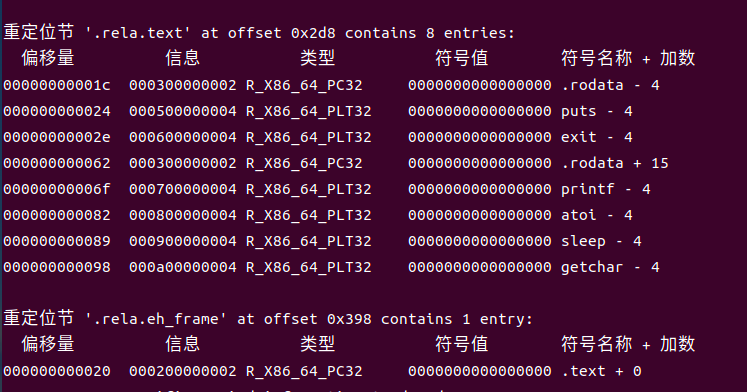
图4-4:重定位表截图
4.符号表:
符号表是程序调试与链接过程中的核心元数据结构,它系统记录了程序内所有函数、变量等符号的名称、内存地址、数据类型及作用域等关键信息。作为调试器、链接器等开发工具的"程序地图",符号表为工具解析程序内部结构提供了精准依据,使其能够高效定位和操作各类符号。例如,调试器可通过符号表快速匹配函数名称与对应内存地址,从而在调试时便捷地设置断点、追踪函数调用流程或查看变量实时值;链接器则依赖符号表完成跨模块符号的解析与地址绑定,确保程序各部分能正确协同工作。
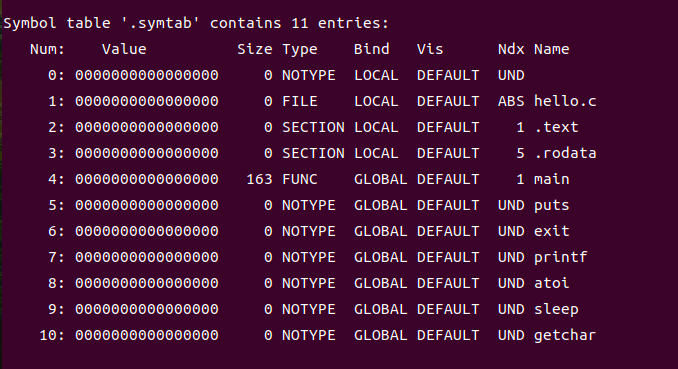
图4-5:符号表截图
4.4 Hello.o的结果解析通过对hello.o文件的深入解析,
使用objdump -d -r hello.o命令对hello.o进行反汇编,对比第3章的hello.s文件,分析结果如下:
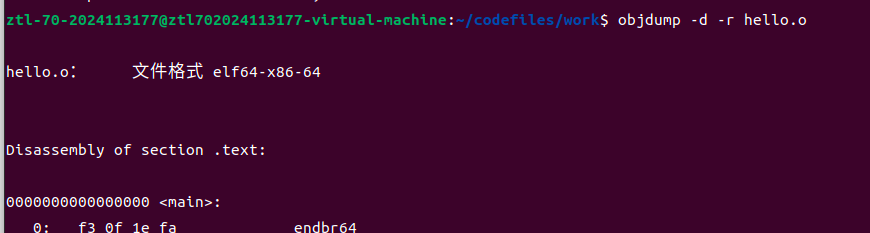
图4-6:反汇编命令执行
1. 机器语言与汇编语言的基本映射
机器语言是 CPU 可直接执行的二进制指令序列(十六进制编码形式),汇编语言是其符号化表示,二者为一一对应的硬映射关系,核心映射示例及说明如下:


映射核心逻辑:汇编助记符(如pushq/movq)与机器码操作码一一对应,寄存器、立即数、本地内存偏移等操作数在机器码中以二进制编码形式存在,汇编仅做符号化替换,未改变底层逻辑。
2. 分支转移的差异
分支转移的核心差异是 “汇编用符号标签标记目标,机器码用相对偏移量编码目标”,具体代码示例及差异说明如下:
汇编语言代码:

机器语言代码:

差异说明:
汇编层面:通过.L2/.L3/.L4等符号标签直观标记分支目标,无需计算地址偏移,提升可读性;
机器码层面:无符号概念,分支操作数是 “相对于当前指令指针 rip 的字节偏移量”,偏移量由汇编器自动计算并编码为二进制数值。
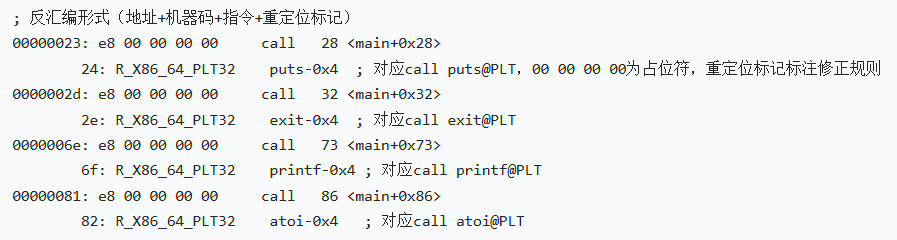
3. 函数调用的差异
函数调用的核心差异是 “汇编用符号表示调用目标,机器码用占位符 + 重定位标记暂存目标”,具体代码示例及差异说明如下:
汇编语言代码:

机器语言代码:
差异说明:
汇编层面:用puts@PLT/printf@PLT等符号直接指向外部函数,无需关注地址细节;
机器码层面:因外部函数最终内存地址未确定,调用操作数用00 00 00 00作为占位符,同时通过重定位标记(如R_X86_64_PLT32 puts-0x4)记录链接时的修正规则,链接阶段会将占位符替换为函数的实际 rip 相对偏移地址。
4. 操作数处理的差异
操作数处理差异分为 “本地确定操作数” 和 “外部未确定操作数” 两类,核心差异是外部操作数在汇编中用符号表示,在机器码中用占位符 + 重定位标记表示,具体代码示例如下:
类别 1:本地确定操作数
汇编语言代码:
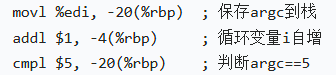
机器语言代码:

类别 2:外部未确定操作
汇编语言代码:

机器语言代码:

差异说明
本地确定操作数:汇编与机器码仅表现形式不同,操作数逻辑完全一致;
外部未确定操作数:汇编用.LC0/puts@PLT等符号简化地址管理,机器码因地址未确定,用00 00 00 00作为占位符,并通过重定位标记标注链接时的地址修正规则。
4.5 本章小结
本章阐明了汇编阶段的核心功能——将汇编指令翻译为机器码并生成ELF格式可重定位目标文件;掌握了Ubuntu环境下汇编的核心命令;深入解析了ELF可重定位目标文件的结构,明确了各关键节的作用;通过反汇编对比,验证了机器码与汇编指令的一一映射关系,分析了重定位项的存在意义。汇编阶段完成了从符号化汇编指令到二进制机器码的转化,生成的hello.o文件虽包含完整的代码和数据,但因未解决外部符号引用,无法直接执行,为后续链接阶段的符号解析和地址重定位提供了基础。
(第4章1分)
第5章 链接
5.1 链接的概念与作用
链接是将一个或多个可重定位目标文件(如hello.o)与系统库(如C标准库libc.so)合并,生成可执行目标文件的过程。其核心作用包括:一是符号解析,查找并绑定目标文件中未定义的符号,将其与库文件中的对应符号关联;二是重定位,根据符号的最终地址,调整目标文件中引用该符号的指令地址,填充占位符,使代码能正确访问外部函数和变量。链接分为静态链接和动态链接:静态链接将库文件的代码完整复制到可执行文件中,生成的文件体积较大但不依赖外部库;动态链接仅在可执行文件中记录库文件的引用信息,运行时由动态链接器加载库文件并完成重定位,实现库的共享复用,减少文件体积。Hello程序采用动态链接方式,依赖libc.so库中的printf函数。
5.2 在Ubuntu下链接的命令
Ubuntu环境下,可使用ld命令直接链接,也可通过gcc间接链接(gcc内部调用ld)。核心命令如下:
ld hello.o -lc -dynamic-linker /lib64/ld-linux-x86-64.so.2 -o hello
命令说明:-lc指定链接C标准库;-dynamic-linker指定动态链接器路径(x86-64架构默认路径为/lib64/ld-linux-x86-64.so.2);-o指定输出可执行文件名为hello。
链接过程截图:

图5-1 Ubuntu下Hello程序链接及运行结果
5.3 可执行目标文件hello的格式
使用readelf -a hello命令分析可执行目标文件的ELF格式,结果如下:
1. ELF头部:文件类型为EXEC(可执行文件),架构为x86-64,入口地址为0x4010d0,指定了程序头表和节表的偏移量及大小。ELF头起始于一个16字节的序列,此序列用于描述生成该文件的系统的字大小与字节顺序。ELF头的其余部分包含辅助链接器进行语法分析和目标文件解释的信息,如ELF头的尺寸、目标文件的类别、机器类型、节头部表的文件偏移量,以及节头部表里条目的尺寸与数目。各节的位置与大小由节头部表来描述,目标文件中的每个节在节头部表中都有一个固定尺寸的条目。
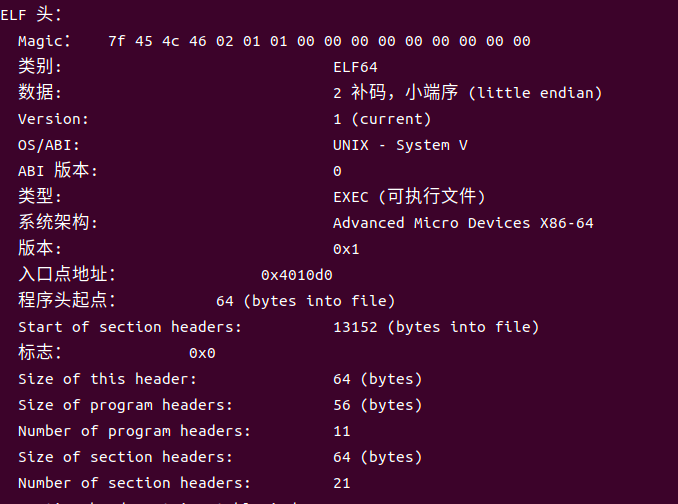
图5-2可执行文件hello的ELF头.
2.程序头表:包含多个LOAD段(可加载到内存的段),分为代码段(可读可执行)和数据段(可读可写),每个LOAD段指定了虚拟地址、物理地址、文件大小、内存大小等信息,内核加载程序时会根据程序头表将对应段映射到进程虚拟地址空间。
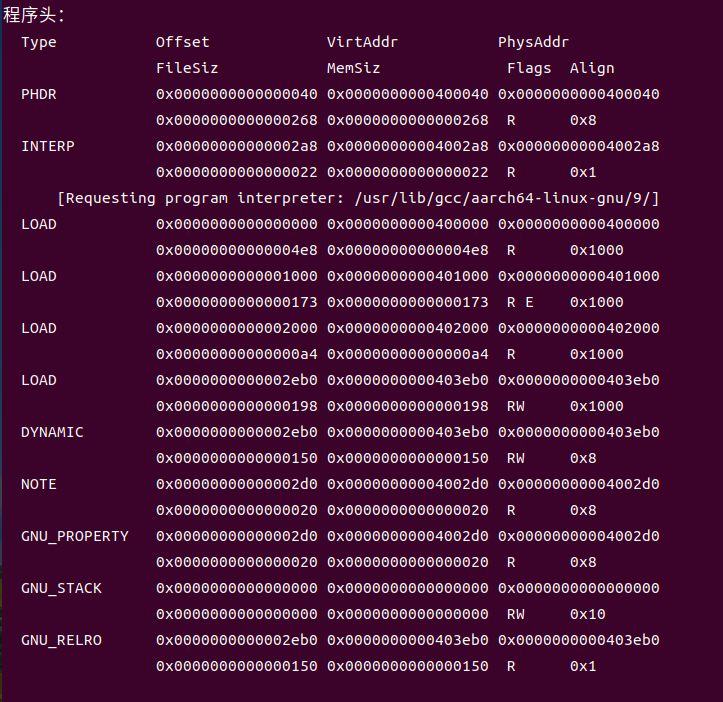
图5-3可执行文件hello的程序头表.
3.节头表:text节包含程序的机器指令,位于代码段中;.data节存储已初始化的全局变量和静态变量;.bss节用于未初始化的静态变量,在文件中不占空间,加载时由系统置零;.rodata节存放只读数据,如字符串常量;各节区内容布局严格遵循x86-64 ABI规范,确保运行时正确映射与访问。got与.plt节分别用于全局偏移表和过程链接表,支撑动态链接函数的延迟绑定机制;.symtab节包含符号表信息,.strtab节存储对应的字符串表,二者协同完成符号解析。
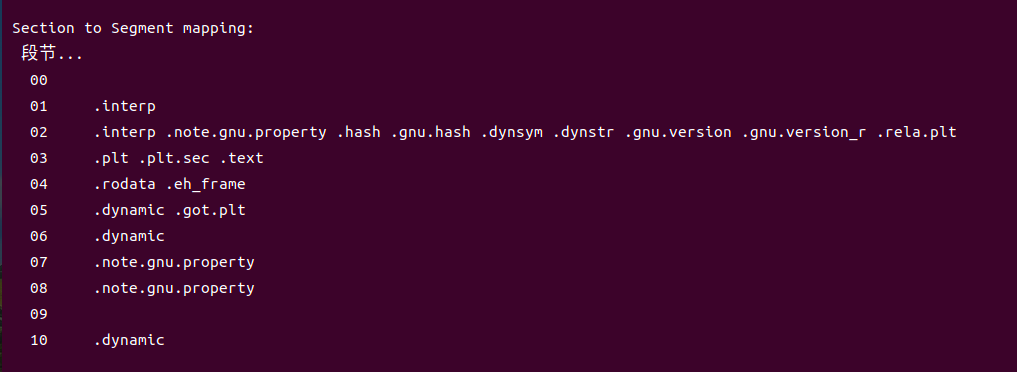
图5-4可执行文件hello的节头表.
4.重定位节:rela.text节包含.text节的重定位信息,记录了代码中需要动态链接器在加载时修正的地址引用,如调用外部函数printf的相对偏移;每个重定位条目指明了修改位置、符号索引及重定位类型,确保运行时正确解析共享库函数地址。.rela.dyn则处理数据段中的全局偏移表GOT相关重定位,支持动态链接过程中的符号绑定与地址填充,保障程序在加载时能准确访问共享库中的变量与函数。重定位机制在程序加载时由动态链接器解析,完成符号地址的最终绑定,确保程序调用外部函数或引用共享库变量时跳转到正确位置。
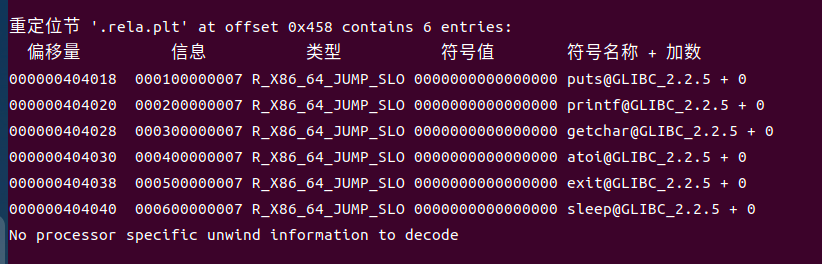
图5-5可执行文件hello的重定位节表.
5.符号表:symtab节中的符号表条目包含符号名称、值(符号对应地址或偏移)、大小、类型、绑定属性及所在节区索引,用于链接时解析全局符号引用;其中函数与全局变量符号标记为GLOBAL绑定,局部符号为LOCAL绑定,支持链接器正确合并多个目标文件。符号表与重定位表协同工作,确保外部符号在动态链接时被正确解析与修补,保障程序运行时的函数调用与数据访问一致性。
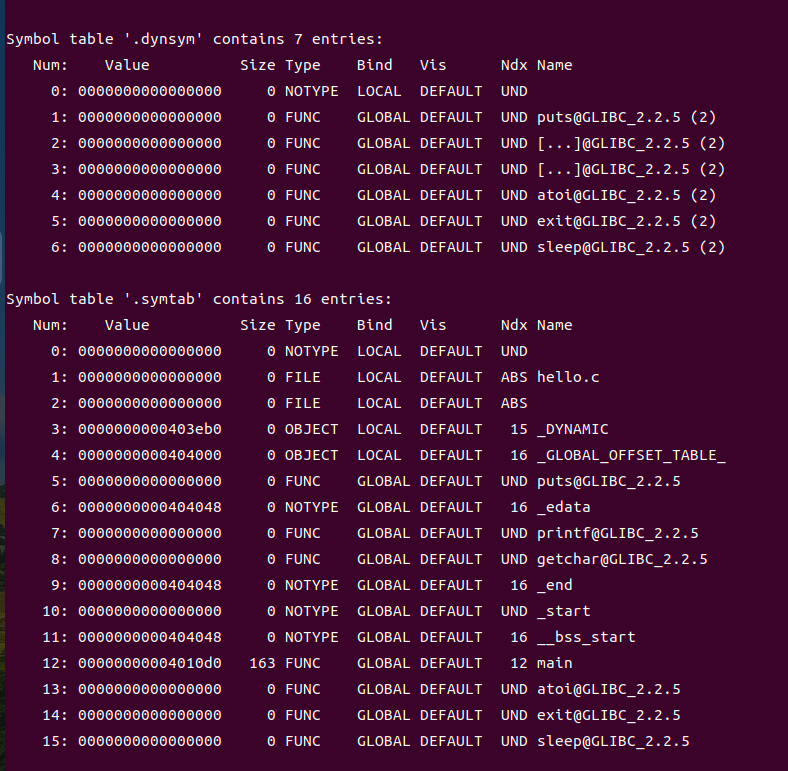
. 图5-6可执行文件hello的符号表结构.
5.4 hello的虚拟地址空间
使用gdb hello加载程序,执行info files命令查看虚拟地址空间分布,结果如下:.text段起始地址为0x00000000004010d0,.rodata段起始地址为0x00000000000402000,以此类推。虚拟地址空间的分配遵循x86-64架构规范:低地址区域为代码段、数据段,高地址区域为栈、共享库,中间为堆区域。程序头表中LOAD段的虚拟地址与info files命令显示的地址一致,验证了ELF文件格式与虚拟地址空间的映射关系。
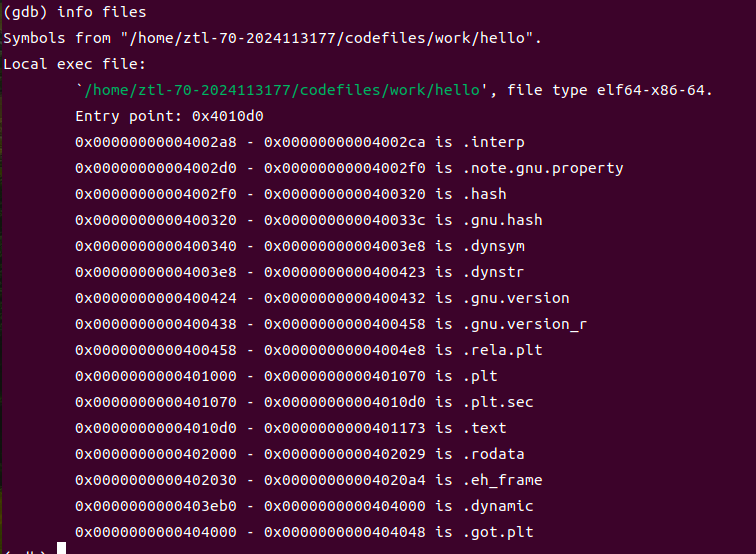
图5-7 hello程序加载后的虚拟地址空间布局.
5.5 链接的重定位过程分析
hello.o 是可重定位目标文件,仅包含业务代码指令和未解析的重定位项,指令地址以 0 为基准;hello 是可执行文件,经链接后完成地址分配、重定位修正、动态链接表构建,指令地址为绝对虚拟地址,无重定位项,可直接被系统加载执行。二者核心差异及链接过程如下:
1.核心差异对比
重定位项:hello.o 的 call 指令操作数为占位符 0x0,并附带 R_X86_64_PLT32 重定位标记,lea 指令(取字符串地址)也有 R_X86_64_PC32 标记;hello 中这些占位符被替换为实际偏移量,无任何重定位标记。
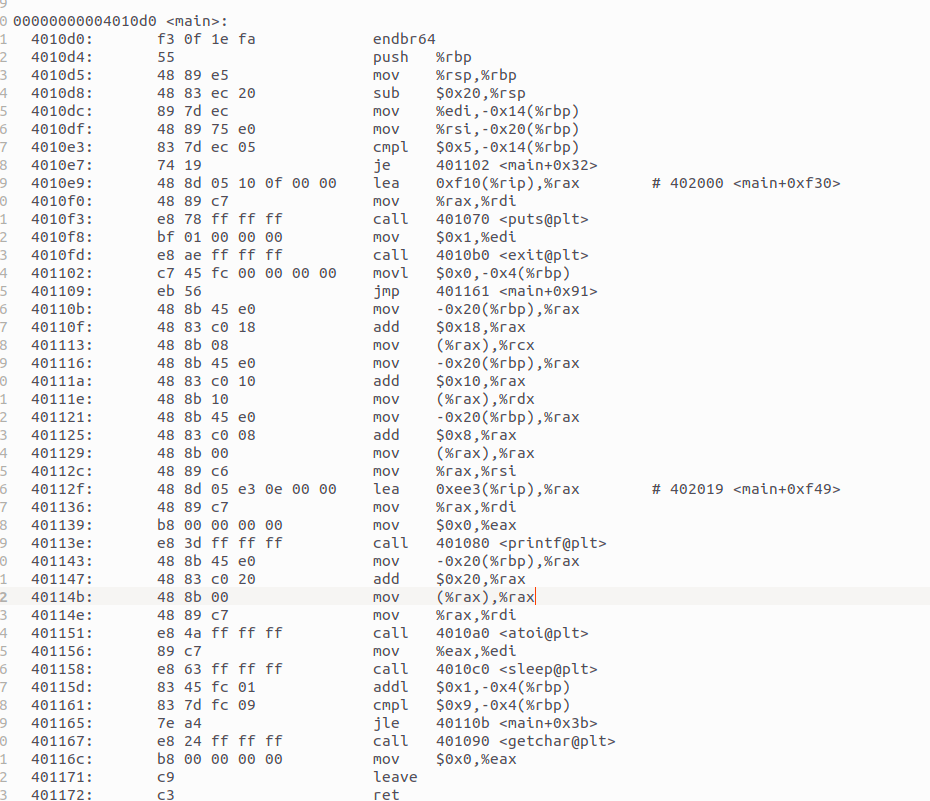
图5-8:hello.o部分反汇编代码
节区构成:hello.o 仅包含 .text/.rodata 等基础节区;hello 新增 .plt/.plt.sec 节区(动态链接过程链接表),用于外部函数的动态地址解析。
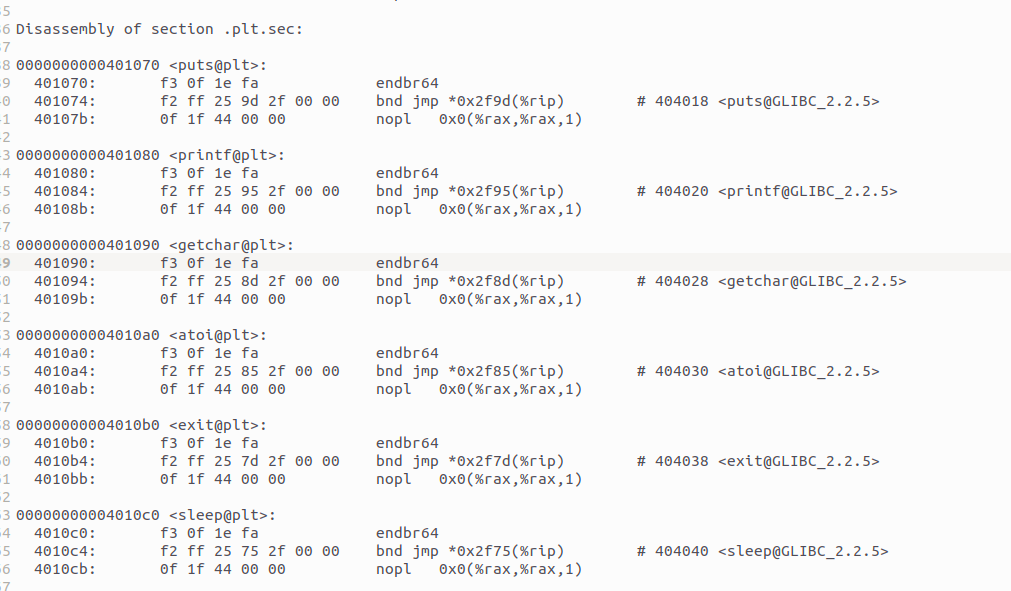
图5-9:hello相比hello.o新增的节区
2.链接过程与重定位修正逻辑
链接器核心工作:解析hello.o重定位表,修正占位符为实际地址,完成地址分配与节区合并,过程如下:
地址空间分配与节区合并:合并hello.o与CRT文件节区,分配连续虚拟地址,重算.text节分支偏移量(节内分支无需额外重定位)。
字符串地址重定位:根据R_X86_64_PC32标记,确定.rodata节字符串绝对地址,计算指令到目标地址偏移量,修正lea指令完成绑定。
外部函数调用重定位:根据R_X86_64_PLT32标记,构建PLT入口,计算call指令到PLT入口偏移量,修正指令并构建.plt表头实现延迟绑定。
动态链接表初始化:生成.plt和.plt.sec,PLT入口指向GOT;运行时动态链接器通过GOT解析libc.so函数地址完成调用。
链接本质:地址绑定与重定位修正,将hello.o转换为可执行文件,通过PLT/GOT实现外部库动态链接。
5.6 hello的执行流程
使用gdb调试跟踪hello的执行流程,步骤及结果如下:
1.执行break _start设置断点,运行程序后停在入口点_start;
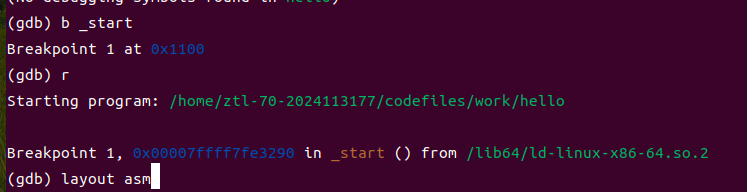
2.执行step命令跟踪,_start调用__libc_start_main函数,该函数负责初始化进程环境(设置栈、初始化全局变量等);
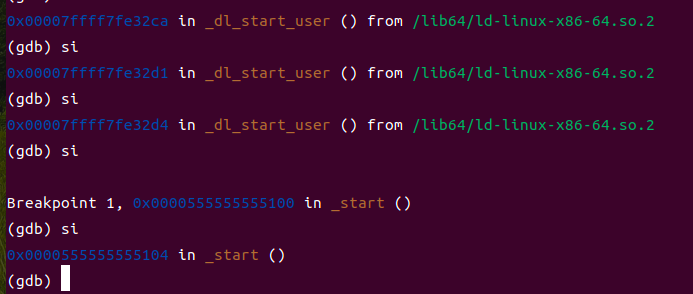
3.__libc_start_main调用main函数,程序进入用户代码逻辑,执行printf("Hello World\n");
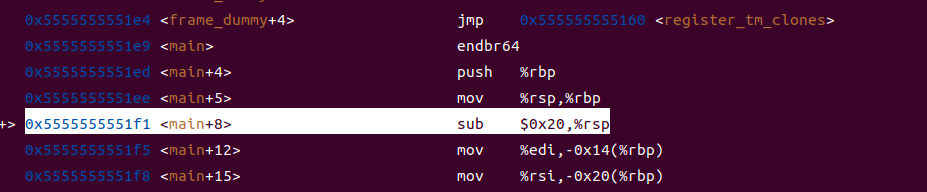
4.main函数执行完毕返回,__libc_start_main调用exit函数终止进程。关键函数调用链:_start → __libc_start_main → main → printf → exit。
5.7 Hello的动态链接分析
- 程序启动时,内核加载可执行文件和动态链接器ld-linux-x86-64.so.2;
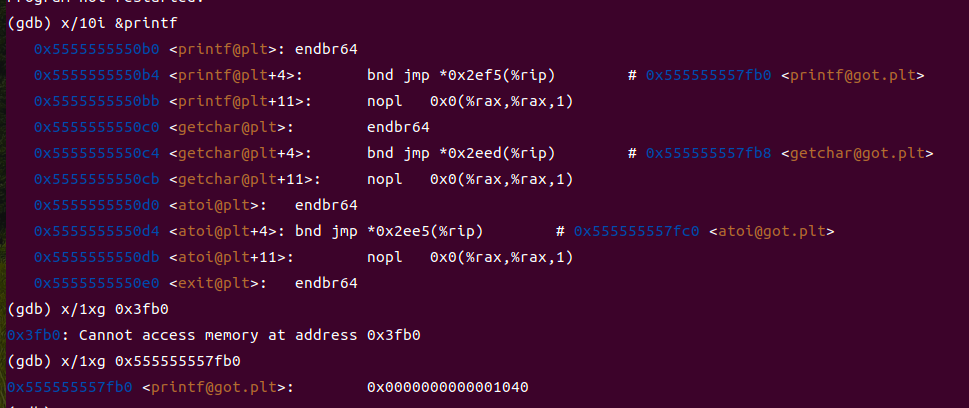
- 动态链接器解析可执行文件中的动态符号,查找libc.so.6库中的printf函数地址;
- 动态链接器完成重定位,将printf函数的真实地址填充到call指令中;
- 动态链接完成后,程序开始执行用户代码。对比动态链接前后的call printf指令地址:链接前为占位符,链接后为printf函数的真实虚拟地址。
5.8 本章小结
本章明确了链接的核心功能——符号解析与重定位,区分了静态链接与动态链接的差异;掌握了Ubuntu环境下链接的核心命令;深入解析了ELF可执行文件的格式及虚拟地址空间分布;通过反汇编对比和调试跟踪,详细分析了重定位过程、程序执行流程及动态链接机制。链接阶段将不可执行的目标文件转化为可独立运行的可执行文件,动态链接实现了库的共享复用,提升了系统资源利用率,完成了从“程序”到“可执行文件”的关键转化。
(第5章1分)
第6章 hello进程管理
6.1 进程的概念与作用
进程是程序的执行实例,是操作系统进行资源分配和调度的基本单位。其核心作用是为程序执行提供独立的运行环境,包括独立的虚拟地址空间、CPU时间片、文件描述符等资源,实现不同程序的执行隔离。程序是静态的代码和数据集合,而进程是动态的执行过程,具有生命周期。当用户执行./hello时,操作系统为Hello程序创建一个新进程,分配所需资源,调度其执行,进程终止后释放所有资源,确保其他程序的运行不受影响。
6.2 简述壳Shell-bash的作用与处理流程
Shell是用户与操作系统的交互接口,本质是命令解释器。其核心作用是解析用户输入的命令,调用对应的程序并管理其执行。处理./hello命令的流程如下:1. 读取输入:bash从标准输入读取用户输入的./hello命令;
- 解析命令:bash解析命令,识别出可执行文件为当前目录下的hello;
- 创建子进程:bash通过fork系统调用创建一个子进程;
- 执行程序:子进程通过execve系统调用加载并执行hello程序,替换子进程的代码和数据;
- 等待终止:父进程(bash)通过waitpid系统调用等待子进程终止;
- 输出结果:子进程终止后,bash输出命令执行结果(若有),并等待下一条命令输入。
6.3 Hello的fork进程创建过程
当bash执行fork系统调用创建子进程时,内核完成以下操作:
- 复制PCB(进程控制块):内核为子进程创建新的PCB,复制父进程PCB中的大部分信息(如进程状态、优先级、文件描述符表等);
- 分配进程ID:为子进程分配唯一的PID(进程标识符),与父进程的PID区分;
- 复制地址空间:采用写时复制机制,父子进程共享物理内存页,仅当某进程修改数据时,才复制该页到新的物理内存,避免创建时的大量内存复制,提升效率;
- 设置进程关系:将子进程的父进程ID设置为父进程的PID,建立父子进程关系;
- 唤醒子进程:将子进程状态设置为就绪态,放入就绪队列,等待CPU调度。fork调用返回后,父子进程同时执行,父进程继续执行bash逻辑,子进程准备执行execve加载hello。
6.4 Hello的execve过程
子进程执行execve系统调用时,内核完成以下操作:
- 解析可执行文件:内核读取hello的ELF头部,验证文件合法性,获取程序头表信息;
- 销毁旧地址空间:释放子进程原有的虚拟地址空间(继承自父进程的bash地址空间);
- 创建新地址空间:为子进程创建新的虚拟地址空间,根据ELF程序头表,将hello的.text段、.data段等映射到对应虚拟地址;
- 映射共享库:加载动态链接器,由动态链接器加载hello依赖的libc.so.6库,映射到虚拟地址空间;
- 设置程序计数器:将CPU的程序计数器(PC)设置为hello的入口地址(_start函数地址),后续CPU调度时将从该地址开始执行。execve执行完成后,子进程的地址空间完全被hello程序替换,开始执行hello的代码。
6.5 Hello的进程执行
Hello进程的执行依赖操作系统的CPU调度机制:
- 进程状态转换:子进程创建后处于就绪态,当CPU空闲时,调度器根据进程优先级选择该进程,将其状态转为运行态,分配CPU时间片;
- 执行过程:CPU按照程序计数器指向的地址依次执行指令,从_start开始,经__libc_start_main初始化后进入main函数,执行printf输出结果,main函数返回后执行exit终止;
- 调度切换:若时间片耗尽,调度器将进程状态转为就绪态,保存进程上下文(寄存器值、程序计数器等),选择其他就绪进程执行;当再次调度到该进程时,恢复上下文,从断点继续执行;
- 态转换:执行printf时需调用系统调用,进程从用户态陷入核心态,内核完成IO操作后返回用户态继续执行。
6.6 hello的异常与信号处理
hello执行过程中会出现哪几类异常,会产生哪些信号,又怎么处理的。
程序运行过程中可以按键盘,如不停乱按,包括回车,Ctrl-Z,Ctrl-C等,Ctrl-z后可以运行ps jobs pstree fg kill 等命令,请分别给出各命令及运行结截屏,说明异常与信号的处理。
6.6.1 hello执行过程中的异常类型与对应信号
hello程序运行过程中,异常主要分为用户主动触发的信号异常和程序逻辑/系统触发的异常两类,核心异常、对应信号如下表:
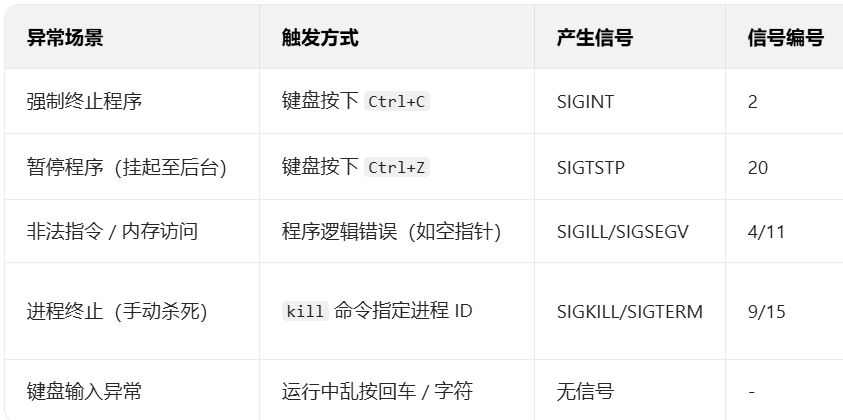
图6-1:异常类型与对应信号
6.6.2运行时按下CTRL-C
按下Ctrl-C时,终端驱动程序会向当前前台进程组发送SIGINT信号,默认行为是终止进程。hello进程接收到该信号后将结束执行,并由操作系统回收其资源。
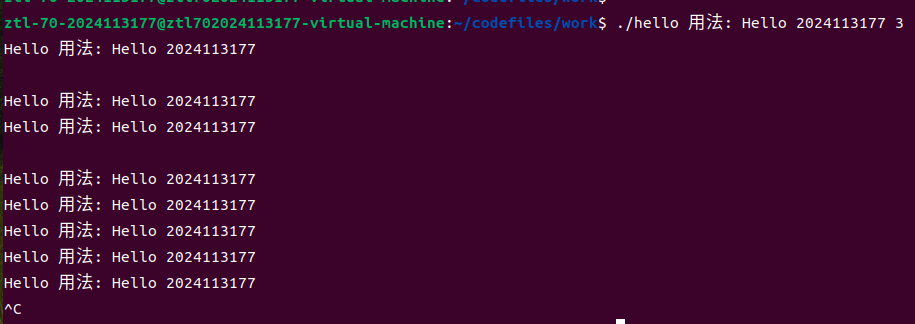
图6.-2:运行时按下Ctrl-C
6.6.3运行时按下Ctrl-Z
按下Ctrl-Z时,终端驱动程序向当前前台进程组发送SIGTSTP信号,默认行为是暂停进程。hello进程被挂起,进入停止态,其子进程也随之暂停。

图6-3:运行时按下Ctrl-Z
此时可执行ps查看进程状态,显示为“T”;

图6-4:ps命令输出结果
jobs命令可见其在作业列表中标记为已停止;

图6-5:jobs命令输出结果
pstree可观察到该进程仍存在于进程树中;
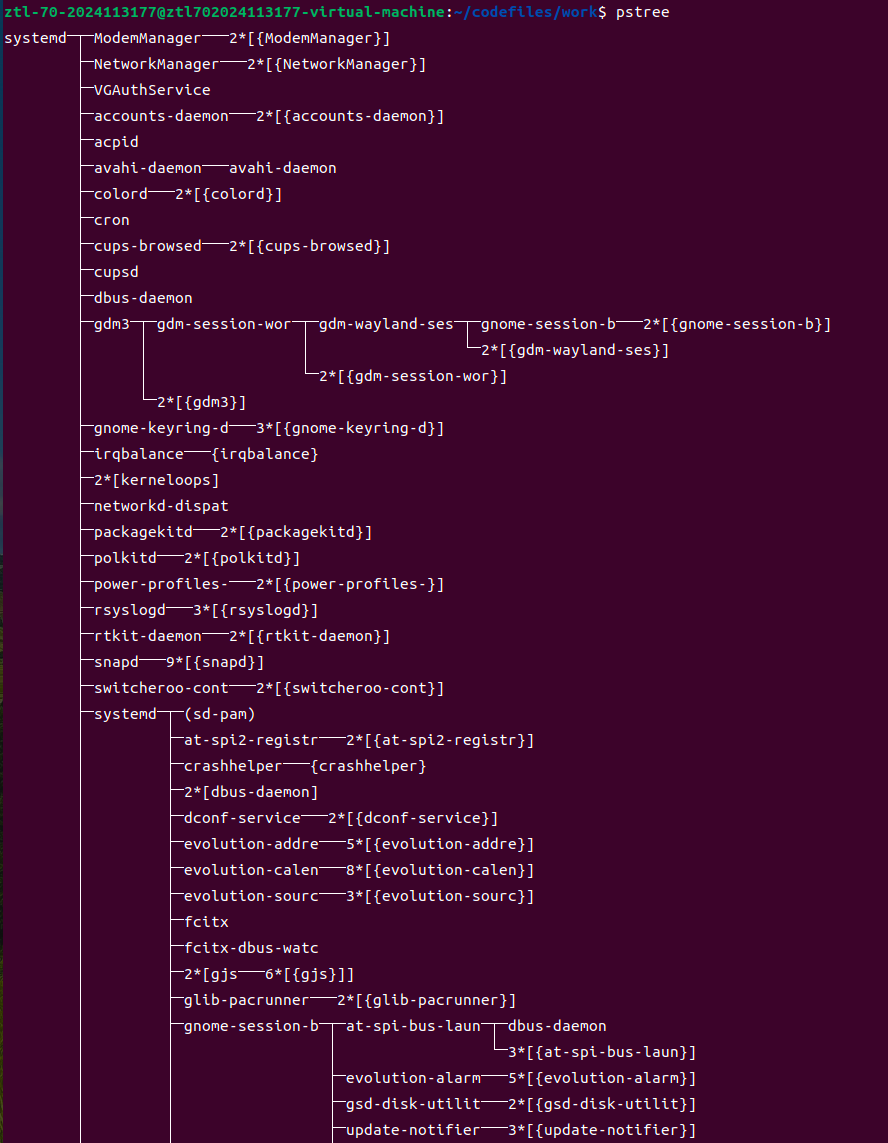
图6-6:pstree命令输出结果
通过fg命令可将其转至前台继续运行;
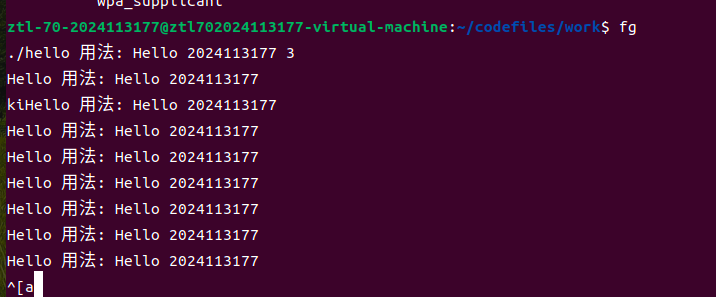
图6-7:fg命令恢复进程输出结果
使用kill发送SIGKILL信号彻底终止。系统保存其上下文,等待后续调度或显式恢复操作。

图6-8:kill命令终止进程输出结果。
6.6.4不停乱按
不停乱按时,终端驱动会将输入缓存至行缓冲区,直至回车键按下后一次性送入程序。若在标准输入读取前终止或挂起进程,则输入数据被丢弃。乱按产生的字符不会触发异常。
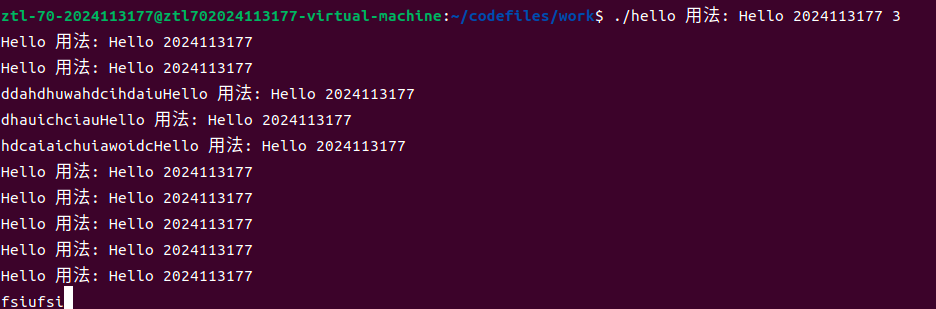
图6-9:不停乱按结果
6.7本章小结
本章阐述了进程的概念与核心作用,解析了Shell-bash的命令处理流程;详细分析了Hello进程的创建(fork)、程序加载(execve)、执行调度及异常信号处理的完整过程;验证了写时复制、进程状态转换、用户态与核心态切换等关键机制。进程管理是操作系统实现程序并发执行的核心,通过fork与execve的协同,实现了程序与进程的分离,确保了执行环境的独立性和资源的有效利用。
(第6章2分)
第7章 hello的存储管理
7.1 hello的存储器地址空间
Hello进程的存储器地址空间包含四类核心地址:
- 逻辑地址:程序代码中使用的地址(如变量&a、函数地址),是相对于程序自身的偏移地址,未经过地址转换;
- 线性地址:逻辑地址经段式管理转换后的地址,x86-64架构下逻辑地址与线性地址一致(段基址为0);
- 虚拟地址:进程视角的地址,即线性地址,进程认为自己独占虚拟地址空间,与其他进程隔离;
- 物理地址:内存硬件的真实地址,线性地址经页式管理转换后得到,是CPU访问内存的实际地址。四类地址的转化流程:逻辑地址 → 线性地址(段式转换) → 物理地址(页式转换),最终实现程序地址到物理内存地址的映射。
7.2 Intel逻辑地址到线性地址的变换-段式管理
x86-64架构下的段式管理机制简化了传统32位架构的复杂设计,核心流程如下:
1. 段选择器:段寄存器(如CS、DS)中存储段选择器,用于索引GDT(全局描述符表)或LDT(局部描述符表);
2. 段描述符:GDT中存储段描述符,包含段基址、段限长、权限等信息;x86-64架构下,用户态进程的代码段(CS)和数据段(DS)描述符的段基址均为0,段限长为2^64-1;
3. 线性地址计算:由于段基址为0,线性地址 = 段基址 + 逻辑地址(偏移量) = 逻辑地址,因此逻辑地址与线性地址完全一致。
段式管理的核心作用从地址转换转变为权限控制,确保代码段不可写、数据段不可执行,保障进程安全。
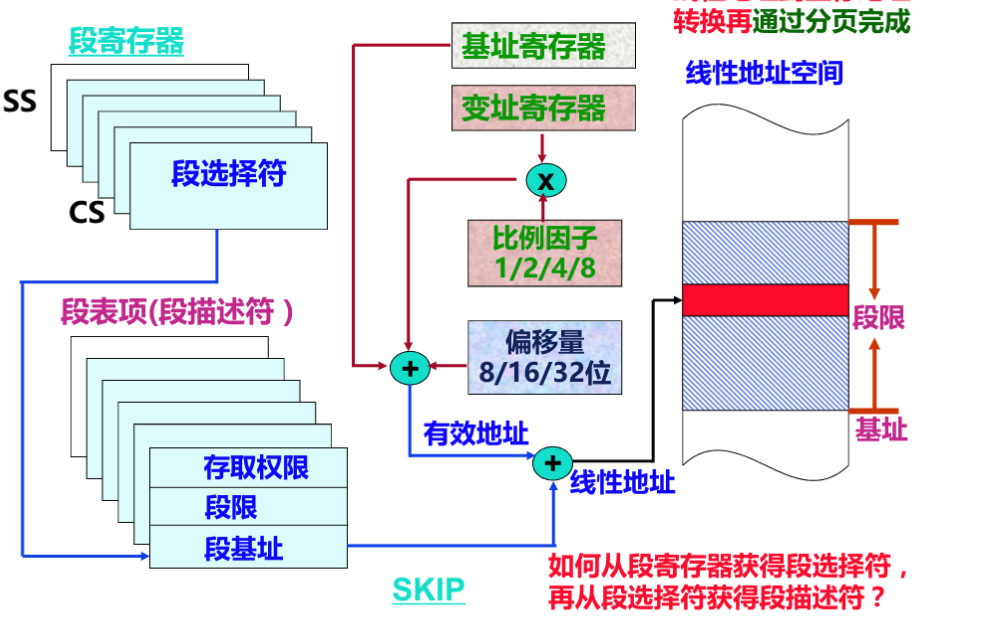
图7-1 段式管理示意图
7.3 Hello的线性地址到物理地址的变换-页式管理
x86-64架构采用四级页式管理(页全局目录、页上级目录、页中间目录、页表),将64位线性地址划分为多个部分,用于索引各级页表。核心转换流程:
- 线性地址拆分:64位线性地址拆分为页全局目录号(9位)、页上级目录号(9位)、页中间目录号(9位)、页表号(9位)、页内偏移(12位);
- 页表查找:CPU从CR3寄存器获取页全局目录的物理地址,根据页全局目录号索引到对应页全局目录项,得到页上级目录的物理地址;依次类推,通过页上级目录号、页中间目录号、页表号索引,最终得到页表项;
- 物理地址计算:页表项中存储物理页框号(40位),物理地址 = 物理页框号 << 12 + 页内偏移;
- 权限检查:各级页表项包含权限位(如可读、可写、可执行),CPU检查进程是否有权限访问该地址,无权限则触发异常。
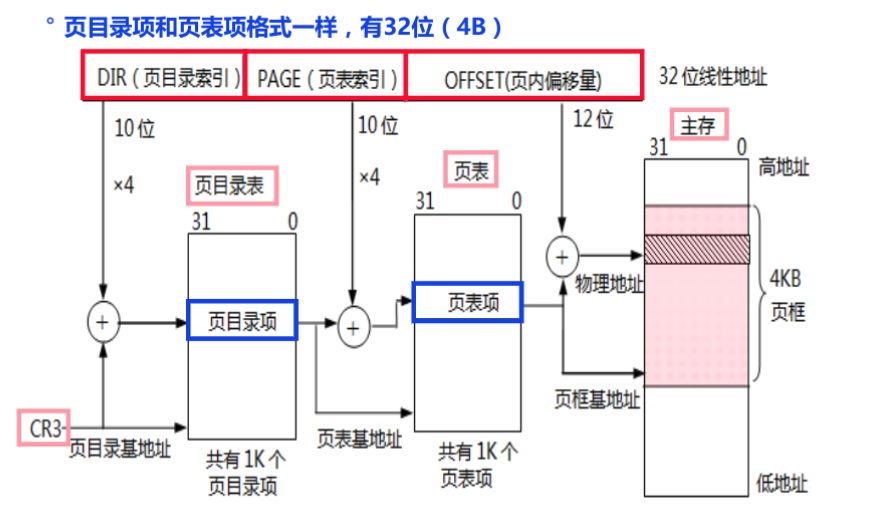
图7-2 页式管理地址转换流程示意图
7.4 TLB与四级页表支持下的VA到PA的变换
TLB(快表)是CPU中的高速缓存,用于缓存近期访问的页表项,减少四级页表的查找次数,提升地址转换效率。VA(虚拟地址)到PA(物理地址)的完整转换流程:
- TLB查找:CPU收到虚拟地址后,先查询TLB,若TLB中存在该虚拟地址对应的页表项(命中),则直接提取物理页框号,计算物理地址,无需访问内存中的四级页表;
- TLB未命中:若TLB中无对应页表项,则执行四级页表查找流程,从内存中逐级索引页表,获取物理页框号;
- TLB更新:将查找得到的页表项缓存到TLB中,覆盖近期最少使用的项,以便后续访问时快速命中;
- 物理地址生成:结合物理页框号和页内偏移,生成最终的物理地址。Hello程序执行时,频繁访问的.text段和.data段地址会被缓存到TLB,显著提升指令和数据的访问速度。
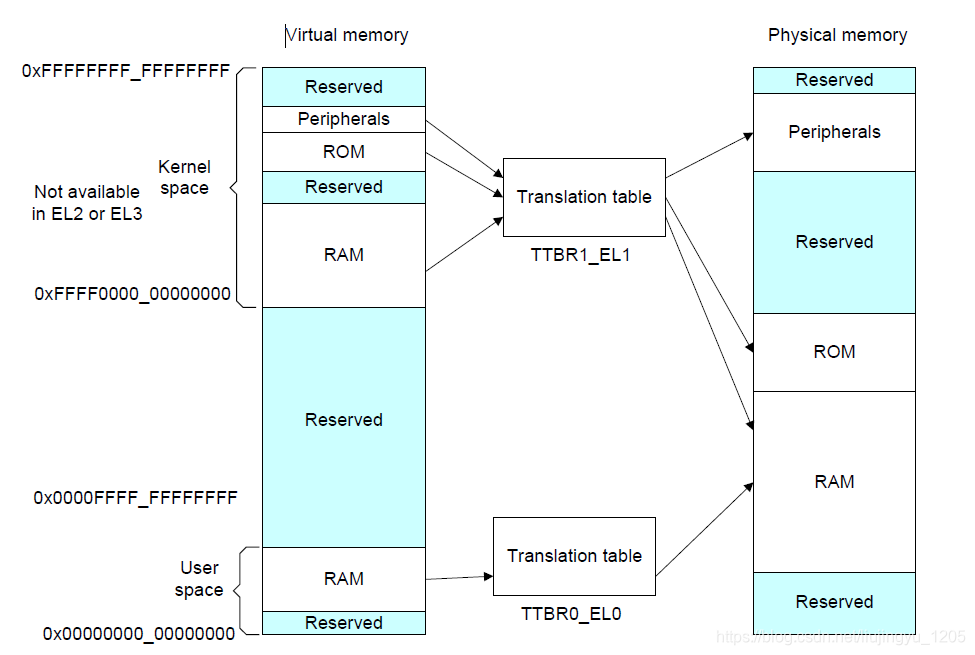
图7-3 ARMv8的四级页表的转换
7.5 三级Cache支持下的物理内存访问
CPU与内存之间存在三级Cache(L1、L2、L3),用于缓解CPU与内存的速度差异,提升访问效率。Hello程序的物理内存访问流程:
- CPU生成物理地址后,先访问L1 Cache(最快,容量最小);
- 若L1 Cache命中,直接从L1读取数据,完成访问;
- 若L1未命中,访问L2 Cache,命中则读取数据,并将数据缓存到L1; 4.若L2未命中,访问L3 Cache(最慢,容量最大),命中则读取数据,缓存到L2和L1;
5.若L3未命中,访问内存,读取数据后缓存到L3、L2、L1,再返回CPU。
Cache采用局部性原理(时间局部性、空间局部性),Hello程序中连续执行的指令和连续访问的数据能高效命中Cache,大幅提升程序执行效率。
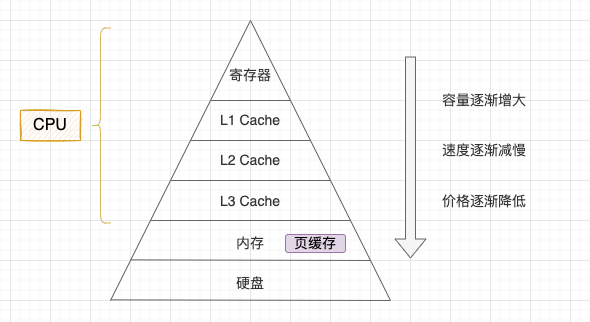
图7-4存储器金字塔结构
7.6 hello进程fork时的内存映射
Hello进程通过fork创建子进程时,采用写时复制(Copy-on-Write)的内存映射机制,核心流程:
- 共享物理内存:fork执行时,内核不为子进程分配新的物理内存,而是让父子进程共享所有物理内存页(代码段、数据段、堆、栈等);
- 标记写保护:将共享的物理内存页标记为写保护(只读);
- 写操作触发复制:当父进程或子进程修改某共享页的数据时,CPU触发页故障,内核捕获故障后,为修改方分配新的物理内存页,复制原页数据到新页,解除新页的写保护,将页表项指向新页;
- 独立内存空间:经过多次写操作后,父子进程的修改数据页完全独立,未修改的页仍保持共享。
写时复制机制避免了fork时大量的内存复制,减少了资源消耗,提升了进程创建效率。
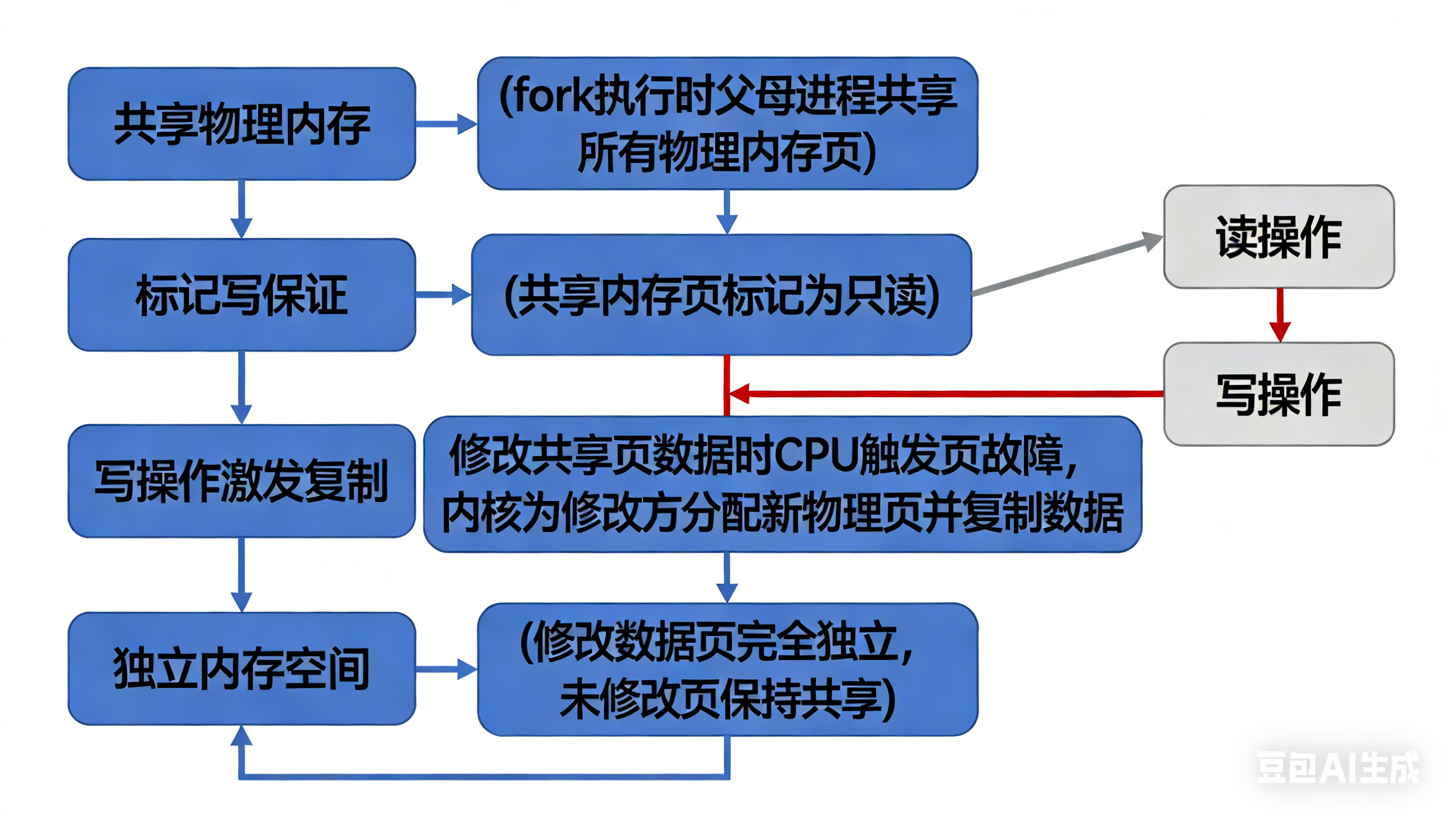
图7-5写时复制机制示意图
7.7 hello进程execve时的内存映射
execve加载hello程序时,内核为子进程创建新的虚拟地址空间并完成内存映射,核心流程:
- 销毁旧映射:释放子进程继承自父进程(bash)的虚拟地址空间映射(代码段、数据段等);
- 映射可执行文件:根据hello的ELF程序头表,将.text段(代码)映射到0x401000开始的虚拟地址(可读可执行),.data段(已初始化数据)映射到0x404000开始的虚拟地址(可读可写),.bss段(未初始化数据)映射到.data段之后(可读可写);
- 映射堆和栈:映射堆区域,映射栈区域(从高地址开始,初始大小固定,可动态扩展);
- 映射共享库:加载动态链接器,由动态链接器加载libc.so.6等共享库,映射到虚拟地址空间的高地址区域(与栈相邻);
- 建立页表:为各映射区域建立对应的页表项,标记权限,完成虚拟地址到物理地址的映射准备(实际物理内存加载采用缺页机制)
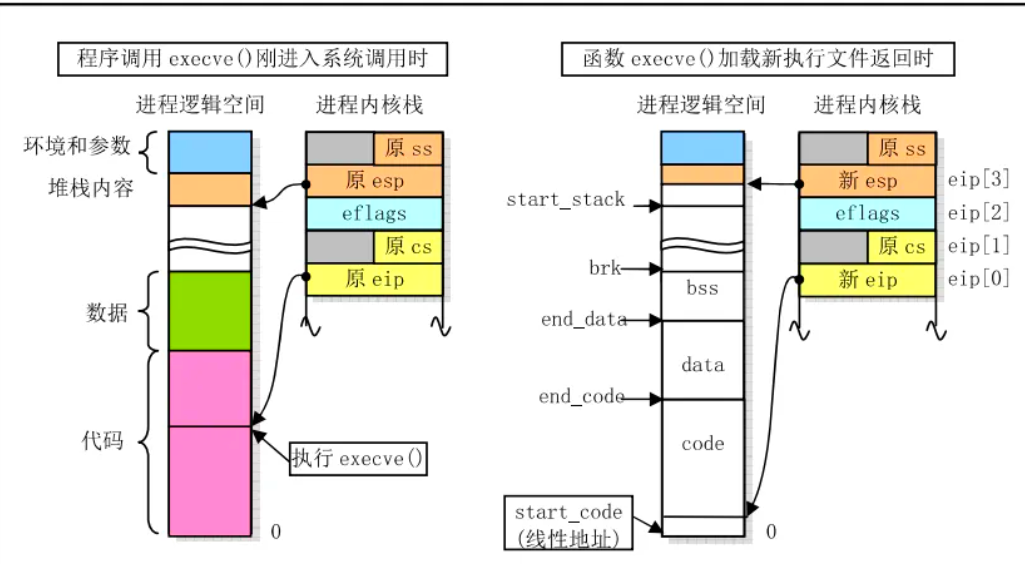
图7-6加载执行文件时栈的变化
7.8 缺页故障与缺页中断处理
Hello进程执行时,若访问的虚拟地址对应的物理页未加载到内存(如首次访问.text段某页、动态分配堆内存),则触发缺页故障(页错误),内核通过缺页中断处理流程解决:
- 触发中断:CPU执行指令时发现虚拟地址对应的页表项无效,触发缺页中断,陷入核心态;
- 保存上下文:内核保存当前进程的上下文;
- 检查地址合法性:内核检查虚拟地址是否在进程的地址空间内,若非法则发送SIGSEGV信号终止进程(段错误);
- 分配物理内存:若地址合法,内核为进程分配空闲的物理内存页;
- 加载数据:将磁盘中对应的数据(如hello的.text段数据、swap分区数据)加载到新分配的物理内存页;
- 更新页表:修改页表项,将虚拟地址映射到新的物理页框号,标记页表项为有效;
- 恢复上下文:内核恢复进程的上下文,返回用户态,让进程从触发缺页故障的指令重新执行。缺页机制实现了“按需加载”,减少了程序启动时的内存占用,提升了系统内存利用率。
图7-7 缺页中断处理流程示意图
7.9动态存储分配管理
Hello程序中printf函数的实现依赖动态内存分配,底层通过malloc函数申请动态内存,malloc的实现基于内核的brk或mmap系统调用,采用空闲块链表管理内存。核心机制:
- 内存分配:当申请的内存较小时,malloc通过调整堆顶指针扩展堆空间,从空闲块链表中查找合适的空闲块,分配给用户;
- 内存释放:free函数将用户释放的内存块归还给空闲块链表,若相邻存在空闲块则合并,减少内存碎片;
- 大内存处理:当申请的内存较大时,malloc通过mmap系统调用直接映射匿名内存区域(不占用堆空间),释放时通过munmap系统调用直接解除映射;
- 内存池优化:为提升效率,malloc维护内存池,预分配一定大小的内存块,避免频繁调用brk/mmap系统调用。动态存储分配机制实现了内存的灵活使用,满足程序运行时的动态内存需求。
图7-8 动态内存分配概述图
7.10本章小结
本章系统阐述了Hello进程的四类地址概念及转化关系;详细分析了x86-64架构下段式管理、四级页式管理的地址转换流程;探究了TLB和三级Cache对内存访问效率的提升机制;验证了fork时的写时复制、execve时的内存映射及缺页中断处理流程;简述了动态存储分配的核心机制。存储管理的核心目标是通过多层次的地址转换和缓存机制,实现虚拟地址到物理地址的高效、安全映射,优化内存利用率和访问速度,为进程执行提供稳定的内存环境。
(第7章 2分)
第8章 hello的IO管理
8.1 Linux的IO设备管理方法
Linux采用“一切皆文件”的IO设备管理思想,将所有IO设备(键盘、显示器、磁盘等)抽象为文件,通过统一的文件描述符(fd)机制管理。核心方法:
- 设备抽象:每种设备对应一个设备文件(位于/dev目录下),如键盘对应/dev/console,显示器对应/dev/tty,用户程序通过操作设备文件间接访问设备;2.设备驱动:内核通过设备驱动程序实现硬件与内核的交互,驱动程序隐藏设备硬件细节,为内核提供统一的接口;
3.文件描述符:进程通过文件描述符标识打开的文件/设备,标准输入(stdin)fd=0,标准输出(stdout)fd=1,标准错误(stderr)fd=2;
4.分层架构:IO管理分为用户层、内核层、驱动层、硬件层,用户程序通过系统调用陷入内核,内核调用驱动程序,驱动程序控制硬件执行IO操作,实现了用户程序与硬件的隔离。
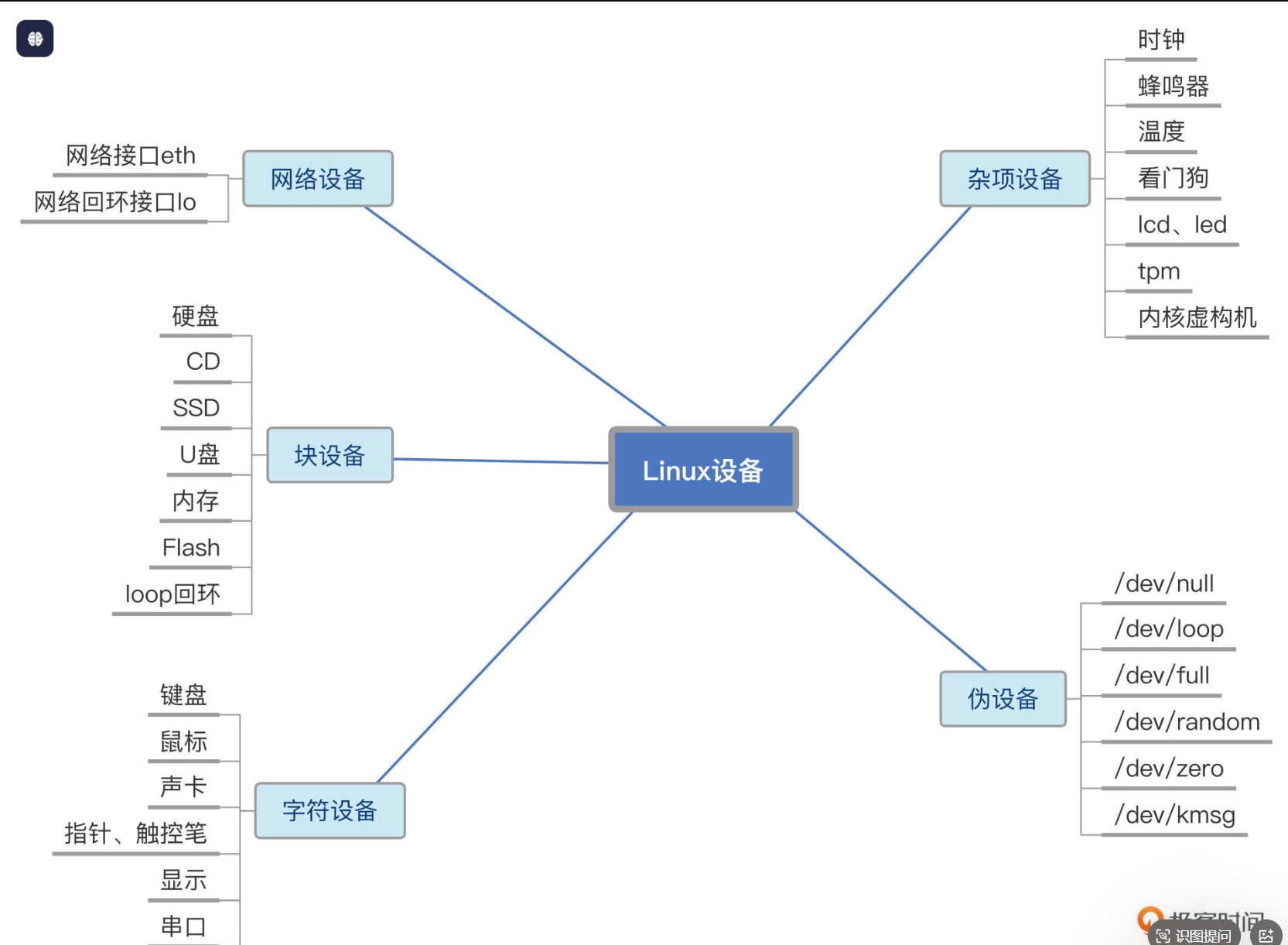
图8-1 Linux 设备示意图
8.2 简述Unix IO接口及其函数
Unix IO接口是Linux IO管理的核心,提供了一组简洁、统一的函数,适用于所有设备文件,核心函数包括:
- open:打开文件或设备,创建文件描述符,返回fd;函数原型:int open(const char *pathname, int flags, mode_t mode);flags指定打开模式(如O_RDONLY只读、O_WRONLY只写、O_RDWR读写);
- read:从fd对应的文件/设备读取数据到缓冲区;函数原型:ssize_t read(int fd, void *buf, size_t count);返回实际读取的字节数;
- write:将缓冲区的数据写入fd对应的文件/设备;函数原型:ssize_t write(int fd, const void *buf, size_t count);返回实际写入的字节数;
- close:关闭fd对应的文件/设备,释放相关资源;函数原型:int close(int fd);
- ioctl:设备控制函数,用于设置或获取设备特定参数;函数原型:int ioctl(int fd, unsigned long request, ...)。
Unix IO接口的特点是无缓冲(或少量缓冲)、支持阻塞/非阻塞模式,为所有IO设备提供了统一的操作接口。
8.3 printf的实现分析
https://www.cnblogs.com/pianist/p/3315801.html
printf 函数的实现本质是 “用户层格式化处理 - 内核层系统调用 - 硬件层显示输出” 的三级联动流程,核心围绕可变参数解析、格式转换、特权级切换与显存操作展开。
printf 的核心目标是接收可变个数、可变类型的参数,按指定格式字符串(fmt)转换为统一格式的字符串,并通过硬件显示器输出。其实现依赖 “分层解耦” 设计:用户层负责参数解析与格式化,内核层负责权限管控与系统调用转发,硬件层负责最终的像素渲染与显示,确保用户态程序无法直接操作硬件,保障系统安全。
1. 关键流程与核心组件
可变参数解析与格式化(vsprintf 核心作用)
printf 函数原型为 int printf(const char *fmt, ...),其中 ... 表示可变参数,其解析依赖 C 语言函数参数的栈布局规则(从右往左压栈、栈地址从高到低增长)。核心逻辑如下:
可变参数访问:通过 va_list(本质为字符指针)遍历栈中可变参数,通过 (char*)(&fmt) + 4(32 位系统)跳过固定参数 fmt 的栈地址,直接定位第一个可变参数的内存位置,后续通过指针偏移(如 p_next_arg += 4)依次访问后续参数;
格式转换:vsprintf 遍历格式字符串 fmt,非 % 字符直接写入输出缓冲区,遇到格式符(如 %x/%s/%d)时,从可变参数中取出对应值,转换为目标格式字符串(如整数转 16 进制字符串)后写入缓冲区;
结果输出:vsprintf 返回格式化后字符串的长度,为后续写入操作提供字节数依据。
2.系统调用与特权级切换(write 函数的核心作用)
用户态程序无硬件操作权限,需通过 write 函数触发系统调用,完成用户态到内核态的切换,核心流程如下:
系统调用封装:write 函数通过汇编指令设置寄存器(eax 存储系统调用号,ebx/ecx 传递缓冲区地址与字节数),随后触发中断(32 位 Linux 为 int 0x80,64 位为 syscall);
中断处理与特权级切换:中断触发后,CPU 从用户态(特权级 3)切换到内核态(特权级 0),通过中断门跳转到内核的系统调用处理函数 sys_call;
内核层转发:sys_call 保存用户态进程上下文,通过系统调用表(sys_call_table)定位到具体的写操作实现(sys_write),将用户缓冲区数据复制到内核缓冲区,避免用户态非法访问内核资源。
3.硬件层显示输出(驱动与显存操作)
内核通过显示驱动程序完成最终的硬件输出,核心逻辑如下:
字符与像素转换:驱动程序解析内核缓冲区中的 ASCII 字符,从字模库中获取对应字符的点阵数据,并转换为 RGB 颜色信息;
显存(VRAM)写入:显存是专门存储显示数据的内存区域,驱动将 RGB 像素数据按显存地址映射规则写入 VRAM(如 VGA 文本模式下 VRAM 起始地址为 0xB8000);
硬件渲染与显示:显示芯片(GPU)按固定刷新频率(如 60Hz)逐行读取 VRAM 中的像素数据,通过信号线(HDMI/VGA)传输给显示器,液晶面板根据 RGB 信号控制每个像素的亮度与颜色,最终呈现格式化字符串。

图8-2 printf函数的代码示例
8.4 getchar的实现分析
异步异常-键盘中断的处理:键盘中断处理子程序。接受按键扫描码转成ascii码,保存到系统的键盘缓冲区。
getchar等调用read系统函数,通过系统调用读取按键ascii码,直到接受到回车键才返回。
若Hello程序中包含getchar()(用于读取用户输入),其底层实现同样依赖Unix IO接口,核心流程:
- 等待输入:getchar是标准IO函数,采用行缓冲,若无缓冲区数据则调用read系统调用,传入fd=0(标准输入),等待用户输入;
- 键盘中断:用户按下键盘按键时,键盘产生中断信号,CPU陷入核心态,执行键盘中断处理子程序;
- 数据转换:中断处理程序读取键盘扫描码,转换为对应的ASCII码,将ASCII码存入系统键盘缓冲区;
- 读取数据:read系统调用从系统键盘缓冲区读取ASCII码,存入用户程序的缓冲区;
- 返回结果:getchar从用户级缓冲区读取一个字符,返回给程序;当用户按下回车键时,read系统调用返回,表明一行输入完成。若程序执行时未输入字符,getchar会阻塞,直到有输入或收到信号。
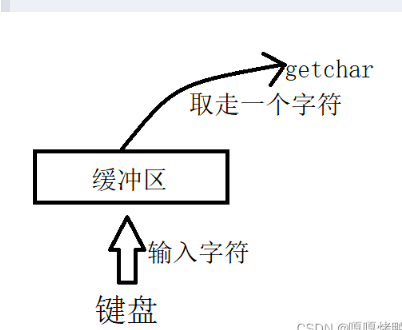
图8-3 getchar函数执行过程
8.5本章小结
本章阐述了Linux“一切皆文件”的IO设备管理思想,介绍了核心的Unix IO接口函数;深入分析了printf和getchar的底层实现流程,揭示了标准IO函数到系统调用、再到硬件执行的完整链路;验证了用户态与核心态的切换、驱动程序的桥梁作用。IO管理通过分层架构和统一接口,隔离了用户程序与硬件细节,实现了不同IO设备的统一、高效访问,是程序与外部环境交互的核心机制。
(第8章 1分)
结论
本报告以Hello程序为研究对象,完整剖析了其“从程序到进程”(P2P)的全生命周期及“从源码到输出”(O2O)的端到端流程,核心结论如下:
- 静态处理阶段:Hello程序从hello.c源码开始,经预处理(文本格式化)、编译(高级语言到汇编)、汇编(汇编到机器码)、链接(符号解析与重定位),最终生成可执行文件,各阶段生成的中间文件(hello.i、hello.s、hello.o)分别承担了标准化输入、指令过渡、机器码载体的作用,ELF格式贯穿始终,保障了各工具间的兼容性;
- 动态运行阶段:用户执行./hello时,Shell通过fork创建子进程,execve加载程序到新的虚拟地址空间,操作系统调度进程执行,通过段式、页式管理实现地址转换,借助TLB和Cache提升内存访问效率,通过IO操作完成结果输出,进程终止后释放资源;
- 核心机制支撑:整个生命周期依赖软硬件协同工作,编译器工具链实现了高级语言到底层指令的转化,操作系统通过进程管理、存储管理、IO管理提供了独立、高效的运行环境,地址转换、写时复制、缺页中断、动态链接等机制优化了资源利用率和执行效率。
通过实验深刻体会到计算机系统“分层架构”的合理性,各层各司其职、屏蔽细节,既降低了设计复杂度,又提升了系统的可扩展性。本次实验将理论知识与实践操作相结合,加深了对计算机系统底层原理的理解,认识到任何高级语言程序的执行,最终都离不开指令、内存、IO的协同工作。
(结论0分,缺失-1分)
附件
hello.c:Hello程序原始C语言源码文件,包含main函数和printf函数调用;
hello.i:预处理后的C语言文件,展开stdio.h头文件,删除注释,无预处理指令;
hello.s:x86-64架构汇编语言文件,包含main函数和printf调用对应的汇编指令;
hello.o:可重定位目标文件,包含机器码、数据及重定位信息;
hello:可执行目标文件,动态链接C标准库,执行后输出“Hello World”
(附件0分,缺失 -1分)
参考文献
为完成本次大作业你翻阅的书籍与网站等
[1] Randal E. Bryant, David R. O'Hallaron. 深入理解计算机系统(第三版)[M]. 北京:机械工业出版社,2016.
[2] https://www.cnblogs.com/pianist/p/3315801.html
[3] 段页式访存——逻辑地址到线性地址的转换_movl 8(%ebp), %eax-CSDN博客
[4] 段页式访存——线性地址到物理地址的转换_线性地址转为物理地址例题-CSDN博客
[5] 我把 CPU 三级缓存的秘密,藏在这 8 张图里 - 彭旭锐 - 博客园
[6] 【ARM-MMU】ARMv8-A 的4K页表四级转换(VA -> PA)的过程_arm mmu 粒度为什么是4k-CSDN博客
[7] 动态存储分配_百度百科
[9] Linux0.11内核execve函数实现原理与源码解析-开发者社区-阿里云
[10] 标准IO常用函数接口 - Dazz_24 - 博客园
[12] 揭秘C语言printf函数源码:揭秘内部实现,助你掌握打印输出技巧 - 云原生实践
[13] getchar函数详解看这一篇就够了-C语言(函数功能、使用、返回值)-CSDN博客
(参考文献0分,缺失 -1分)
转载自CSDN-专业IT技术社区
原文链接:https://blog.csdn.net/2403_86517790/article/details/156492109

