
Nvidia Jetson Thor DK 于 2025年8月25日正式发售,我们实验室获得了首批套件,经过几天的折腾,这篇博客将总结如何刷机以及刷机过程中的注意事项。
【Note】:由于评测部分内容太多,我们将这篇博客拆分为多篇避免单独的博客失去重点,你可以通过下面的链接进行跳转:
- 《全网首发! Nvidia Jetson Thor 128GB DK 刷机与测评(一)刷机与 OpenCV-CUDA、pytorch 编译》
- 全网首发! Nvidia Jetson Thor 128GB DK 刷机与测评(二)常用功能测评 Ollama、ChatTTS、Yolo 等
在一切的开始之前你需要阅读以下几点注意事项:
- 和 Orin 不同的是,Thor 自带了一个 1TB SSD,不需要额外购买一块固态硬盘,除非你想拆机换块大的;
- 由于 Thor 默认搭配的是
CUDA 13.0,这套硬件和架构目前还存在一些问题,如果你想要立刻部署到生产环境上,那么还是建议使用 Orin; - 在烧录镜像时为了提供更好的观感,博客中会尽可能使用官方手册提供的截图,只有在与手册中存在差异的时候才会用手机拍摄。
- 由于 Thor 硬件刚发布,Nvidia 可能会在后面的刷机流程中做一些更新,截止这篇博客完稿(2025年09月05日)我们发现了2处与官方教程中存在出入的地方,你需要注意 这篇博客的时效性;
- 官方推荐的刷机方法目前只支持 Ubuntu 24.04 与 CUDA 13.0+,首先确认自己的算法能够在这个版本上运行;
- 官方刷机方式有三种:ISO+USB、SDK Manager、Flash Script,这里演示第一种也是官方首推的方案,后面会新开一篇补充用 SDK Manager 的刷机流程,但不建议用第三种;三种刷机方法 的差异如下:
| 🚀 Jetson ISO | 🛠️ SDK Manager | 📜 Flash script | |
|---|---|---|---|
| 📋 Short Summary | USB installation disk to flash BSP (plus alpha) | GUI software to flash BSP and install JetPack packages | Ubuntu script to flash BSP |
| 🖥️ Ubuntu Host PC | ❌ Not required | ✅ Required | ✅ Required |
| ⏱️ Flash time | ⚡ Less than 15 min | ⌛ About 30 min | ⌛ About 30 min |
| 🔧 Install BSP? | ✅ Yes | ✅ Yes | ✅ Yes |
| 🐳 Install Docker? | ✅ Yes | 💡 Yes, when chosen in 2nd stage | ❌ No |
| 📦 Install JetPack components | ❌ No | 💡 Yes, when chosen in 2nd stage | ❌ No |
| 👥 Who is this for? | 🌟 Everybody including beginner | 🧑💻 Who has an Ubuntu PC | 🛠️ Product Developers |
我们本次刷机中使用到的将部分资源放在了网盘中:
通过网盘分享的文件:Jetson Thor
链接: https://pan.baidu.com/s/1YdujHck2Fi6rAOzGfHoG4w?pwd=rrjj 提取码: rrjj
--来自百度网盘超级会员v5的分享
核心流程参考了官方刷机手册:
- Nvidia Jetson Thor: nvidia.com/jetson-thor

Step1. 设备开箱与准备
1.1 设备开箱
在拆开设备后应该能看到以下几个组件,除了插头线缆只会用到一条以外,其他的都会在刷机过程中使用;
- Jetson Thor DK 主机;
- DC 适配器 + 3 种插头线缆;
- 1 条 USB-Type C 数据线;
【注意】:由于 Thor 最高支持 240W 的运行功率,因此 Orin 的原装充电器是不能给 Thor 使用的;

1.2 准备引导U盘
除此之外你还需要准备以下软硬件用来辅助刷机:
- 一台剩余硬盘容量 大于25GB Windows 笔记本(官网上说Mac与Linux都可以,这里以Windows为例);
- 一块容量 大于 16GB 的 U盘;
- 一台显示器与 DP 或 HDMI 连接线;
- 一套 USB 键盘鼠标;
- 不小于 240W 供电功率的环境;
在 Windows 电脑上下载 Jetson ISO 镜像和 Balena Etcher 软件,你可以通过我们的网盘链接中下载也可以直接访问官方提供的链接:
- 百度网盘:Jetson Thor
- Jetson 官方镜像: Jetson ISO r38.2-08-22
- Balena Etcher 软件:Windows x86_x64
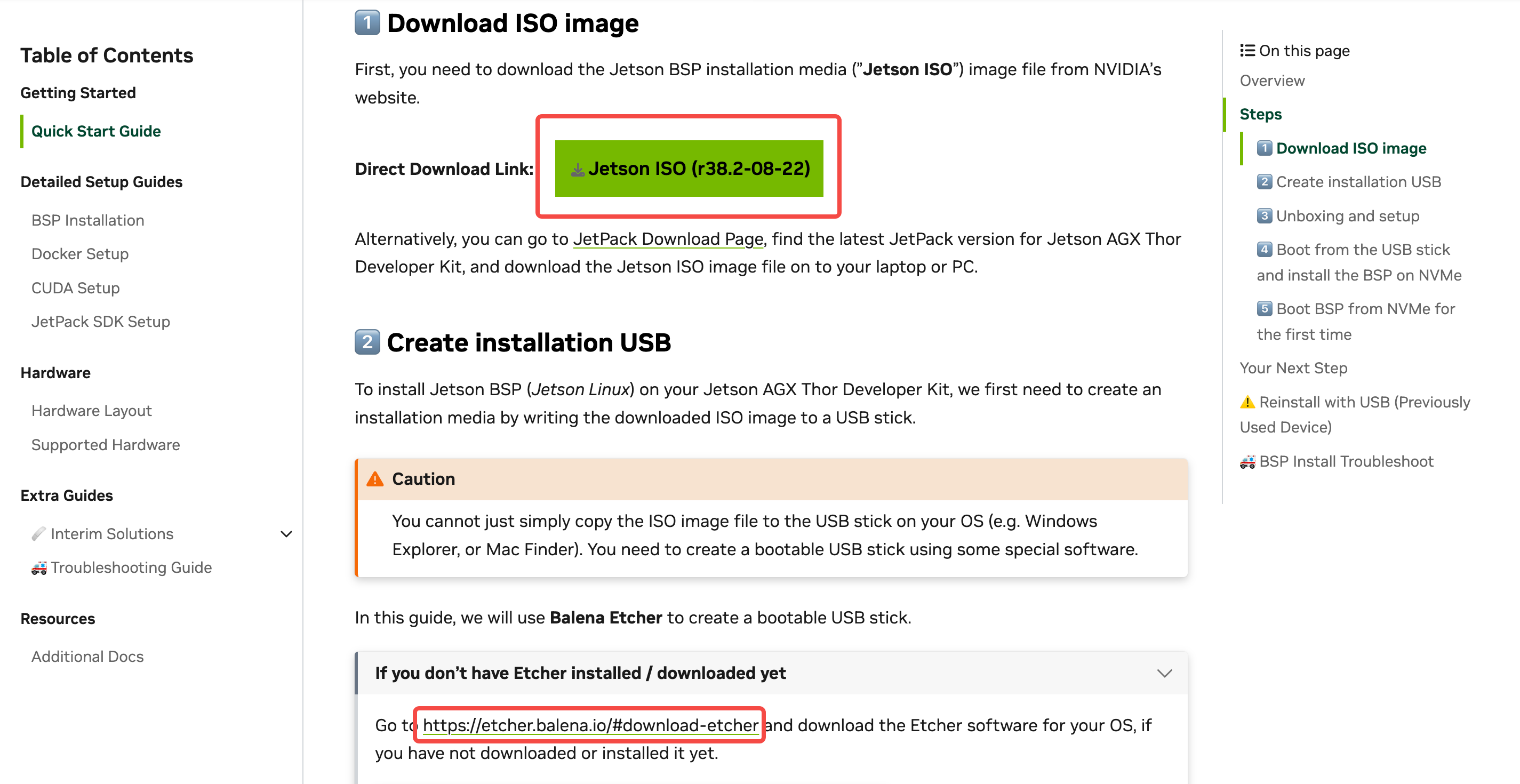
【注意】:这个过程会格式化 U 盘,务必做好备份;
在 ISO 镜像和 Balena Etcher 都下载好后直接打开软件按照下面的步骤操作:
- 点击 “从文件烧录 / Flash from file” ,选择 ISO 镜像文件;
- 点击 “选择目标磁盘 / Select target”,选择 U 盘;
- 点击 “现在烧录 / Flash !” 开始烧录,等待烧录完成;
| Step.1 | Step.2 | Step.3 |
|---|---|---|
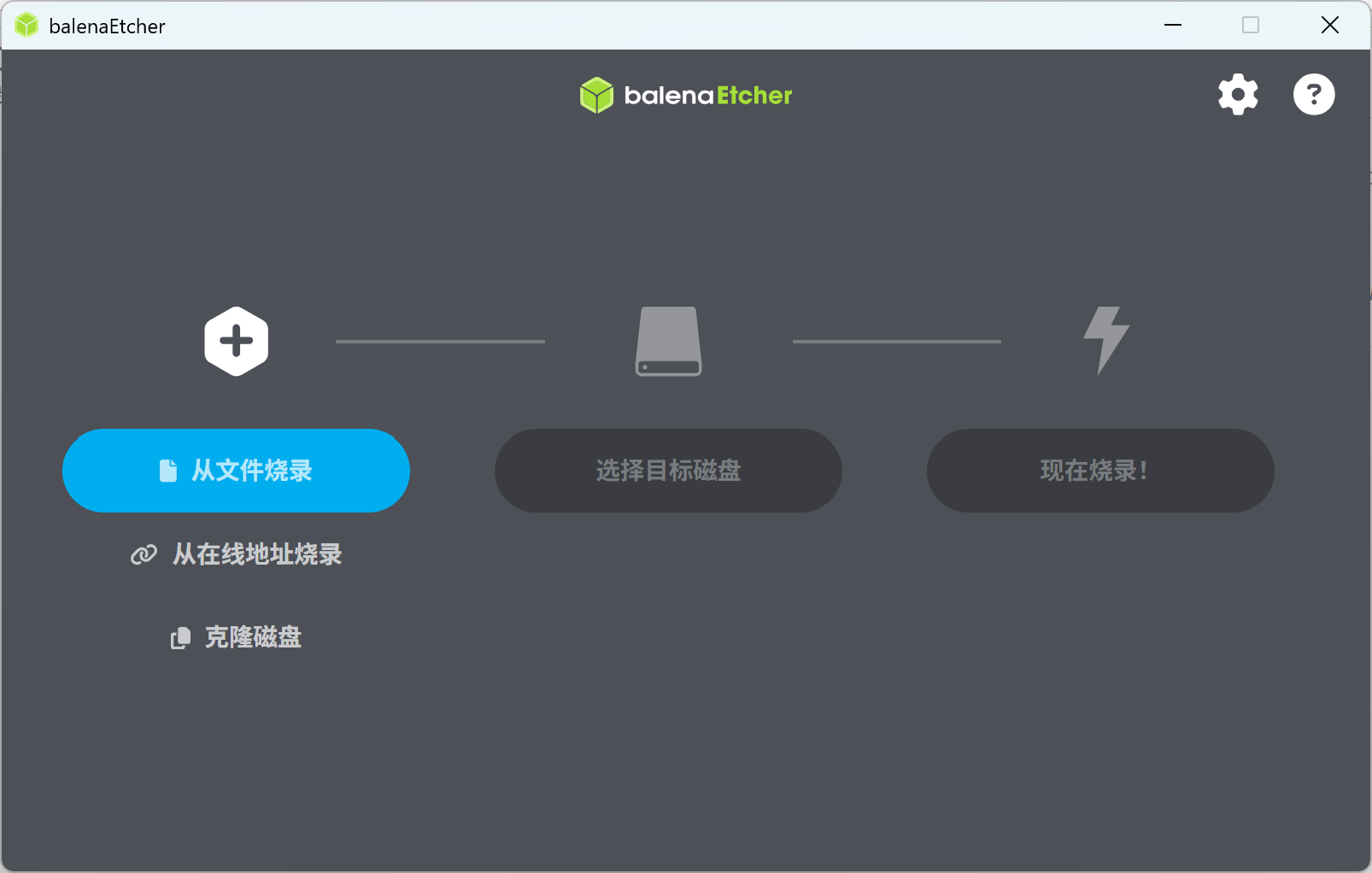 | 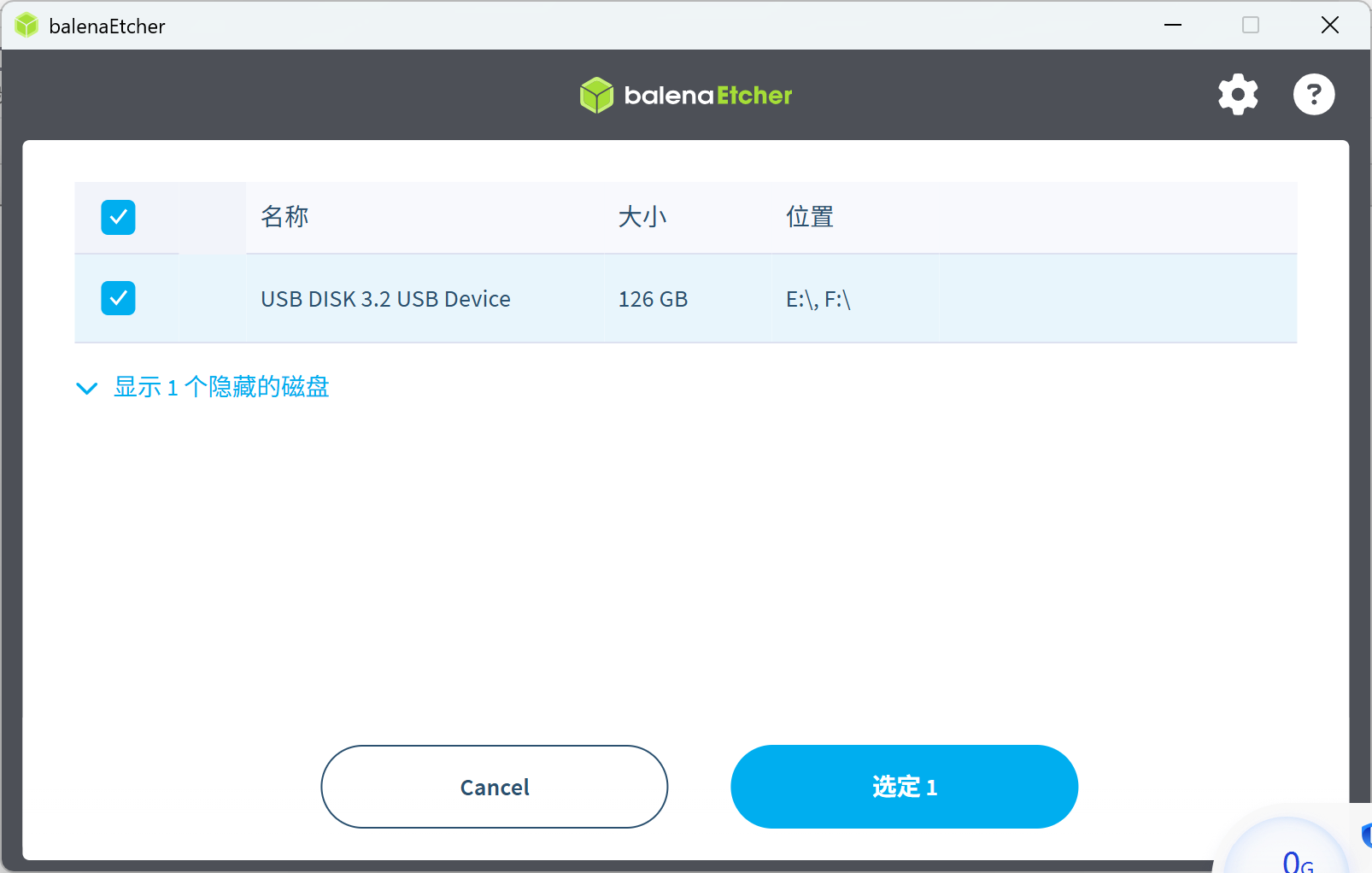 | 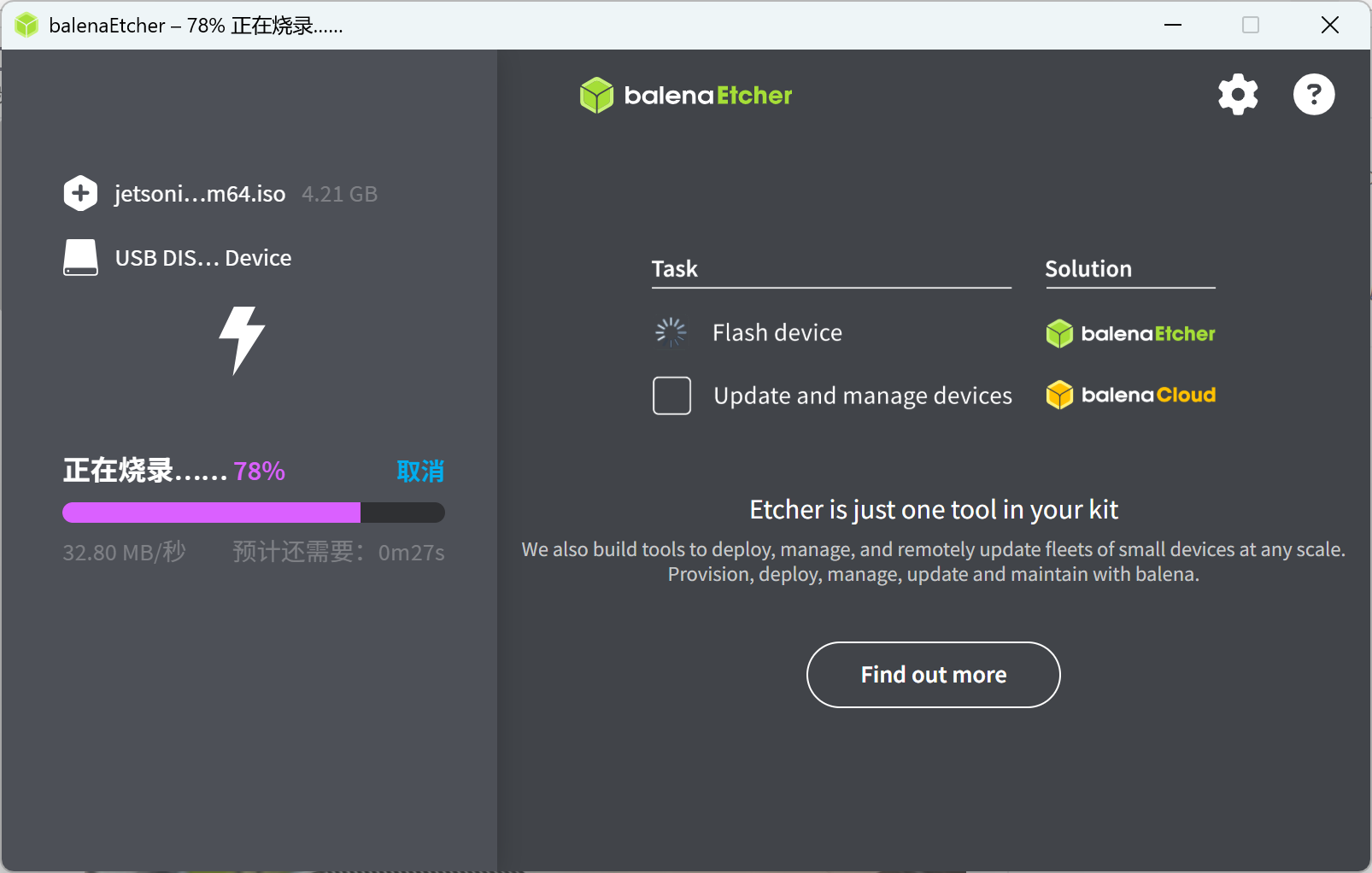 |
烧录完成后即可将 U 盘从 Windows 电脑上拔下;
Step2. 烧录镜像
将 HDMI 线、键盘鼠标、U盘、Type-C 电源线链接到 Thor 上,其中 Type-C 电源可以选择两个 C 口中的任意一个,不一定要使用说明书上的 DC 供电口:

通常情况下一插上电源就会自动开机,在开机的时候会有一个选择时间,但只有 1s,如果你错过了这个时间窗口并进入了下面这个场景也不用慌,输入 exit 即可:
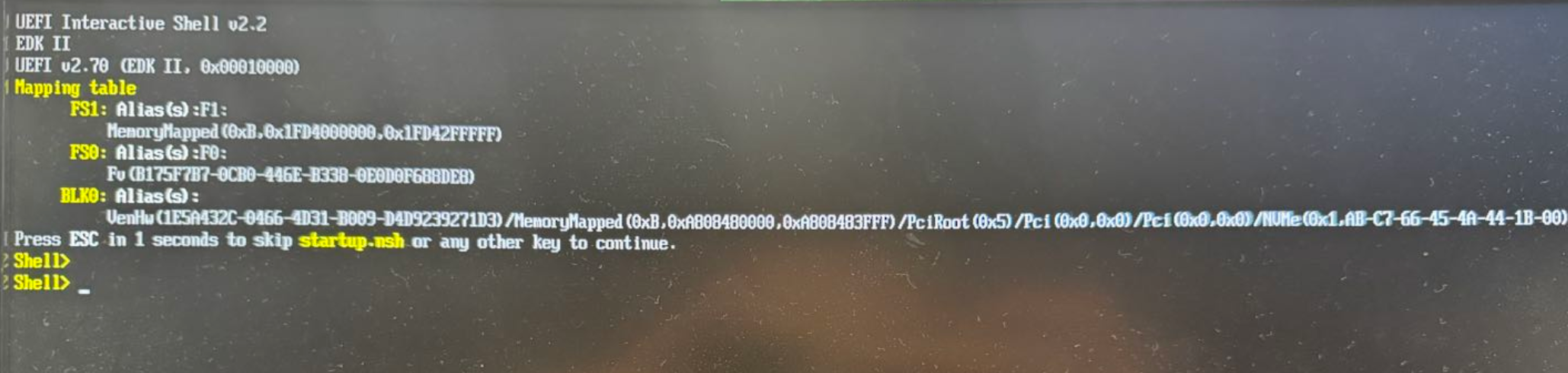
然后你会进入下面这个画面,使用键盘进入 Boot Manager:
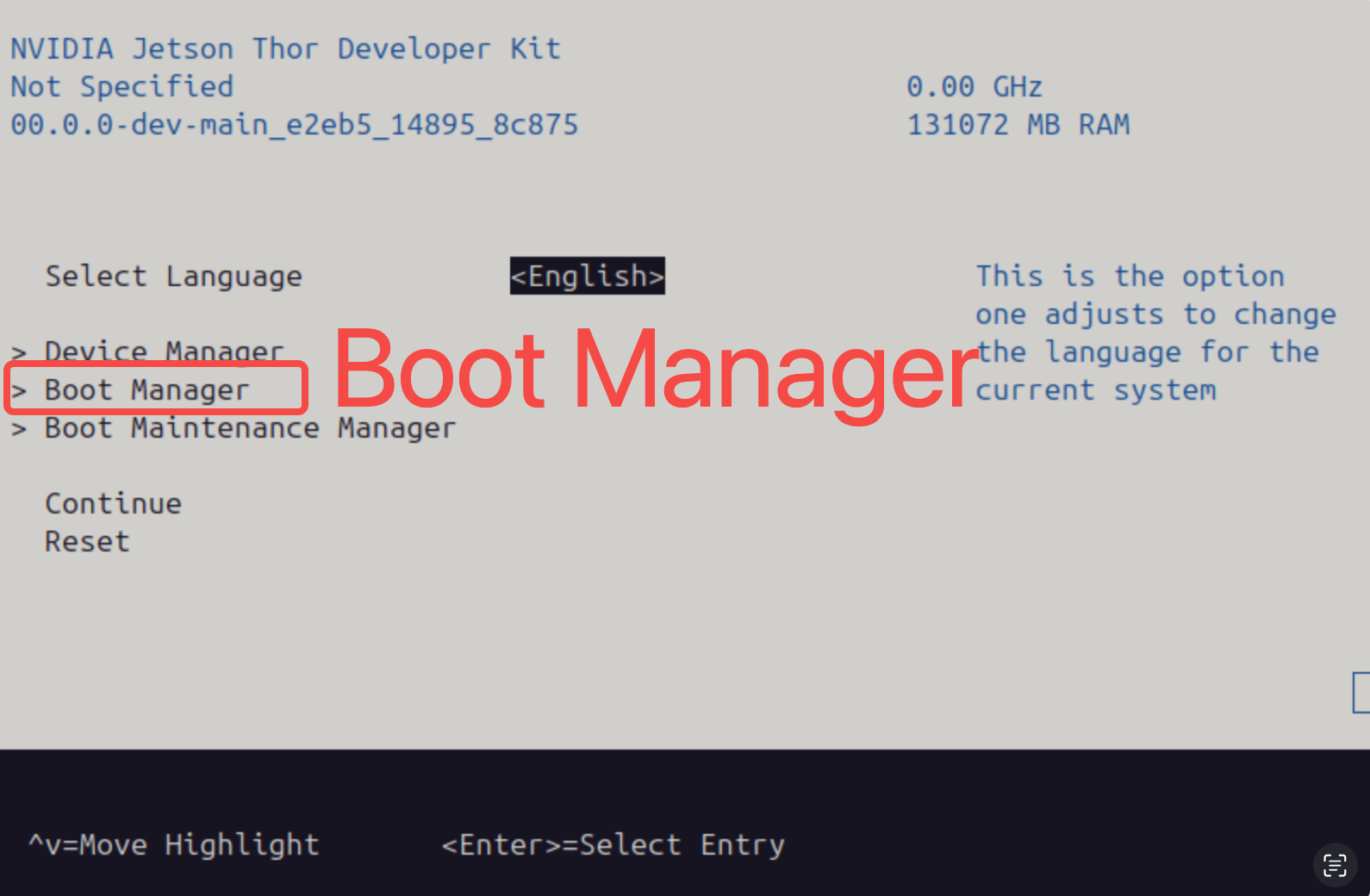
确保你的 USB 设备是在列表中的第一个,如果你的 U 盘没有显示则先按 Esc 退到上一级目录,然后重新插拔 U 盘再进入 Boot Manager 即可:
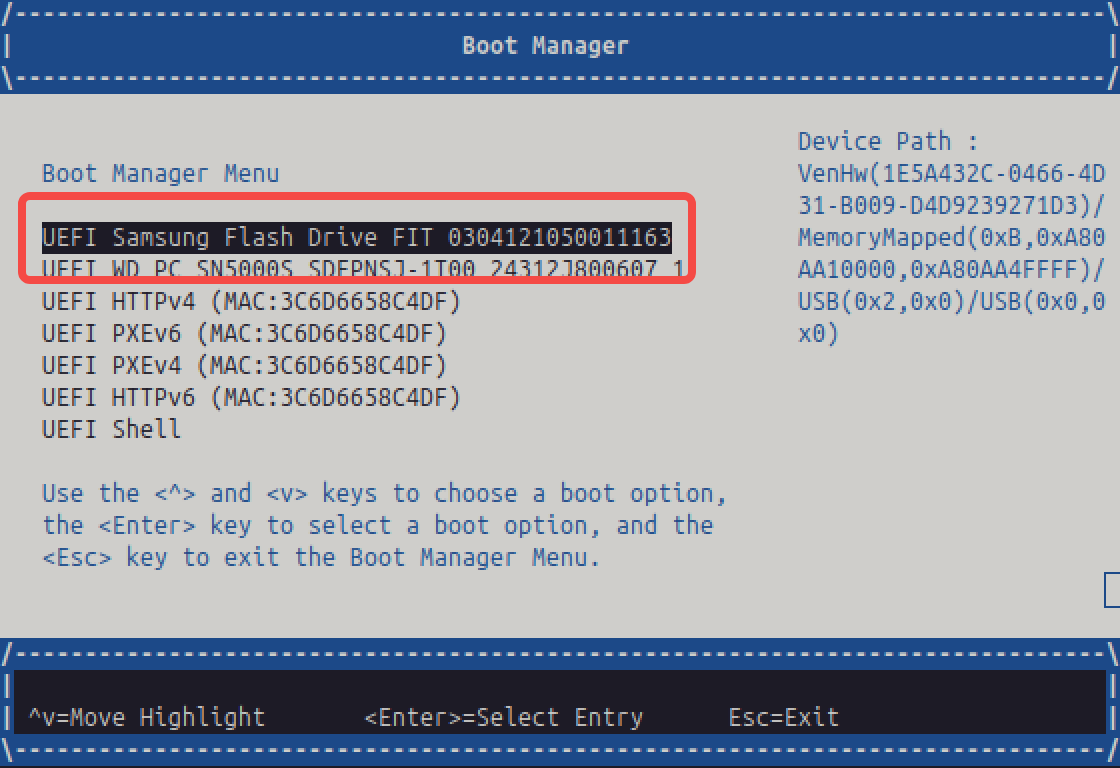
然后在键盘上敲击 Esc 推出这个界面后选中 Continue 回车:
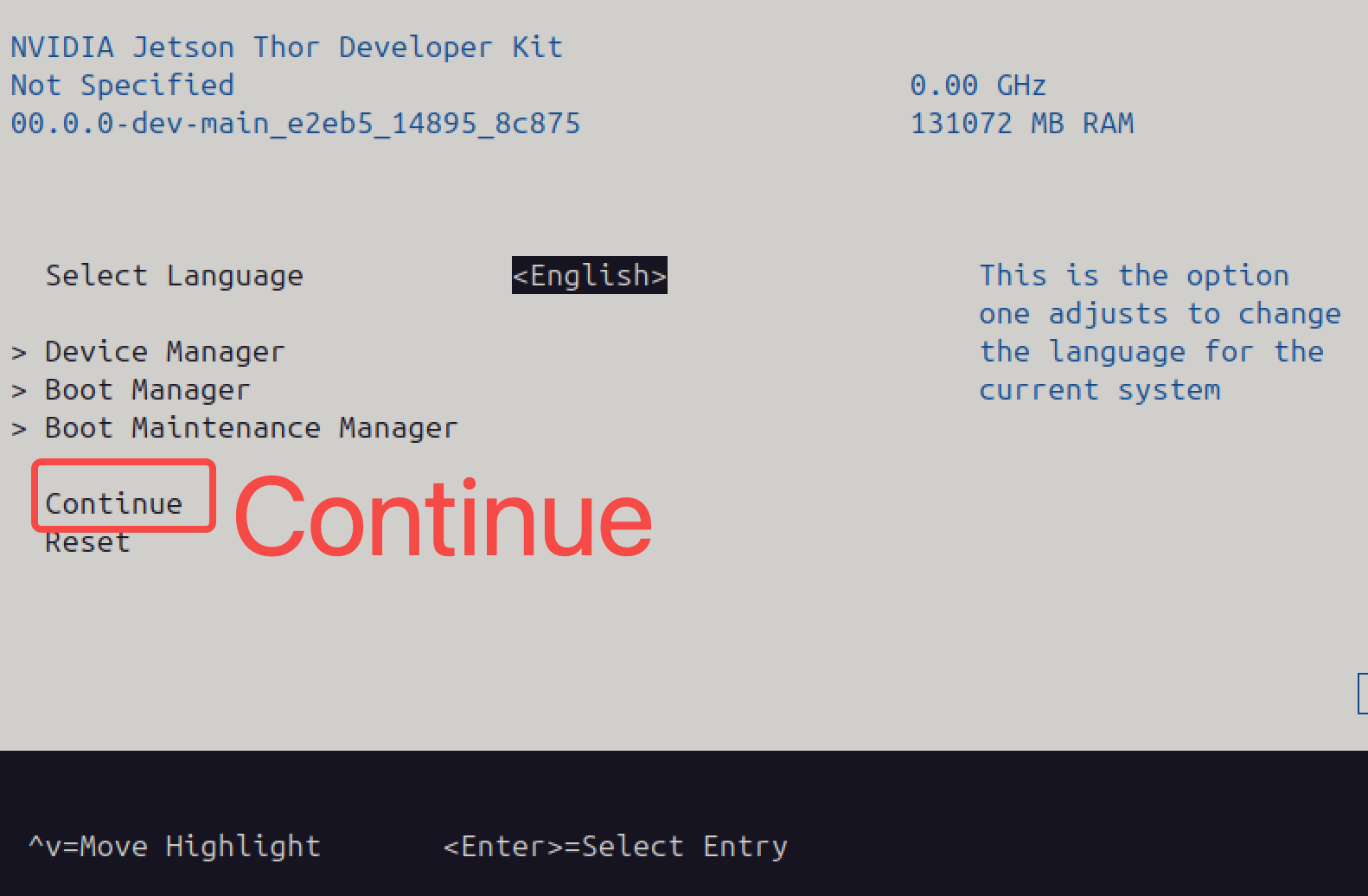
在短暂的黑屏后会看到这个界面,选择 Jetson Thor options 并回车:
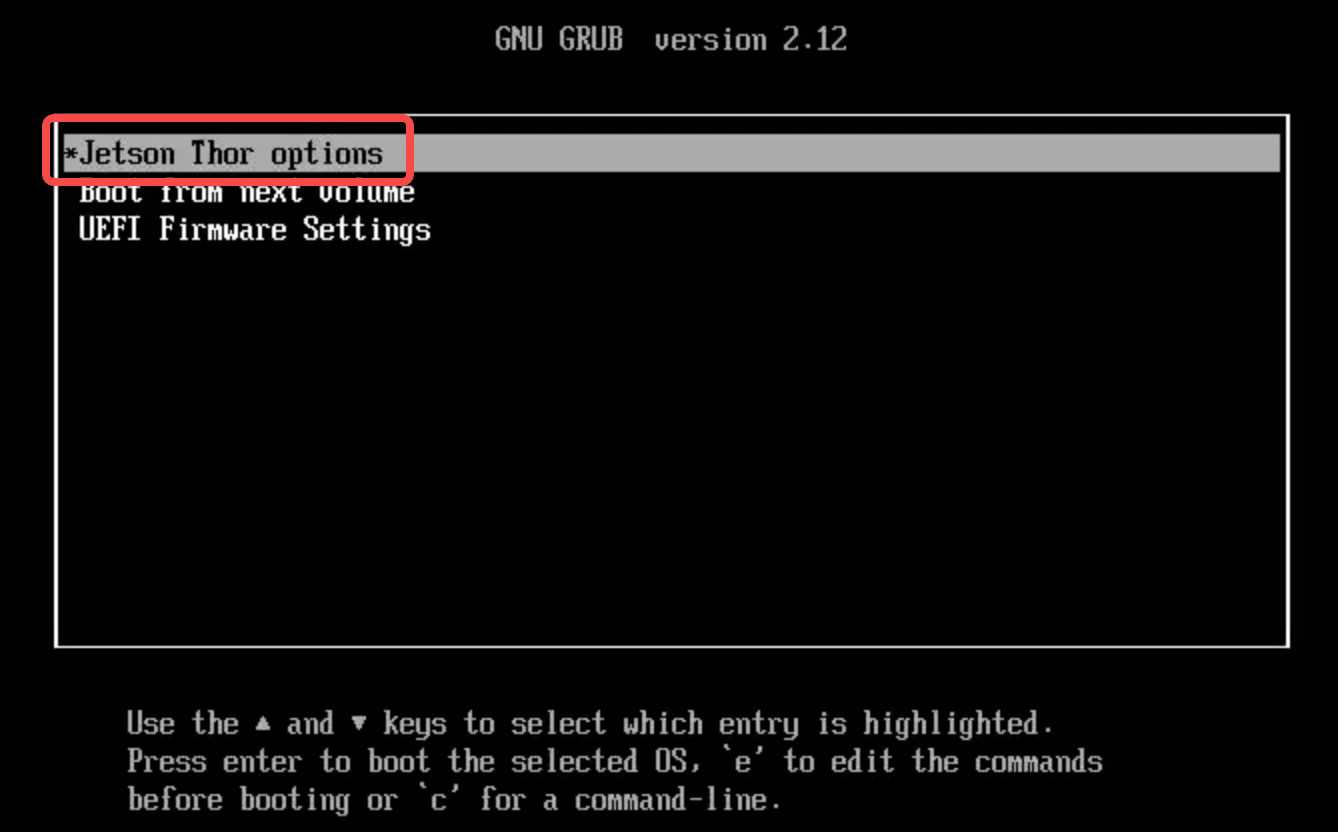
这里和官网上给的画面存在一些出入,需要选择 Flash Jetson AGX Thor Developer Kit on NVMe 0.2.0-r38.2 这个选项,不要选择 USB 那个选项,此处的含义是将镜像刷到哪个位置,因此不能刷到 U 盘上;
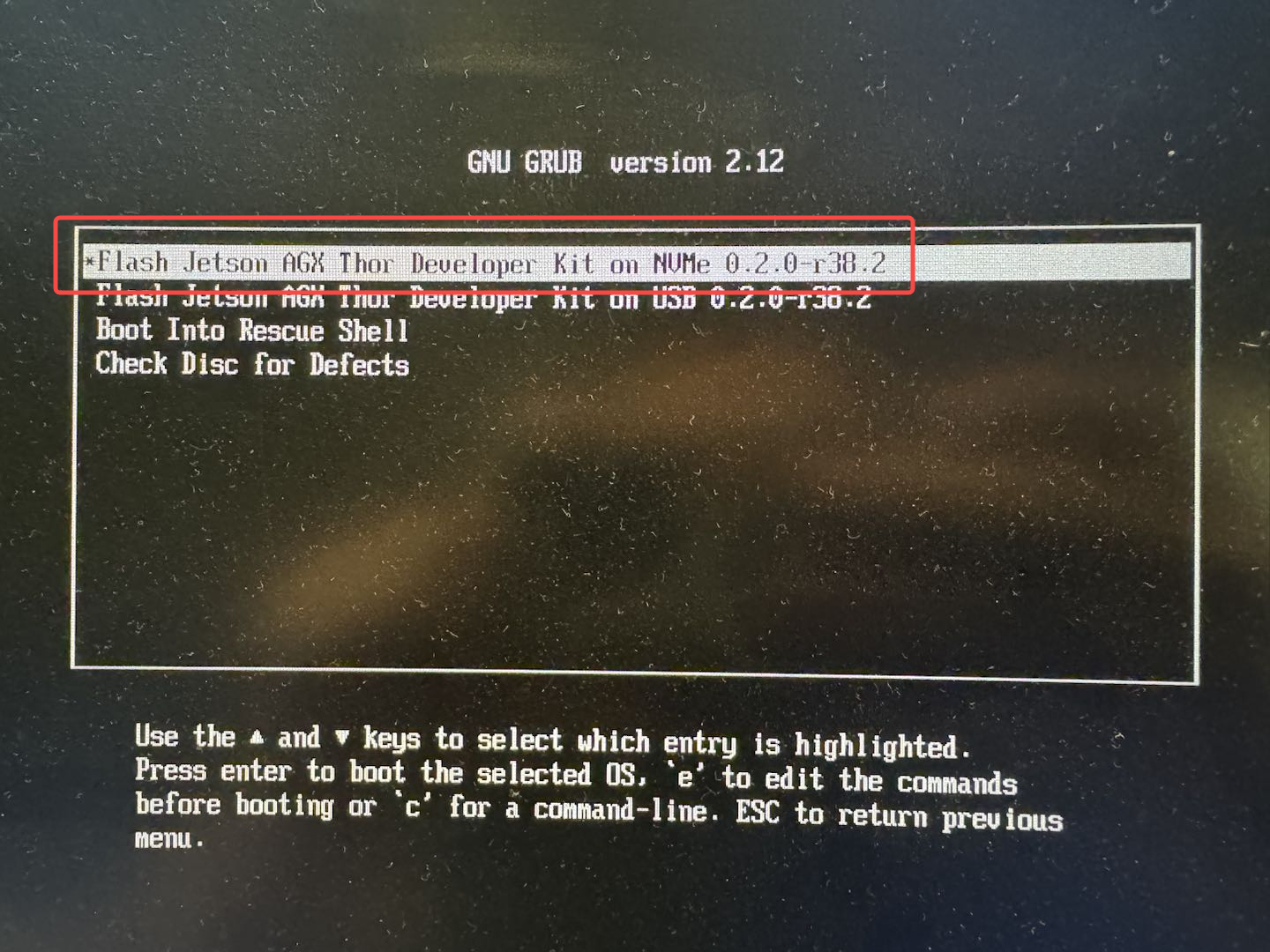
然后就是大约等待 15 分钟左右:

这一阶段完成会自动重启并进入如下界面,等待 Update Progress 进度条走完即可:

此处与官网也有些出入,如果你的 U盘还没有拔下来,那么自动重启后会出现下面的画面,用键盘选择 Boot from next volume :
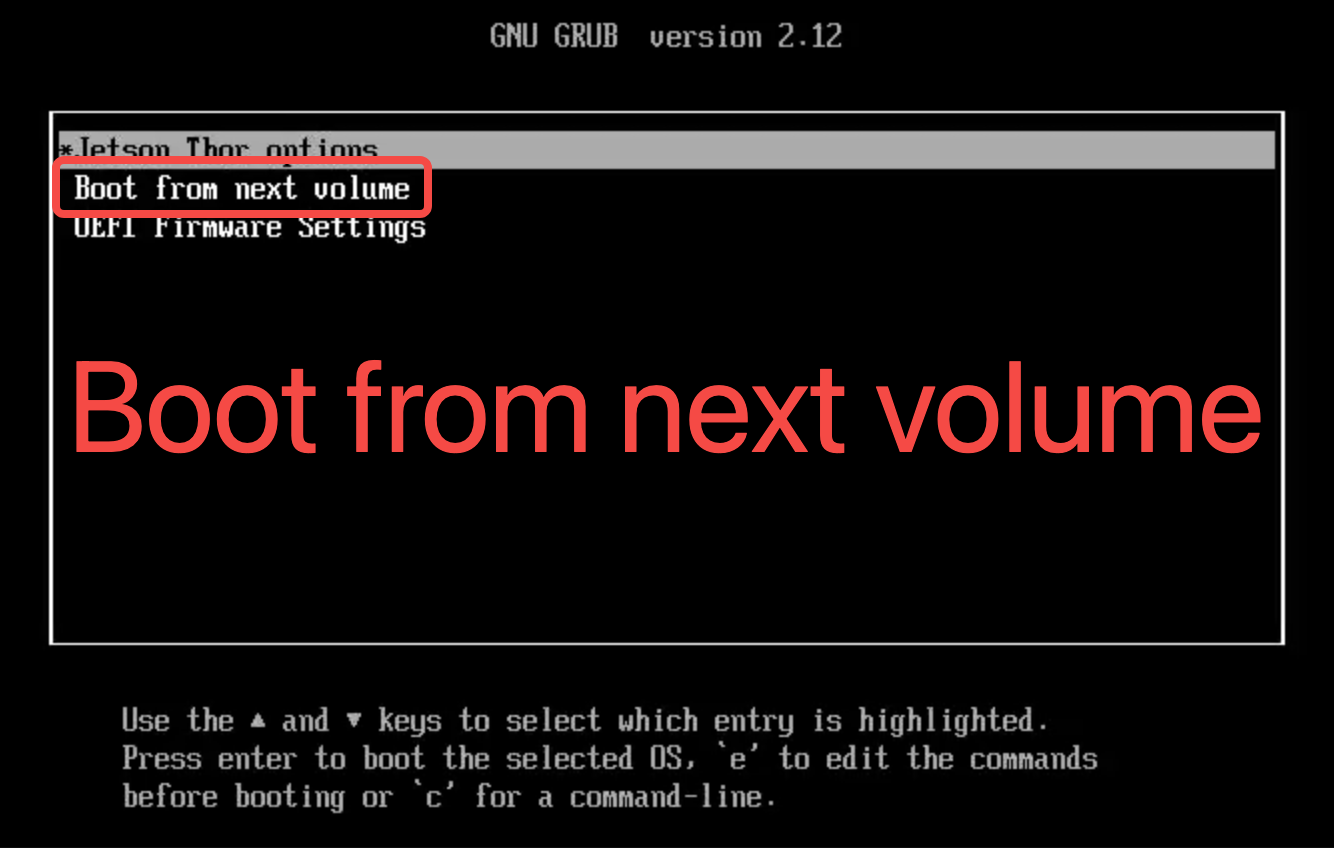
然后就是进入到标准的 Ubuntu 安装界面了:

连接好 Wifi、设置用户名密码、选择好时区后就可以正常使用 Ubuntu ,此时你需要 将 U盘拔下来,避免重启后又从 U盘引导:

Step3. 安装 CUDA & Jetpack
这部分内容参考了官方文档,并选择以 Native 的方式安装,在官方文档中提供了基于 Docker 的安装,感兴趣的可以自行探索:
- Jetson AGX Thor Developer Kit - User Guide: CUDA Setup
在 Native 的模式下使用 Option 2: JetPack APT repo 的方式安装可以一口气将 CUDA 和 Jetpack 都安装上;
因为 Ubuntu 24.04 不自带浏览器,所以最初的一些安装与下载需要一个辅助电脑,我这里直接用网线和我的 Mac 相连并将两台电脑都配置到 192.168.1.X 这个网段下(Thor 地址为 192.168.1.120,笔记本地址为 192.168.1.100),然后用终端进行访问,我的 Mac 已经安装好了 Clash 并设置了 7890端口,至于如何科学上网请自行解决;

在终端上执行下面命令,这个过程大概会占用 15GB+ 的硬盘资源,因此如果没有科学上网会非常漫长:
【Note】:不要使用 x86 架构安装 CUDA 的方法,会失败
$ export http_proxy="http://192.168.1.100:7890"
$ export https_proxy="http://192.168.1.100:7890"
$ sudo apt update
$ sudo apt install nvidia-jetpack
这一条命令将安装下面这些组件,包含开发过程中所需的全部资源:

安装成功后使用下面的命令查看 cuda 安装情况,这里安装的是 V13.0.48 版本:
$ nvcc -V
nvcc: NVIDIA (R) Cuda compiler driver
Copyright (c) 2005-2025 NVIDIA Corporation
Built on Wed_Jul_16_07:31:19_PM_PDT_2025
Cuda compilation tools, release 13.0, V13.0.48
Build cuda_13.0.r13.0/compiler.36260728_0
Step4. 部署常用环境
这部分内容包括部署与安装以下库:
- jetson-stats & jtop;
- OpenCV with CUDA:
- TensorRT & DeepStream;
- pytorch with CUDA;
- ROS rolling;
4.1 更换国内源与密钥
由于清华源中 Ubuntu 24.04 基本是 x86 和 amd64 架构的包,因此在更换源的时候需要使用下面的内容替换 /etc/apt/sources.list 文件,建议在操作之前 备份这个文件:
deb [arch=arm64] http://ports.ubuntu.com/ubuntu-ports focal main restricted universe multiverse
deb [arch=arm64] http://ports.ubuntu.com/ubuntu-ports focal-updates main restricted universe multiverse
deb [arch=arm64] http://ports.ubuntu.com/ubuntu-ports focal-backports main restricted universe multiverse
deb [arch=arm64] http://ports.ubuntu.com/ubuntu-ports focal-security main restricted universe multiverse
然后执行源更新命令:
$ sudo apt-get update
如果你在更新过程中遇到了如下有关 GPG 密钥的报错:

可以执行下面的命令,但要注意 命令末尾那个公钥需要和你的保持一致:
$ sudo apt-key adv --keyserver hkp://keyserver.ubuntu.com:80 --recv 40976EAF437D05B5
4.2 jetson_release & jtop
使用下面的命令安装:
$ sudo apt update
$ sudo apt install python3
$ sudo apt install python3-pip
$ sudo pip3 install -U pip
$ sudo pip3 install jetson-stats
如果你遇到了如下报错:
thor@thor:/usr/local/cuda/lib64$ sudo pip3 install jetson-stats
error: externally-managed-environment
× This environment is externally managed
╰─> To install Python packages system-wide, try apt install
python3-xyz, where xyz is the package you are trying to
install.
If you wish to install a non-Debian-packaged Python package,
create a virtual environment using python3 -m venv path/to/venv.
Then use path/to/venv/bin/python and path/to/venv/bin/pip. Make
sure you have python3-full installed.
If you wish to install a non-Debian packaged Python application,
it may be easiest to use pipx install xyz, which will manage a
virtual environment for you. Make sure you have pipx installed.
See /usr/share/doc/python3.12/README.venv for more information.
note: If you believe this is a mistake, please contact your Python installation or OS distribution provider. You can override this, at the risk of breaking your Python installation or OS, by passing --break-system-packages.
hint: See PEP 668 for the detailed specification.
那么使用下面的命令重制一下系统 python 的 EXTERNALLY-MANAGED 后重新执行
$ sudo mv /usr/lib/python3.12/EXTERNALLY-MANAGED /usr/lib/python3.12/EXTERNALLY-MANAGED-back
安装完成后激活 jtop 服务并重启 Thor,建议在重启之前可以先将左上角的功率模式调整为 MAXN:
$ sudo systemctl restart jtop.service
$ sudo reboot now
然后用下面的命令验证安装是否成功:
$ jtop
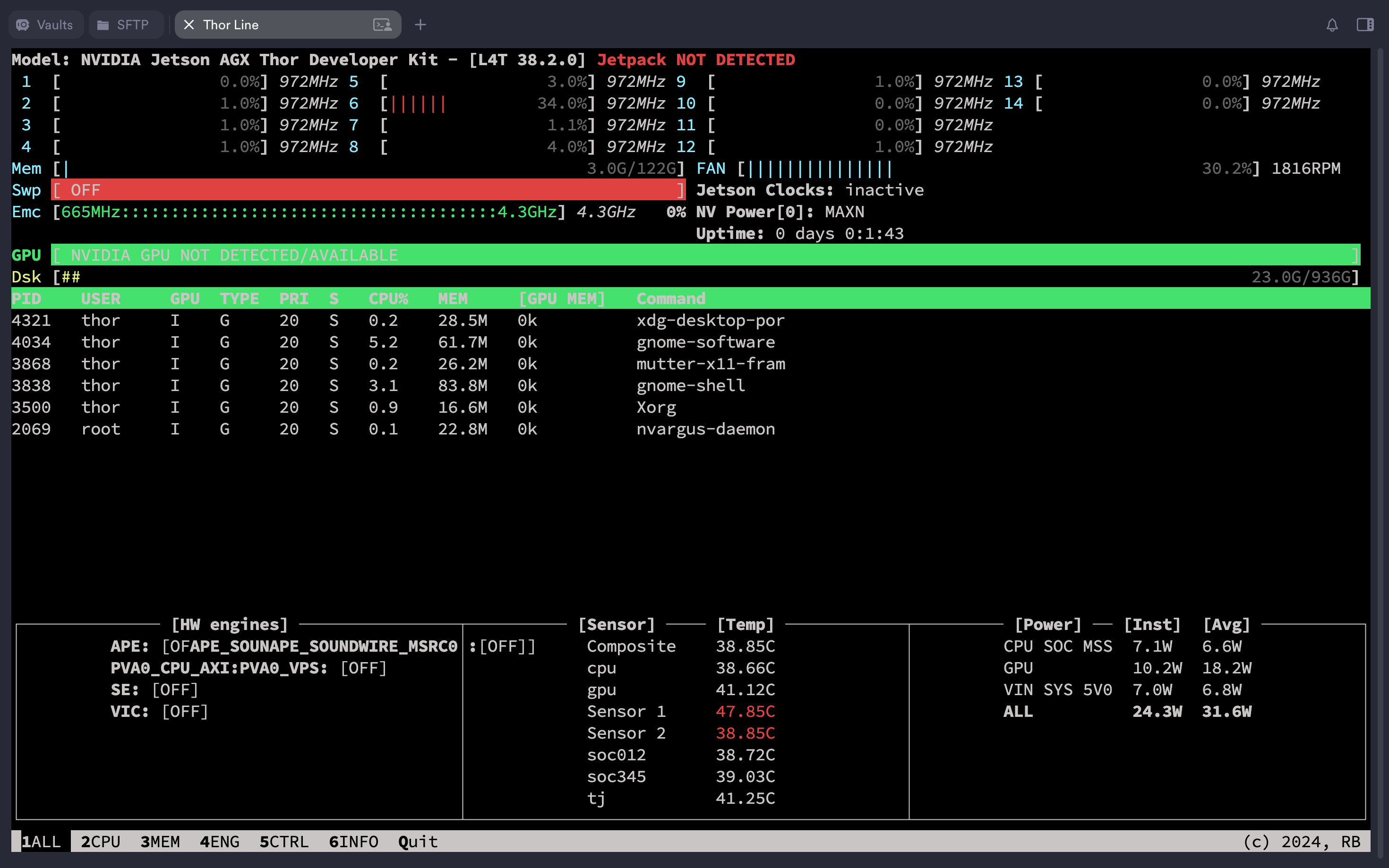
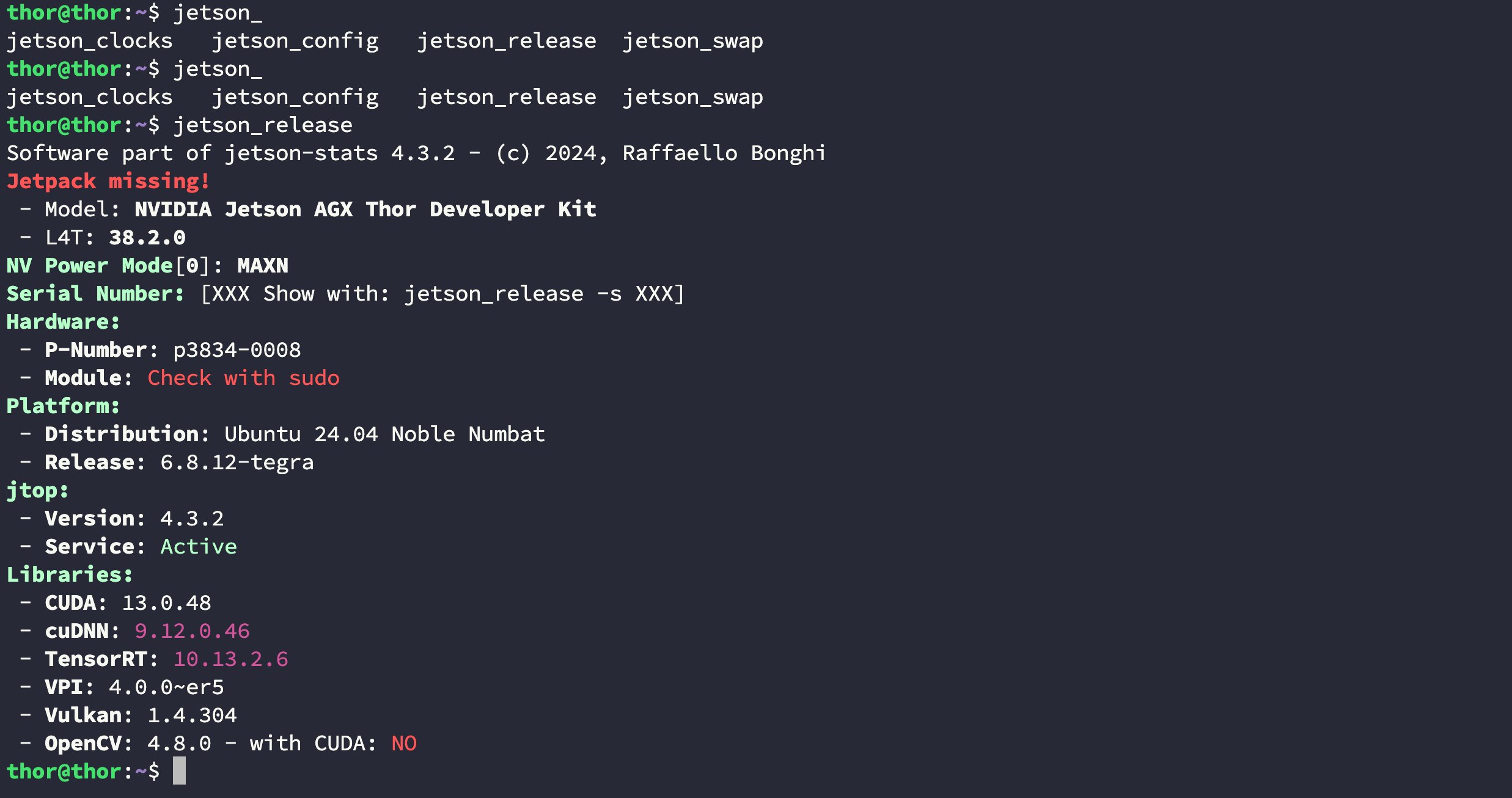
这个工具包会自带 jetson_release,用下面的命令进行验证:
$ jetson_release
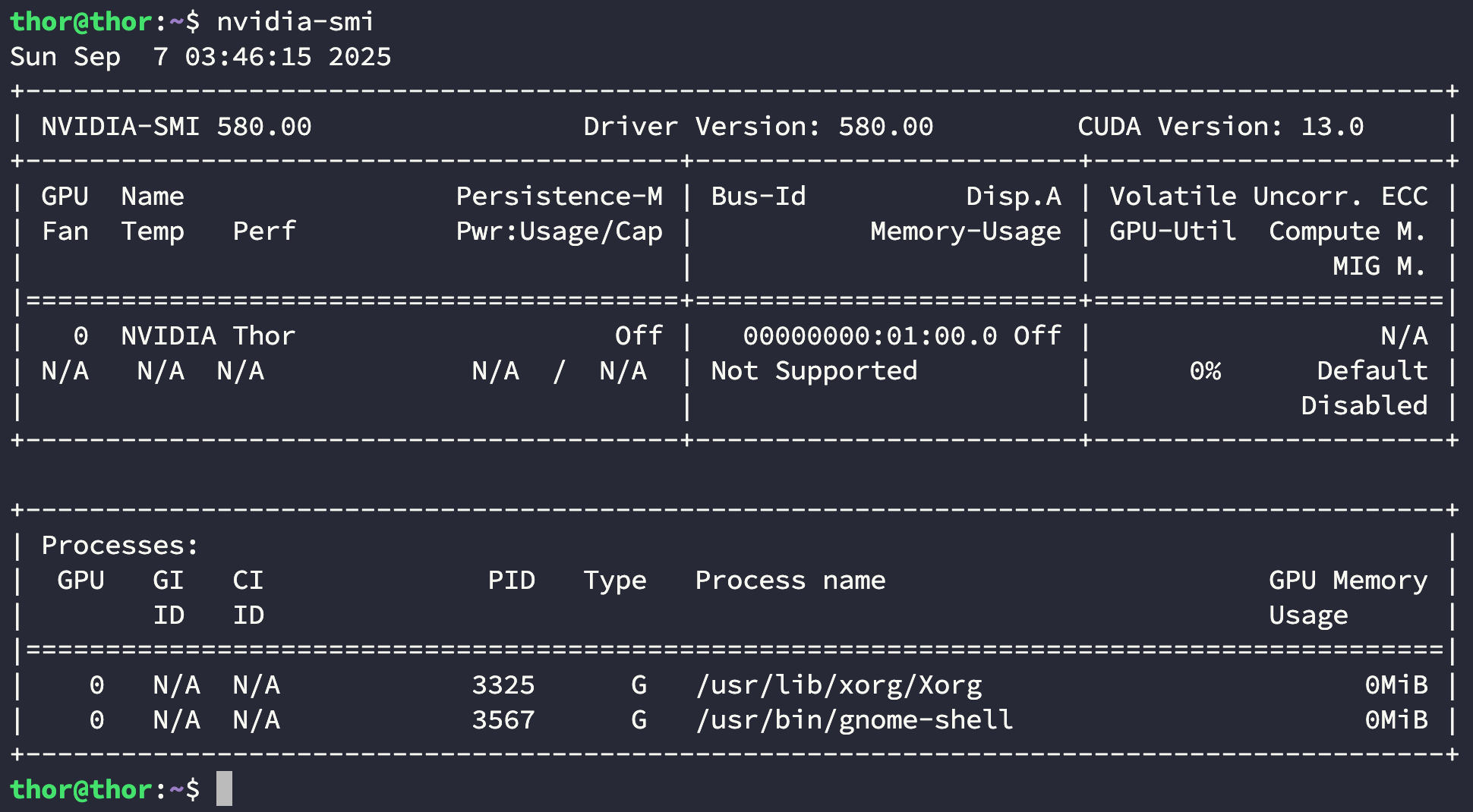
Nvidia 在 CUDA13 中添加的一个新特性就是 统一了不同平台迁移,因此之前在 x86 上使用的 nvidia-smi 也就可以使用了:
$ nvidia-smi
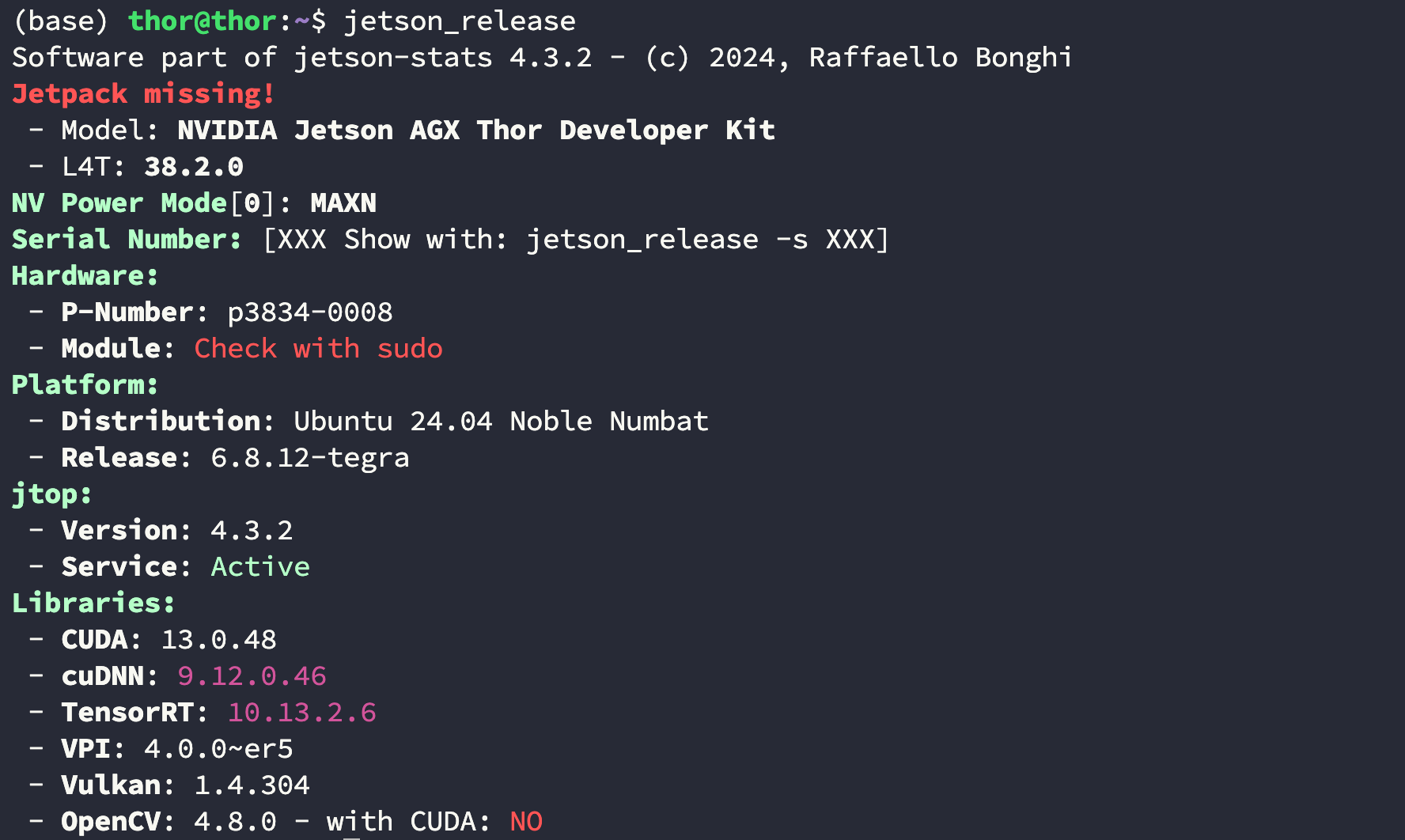
4.3 OpenCV with CUDA
通过 jetson_release 命令可以看到 Jetpack 中自带的 OpenCV 版本是 4.8.0:
【注意】:以下是有关 CUDA 与 OpenCV 的编译注意事项
- 编译
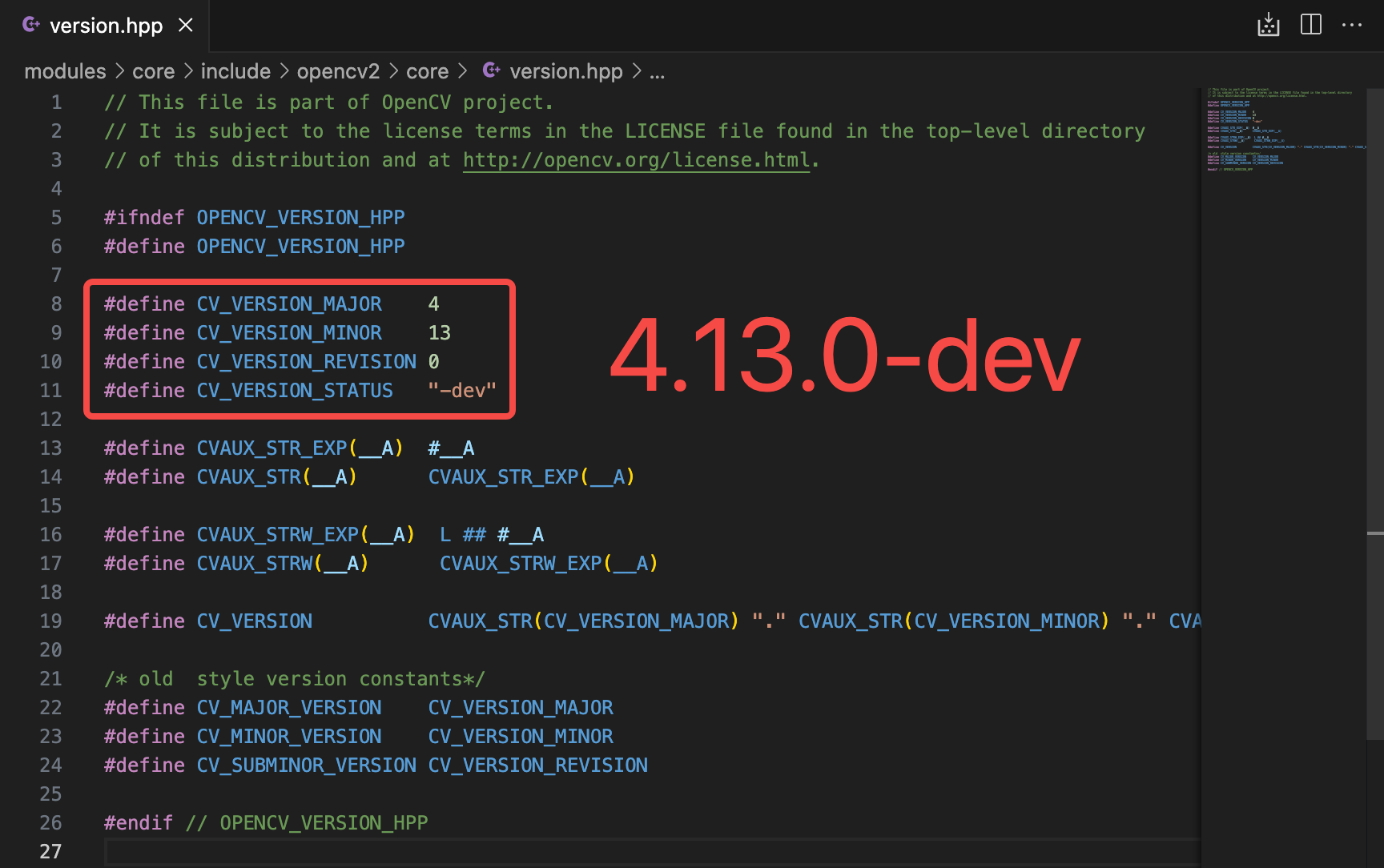
4.8.0和4.12.0这两个 CUDA 版本都失败了,在 Github 的 Issue 上说这两个版本对 CUDA13.0+ 存在Bug; - 成功编译的是
4.13.0-dev版本,但在目前(2025年09月05日)这个 tag 还没有被官方打出来,你只能在源文件modules/core/include/opencv2/core/version.hpp中看到这个版本号;
4.3.1 安装依赖库
$ sudo apt install build-essential checkinstall cmake pkg-config yasm git gfortran wget curl
$ sudo apt install libjpeg-dev libpng-dev libtiff-dev
$ sudo apt install libavcodec-dev libavformat-dev libswscale-dev libv4l-dev libxvidcore-dev libx264-dev
$ sudo apt install libgtk2.0-dev libgtk-3-dev libatlas-base-dev gfortran python3-dev python3-numpy
$ sudo apt-get install libtbbmalloc2 libtbb-dev libdc1394-22-dev
4.3.2 拉取源码并切换分支
拉取源码,源码可以拉取到任意位置,此处以 Downloads 为例。为了以后 OpenCV 更新后能标识出正式版,建议将这个文件夹以 dev 方式命名:
$ cd Downloads
$ git clone https://github.com/opencv/opencv.git opencv-dev
$ git clone https://github.com/opencv/opencv_contrib.git opencv_contrib-dev
此时你的文件结构如下:
$ ll
total 16K
drwxr-xr-x 4 thor thor 4.0K Sep 5 13:06 ./
drwxr-x--- 18 thor thor 4.0K Sep 4 18:01 ../
drwxrwxr-x 13 thor thor 4.0K Sep 3 19:50 opencv-dev/
drwxrwxr-x 7 thor thor 4.0K Sep 3 19:49 opencv_contrib-dev/
进入到 opencv-dev 目录下将 opencv_contrib-dev 移动进来并进行编译:
$ mv opencv_contrib-dev/ opencv-dev/
$ cd opencv-dev/
$ mkdir build && cd build
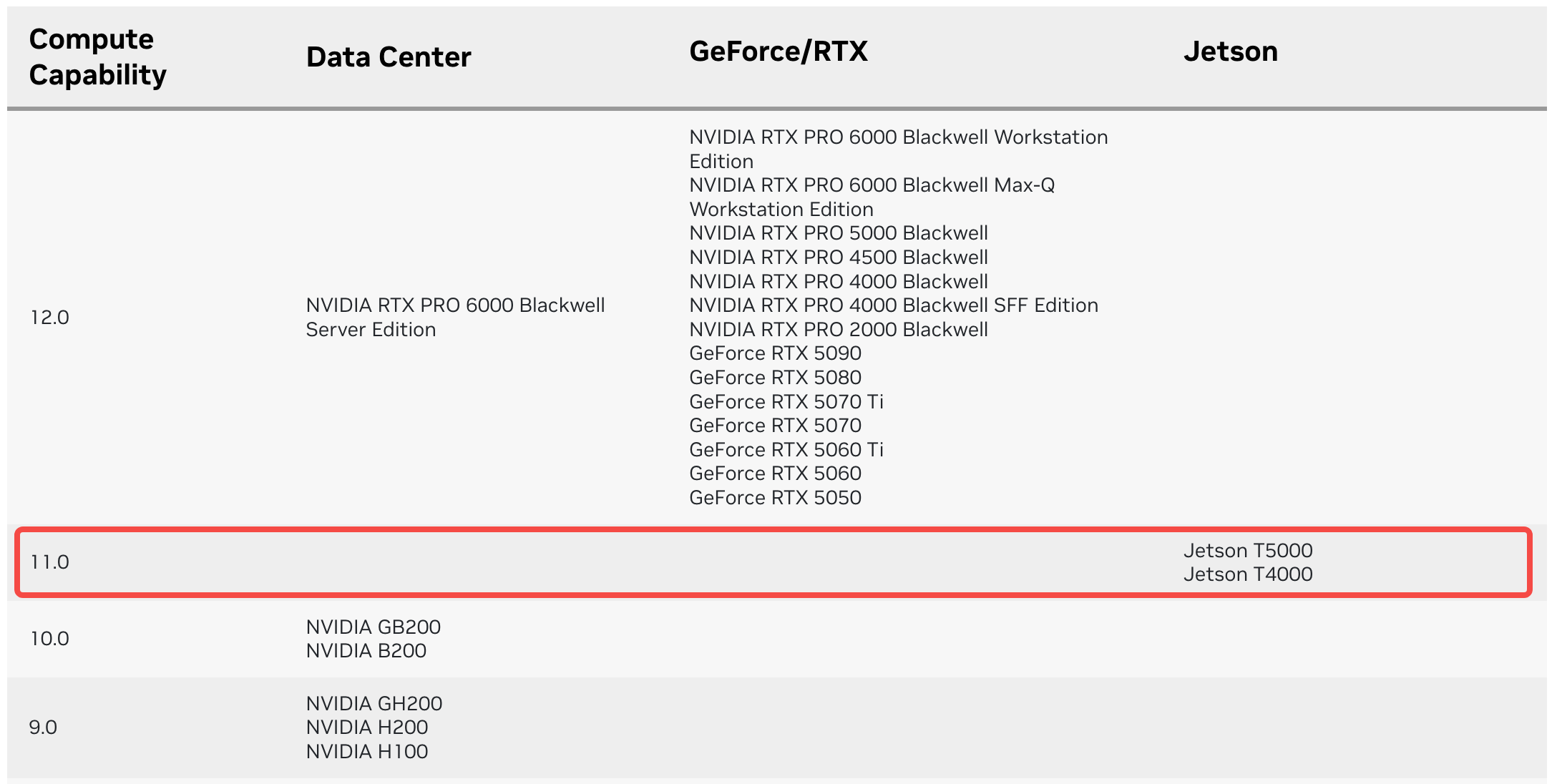
使用下面的命令时要注意 DCUDA_ARCH_BIN 和 DCUDA_ARCH_PTX 这两个值,截止日前(2025年09月05日) Nvidia 还没有在官网上发布 Thor DK 对应的 Compute Capability,但 Thor 使用的是 T5000 或 T4000 模组,因此这里的 DCUDA_ARCH_BIN 需要设置为 11.0:
- Nvidia 官网 Compute Capability: https://developer.nvidia.com/cuda-gpus
配置 cmake :
$ cmake \
-DCMAKE_BUILD_TYPE=Release \
-DCMAKE_INSTALL_PREFIX=/usr/local \
-DOPENCV_ENABLE_NONFREE=1 \
-DBUILD_opencv_python2=1 \
-DBUILD_opencv_python3=1 \
-DWITH_FFMPEG=1 \
-DCUDA_TOOLKIT_ROOT_DIR=/usr/local/cuda \
-DCUDA_ARCH_BIN=11.0 \
-DCUDA_ARCH_PTX=11.0 \
-DWITH_CUDA=1 \
-DWITH_CUDNN=ON \
-DOPENCV_DNN_CUDA=ON \
-DENABLE_FAST_MATH=1 \
-DCUDA_FAST_MATH=1 \
-DWITH_CUBLAS=1 \
-DOPENCV_GENERATE_PKGCONFIG=1 \
-DCMAKE_CXX_STANDARD_REQUIRED=ON \
-DCMAKE_CXX_STANDARD_REQUIRED=ON \
-DCMAKE_CXX_STANDARD=17 \
-DCUDA_NVCC_FLAGS="--std=c++17" \
-DOPENCV_EXTRA_MODULES_PATH=../opencv_contrib-dev/modules \
..
执行编译之前建议先查看一下自己可用的线程资源,并根据实际情况合理设置多线程编译,如果有代理的话最好设置一下代理,因为在编译过程中需要下载很多第三方库与模型:
$ export http_proxy="http://192.168.1.100:7890"
$ export https_proxy="http://192.168.1.100:7890"
$ echo $(nporc) # 14
建议在编译时使用 可用线程数-1,避免造成宕机:
$ make -j13
$ sudo make install

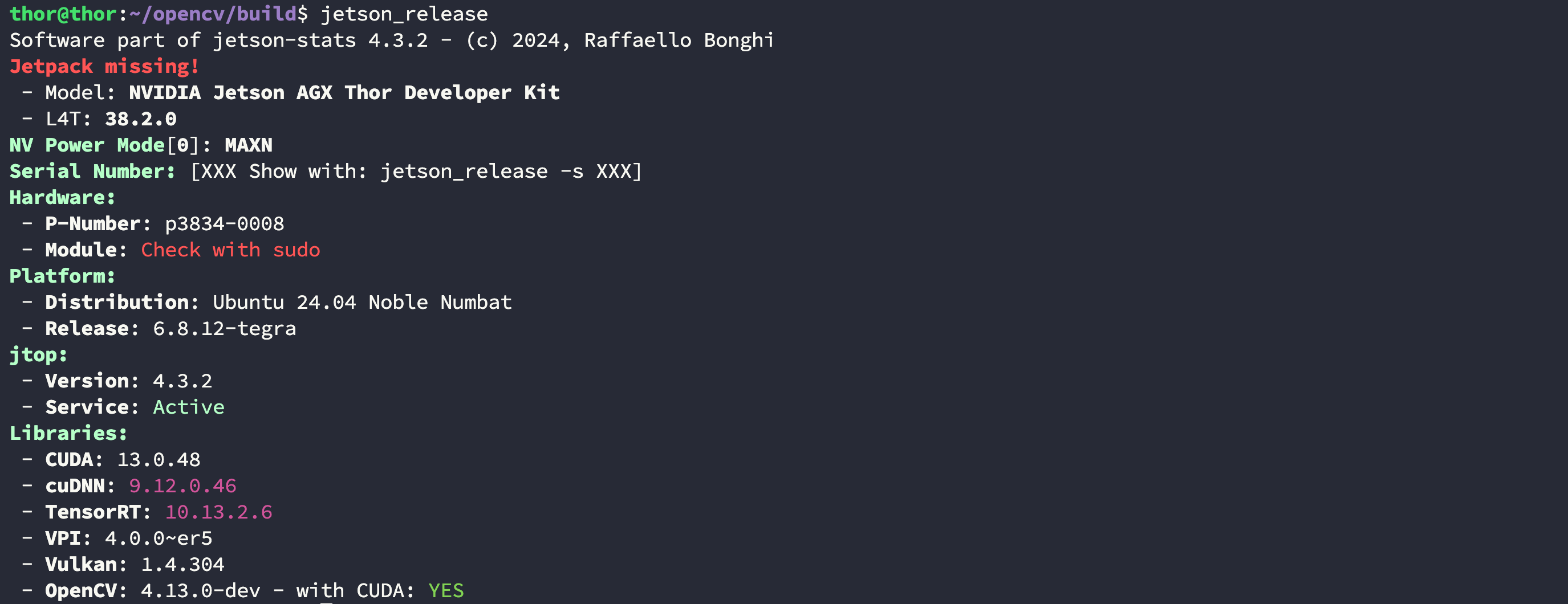
然后用 jetson_release 命令验证安装结果:
$ jetson_release
4.4 安装 ROS rolling
Ubuntu 20.04 及其以上版本仅支持 ROS 2,这里推荐之前使用鱼香ros的一键安装脚本即可:
$ wget http://fishros.com/install -O fishros && . fishros
4.5 安装miniconda
Minicona 也是用官网的方法进行一键安装:
$ wget https://repo.anaconda.com/miniconda/Miniconda3-latest-Linux-aarch64.sh
4.6 安装 Ollama
【注意】:截止 2025年09月05日,如果通过 Ollama 官网提供的安装方法,在拉取的模型运行后会报错,报错内容如下:
Error: model runner has unexpectedly stopped, this may be due to resource limitations or an internal error, check ollama server logs for details

这里使用的安装方法是 Nvidia 社区提供的源码编译,参考文如下:
- Jetson Thor Ollama: Thor ollama[7754]: CUDA error: an internal operation failed
首先需要修改 ~/.bashrc 文件,并将 cuda 库写入到环境变量中:
$ sudo vim ~/.bashrc
# 将下面两行添加至末尾
export PATH=/usr/local/cuda-13.0/bin:$PATH
export LD_LIBRARY_PATH=/usr/local/cuda-13.0/lib64:$LD_LIBRARY_PATH
拉取并编译 go 指定版本并移动到 /usr/local 目录下:
$ cd Downloads
$ wget https://go.dev/dl/go1.24.2.linux-arm64.tar.gz
$ tar -zxvf go1.24.2.linux-arm64.tar.gz
$ sudo mv go /usr/local/
再打开 ~/,bashrc 文件添加 go 的运行库:
$ vim ~/.bashrc
# 添加下面两行至末尾
$ export PATH=$PATH:/usr/local/go/bin
拉取 ollama 源码并编译:
$ cd Downloads
$ git clone https://github.com/ollama/ollama
$ cd ollama && cmake -DCMAKE_CUDA_ARCHITECTURES=110 -B build && cmake --build build
然后运行 ollama,但要注意如果你已经配置了 http_proxy 和 https_proxy,那么运行后就需要先取消代理:
$ export http_proxy=""
$ export https_proxy=""
$ cd Downloads/ollama
$ go run . serve
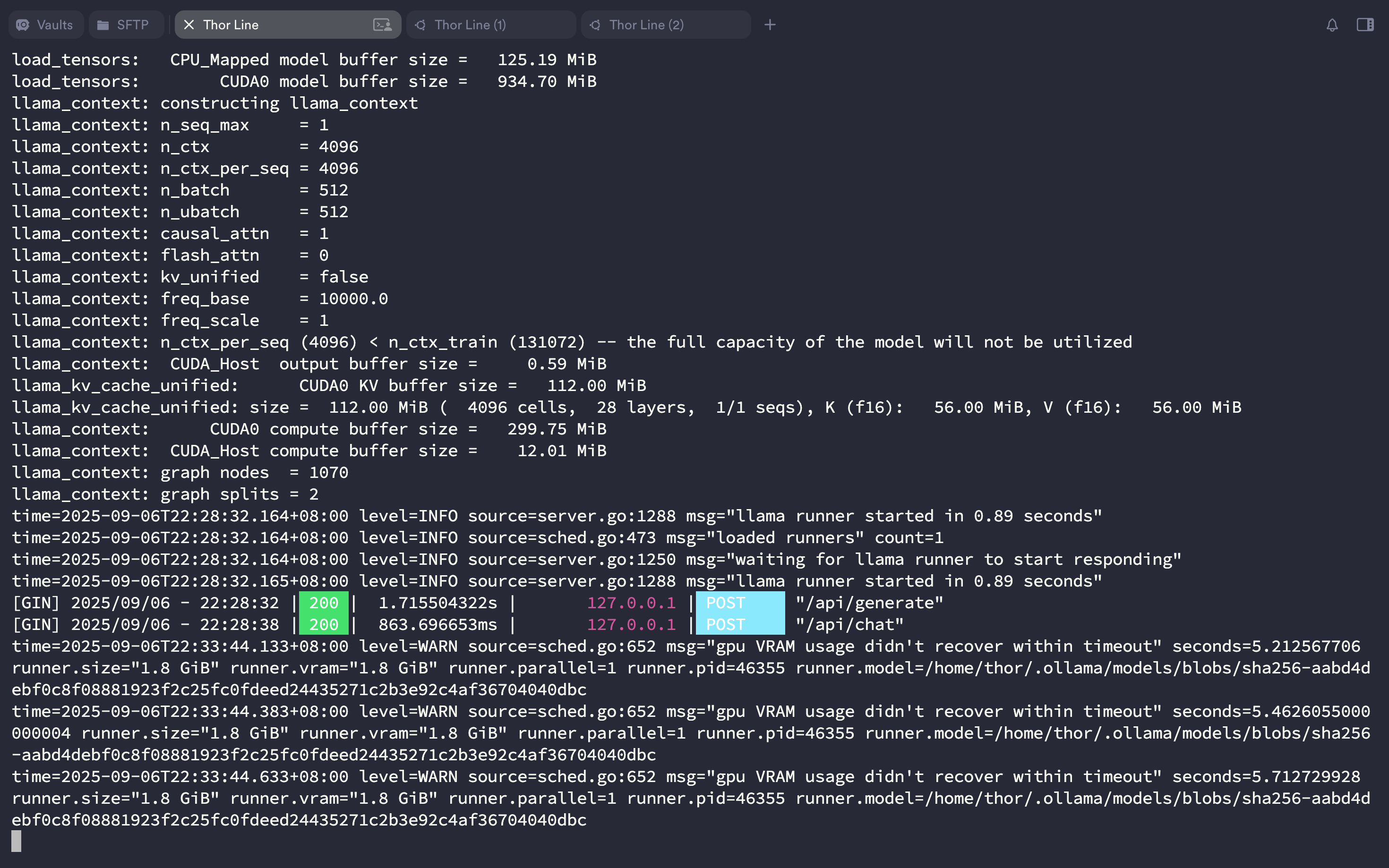
然后 新开一个终端 随便拉取一个小模型测试一下,可以看见运行速度还是非常快的:
$ ollama run deepseek-r1:1.5b
>>> tell me your name

Step5. pytorch 使用
pytorch 是深度学习和端侧部署不可或缺的工具,由于不同的模型可能依赖不同的 python 版本,但 pytorch 的官网目前没有发布 CUDA 13 的 pip 安装版本,因此如果现在想要使用的话这里提供了两个方案。
[推荐] Docker 运行
使用 Docker 运行 pytorch 是最简单且官方验证过的,这部分内容参考了下面这篇博客:
- Nvidia Forums:Thor CUDA available: False
如果你对 pytorch 版本有严格要求,那么可以前往 Nvidia NCG 搜索符合你镜像:
- Nvidia NGC: Search pytorch containers
下面这个命令将拉取一个 21.9 GB 的镜像,包含了 Ubuntu 24.04.2 LTS、python 3.12.3、torch 2.8.0、CUDA 13.0.48 :
- 直接拉取命令:
$ docker run -it \
--net=host \
--runtime nvidia \
--privileged \
--ipc=host \
--ulimit memlock=-1 \
--ulimit stack=67108864 -v $(pwd):/workspace nvcr.io/nvidia/pytorch:25.08-py3 bash
如果你无法下载镜像的话也可以直接从网盘中下载一个然后加载:
- 网盘下载
pytorch.jar文件后使用下面命令加载:
$ docker load < grafana.jar
[测试中] 手动编译
手动编译 pytorch 需要拉取源码,在部分版本上可能会出现依赖问题,这里以编译 python 3.12.0、torch 2.7.0、torchvision 0.22.0 、torchaudio 2.7.0 为例:
编译 torch
- torch Github 连接:https://github.com/pytorch/pytorch
$ git clone --branch v2.7.0 --recursive https://github.com/pytorch/pytorch
创建一个基础 python 环境:
(base) $ conda create -n torch_build python=3.12.0
(base )$ conda activate torch_build
(torch_build) $ pip install pyyaml typing_extensions
安装依赖库:
(torch_build) $ sudo apt-get install -y libopenmpi-dev libomp-dev libopenblas-dev
(torch_build) $ sudo apt install libjpeg-dev libpng-dev zlib1g-dev
(torch_build) $ sudo apt install libavcodec-dev libavformat-dev libswscale-dev
创建一个 torch_env.bash 文件将下面的环境变量写进去:
export USE_CUDA=1
export USE_CUDNN=1
export USE_NCCL=0 # 如果你是Orin则为0,如果有多卡则为1
export MAX_JOBS=14 # 执行编译的线程数
export TORCH_CUDA_ARCH_LIST="11.0" # 当前平台架构,Thor 是11.0
export USE_DISTRIBUTED=1
export USE_QNNPACK=0
export USE_PYTORCH_QNNPACK=0
export PYTORCH_BUILD_VERSION=2.7.0 # 你当前拉下来的torch版本
export PYTORCH_BUILD_NUMBER=1
export CUDA_TOOLKIT_ROOT_DIR=/usr/local/cuda-13
export CUDA_BIN_PATH=/usr/local/cuda-13/bin
export CMAKE_CUDA_COMPILER=/usr/local/cuda-13
export CUDNN_LIB_DIR=/usr/lib/aarch64-linux-gnu
export CUDNN_INCLUDE_DIR=/usr/include
export USE_OPENCV=ON
编译:
(torch_build) $ cd pytorch
(torch_build) $ source torch_env.bash
(torch_build) $ python3 setup.py bdist_wheel --cmake
【注意】:编译 torchvision 之前需要先安装已经编译好的 torch;
(torch_build) $ pip install dist/torch-2.7.0-cp312-cp312-linux_aarch64.wh
编译 torchvision
- torchvision Github 连接:https://github.com/pytorch/vision
(torch_build) $ git clone --branch v0.22.0 --recursive https://github.com/pytorch/vision.git
然后新建一个 vision_env.bash 脚本输入下面的内容:
export USE_CUDA=1
export USE_CUDNN=1
export BUILD_VERSION=0.22.0
export TORCH_CUDA_ARCH_LIST="11.0"
export FORCE_CUDA=1
export FORCE_MPS=1
export USE_MKLDNN=1
export CUDA_HOME=/usr/local/cuda-13
编译 torchvision:
(torch_build) $ cd vision
(torch_build) $ source vision_env.bash
(torch_build) $ python3 setup.py bdist_wheel
安装两个编译好的轮子:
(torch_build) $ pip install
验证是否正确编译:
import torch
import torchvision
torch.__version__
torchvision.__version__
torch.cuda.is_available()
torch.cuda.get_device_name(0)
device = torch.device("cuda")
x = torch.rand(10000, 10000)
print(x.sum().item())
转载自CSDN-专业IT技术社区
原文链接:https://blog.csdn.net/nenchoumi3119/article/details/151148194

