
目录
示例:计算每个部门的薪资总和,并筛选薪资总和大于 20,000 的部门
📘 作者:程彦祖
🕒 更新时间:2025-10-15
📍 适用系统:Oracle Linux / CentOS / RHEL
💡 本文适合开发者和 DBA 初学者手动部署 Oracle 环境,零基础也能完成。
📖 一、前言
在开发或测试环境中,我们经常需要搭建一套独立的 Oracle 数据库环境。
虽然现在很多人使用 Docker 镜像或云数据库,但有时候(例如在企业服务器上),
仍然需要 手动在 Linux 上安装原生 Oracle 数据库。
本教程将手把手带你完成从系统准备到数据库创建的全过程,完全原生安装。
演示环境如下:
| 项目 | 配置 |
|---|---|
| 操作系统 | Oracle Linux 8 / CentOS 7 |
| 数据库版本 | Oracle Database 19c |
| 内存要求 | ≥ 2GB |
| 磁盘空间 | ≥ 20GB |
| 安装模式 | 静默安装(无图形界面) |
⚙️ 二、系统准备
1️⃣ 安装依赖包
yum install -y binutils compat-libcap1 compat-libstdc++-33
gcc gcc-c++ glibc glibc-devel ksh libaio libaio-devel libgcc
libstdc++ libstdc++-devel libXi libXtst make sysstat elfutils-libelf-devel
unixODBC unixODBC-devel smartmontools net-tools unzip🔍 原因解释:
-
libaio、glibc、libstdc++是 Oracle 数据文件 I/O 所需的基础库; -
ksh(Korn shell)是 Oracle 安装程序默认使用的 shell; -
elfutils-libelf-devel是内核符号和调试信息处理库; -
sysstat用于性能监控; -
net-tools提供ifconfig等命令; -
unzip用于解压 Oracle 安装包。
2️⃣ 设置内核参数
编辑 /etc/sysctl.conf:
fs.file-max = 6815744
kernel.sem = 250 32000 100 128
kernel.shmmni = 4096
kernel.shmall = 1073741824
kernel.shmmax = 4398046511104
net.core.rmem_default = 262144
net.core.rmem_max = 4194304
net.core.wmem_default = 262144
net.core.wmem_max = 1048576
fs.aio-max-nr = 1048576
net.ipv4.ip_local_port_range = 9000 65500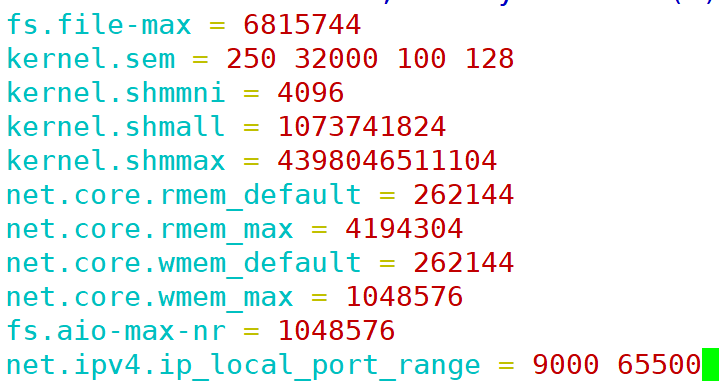
使配置生效:
sysctl -p
3️⃣ 创建 oracle 用户和目录
groupadd oinstall
groupadd dba
useradd -g oinstall -G dba oracle
echo oracle | passwd --stdin oracle
mkdir -p /u01/app/oracle/product/19.3.0/dbhome_1
mkdir -p /u01/app/oracle/oradata
mkdir -p /u01/app/oraInventory
chown -R oracle:oinstall /u01
chmod -R 775 /u01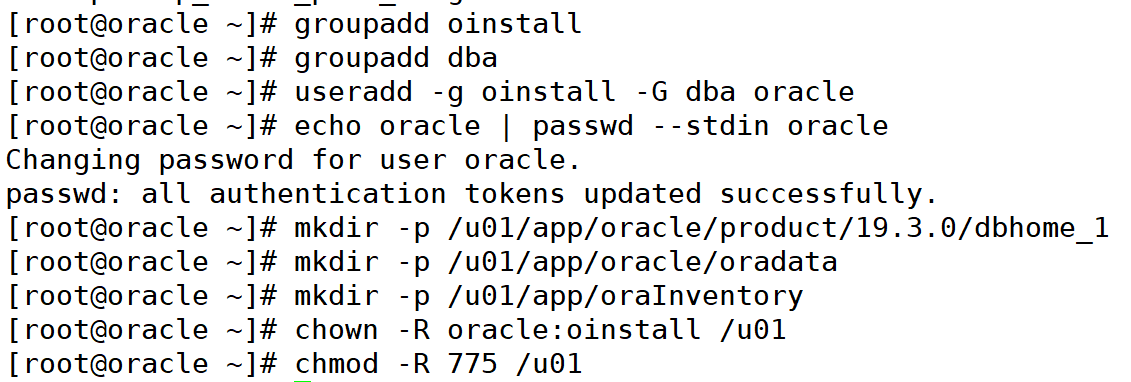
4️⃣ 配置资源限制
编辑 /etc/security/limits.d/oracle-database.conf:
oracle soft nproc 2047
oracle hard nproc 16384
oracle soft nofile 1024
oracle hard nofile 65536
oracle soft stack 10240
oracle hard stack 32768
🧠 三、设置环境变量
切换到 oracle 用户:
su - oracle配置环境变量(编辑 ~/.bash_profile):
export ORACLE_BASE=/u01/app/oracle
export ORACLE_HOME=$ORACLE_BASE/product/19.3.0/dbhome_1
export ORACLE_SID=orcl
export PATH=$PATH:$ORACLE_HOME/bin
使其生效执行:
source ~/.bash_profile📦 四、上传并解压 Oracle 安装包
从官网下载zip安装包
https://www.oracle.com/database/technologies/oracle19c-linux-downloads.html
这个网址打开可以直接下载zip文件,只不过需要注册oracle账号,然后就可以下载;
将下载的zip文件上传至服务器:
unzip LINUX.X64_193000_db_home.zip -d /u01/app/oracle/product/19.3.0/dbhome_1
chown -R oracle:oinstall /u01🚀 五、以静默模式安装
切换到 oracle 用户:
su - oracle
cd $ORACLE_HOME执行安装:
./runInstaller -silent \
-responseFile $ORACLE_HOME/install/response/db_install.rsp \
oracle.install.option=INSTALL_DB_SWONLY \
UNIX_GROUP_NAME=oinstall \
INVENTORY_LOCATION=/u01/app/oraInventory \
ORACLE_HOME=$ORACLE_HOME \
ORACLE_BASE=$ORACLE_BASE \
oracle.install.db.InstallEdition=EE \
oracle.install.db.OSDBA_GROUP=dba \
oracle.install.db.OSOPER_GROUP=dba \
oracle.install.db.OSBACKUPDBA_GROUP=dba \
oracle.install.db.OSDGDBA_GROUP=dba \
oracle.install.db.OSKMDBA_GROUP=dba \
oracle.install.db.OSRACDBA_GROUP=dba \
DECLINE_SECURITY_UPDATES=true✅ 验证修改成功
如果配置正确,执行安装命令后应看到:
Launching Oracle Database Setup Wizard...
[WARNING] [INS-13014] Target environment does not meet some optional requirements.
...
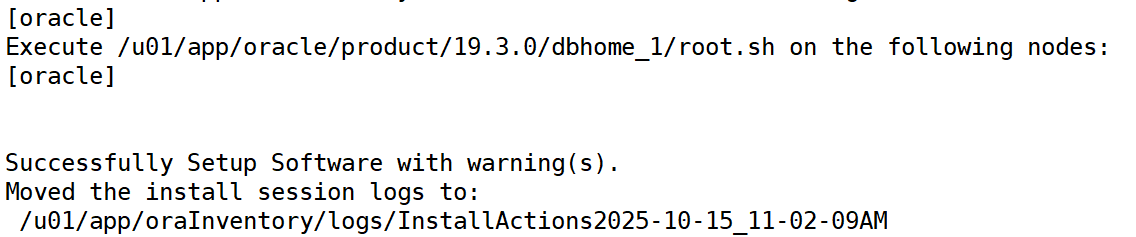
The installation of Oracle Database was successful.接着执行安装结束提示的两个脚本(以 root 运行):
/u01/app/oraInventory/orainstRoot.sh
/u01/app/oracle/product/19.3.0/dbhome_1/root.sh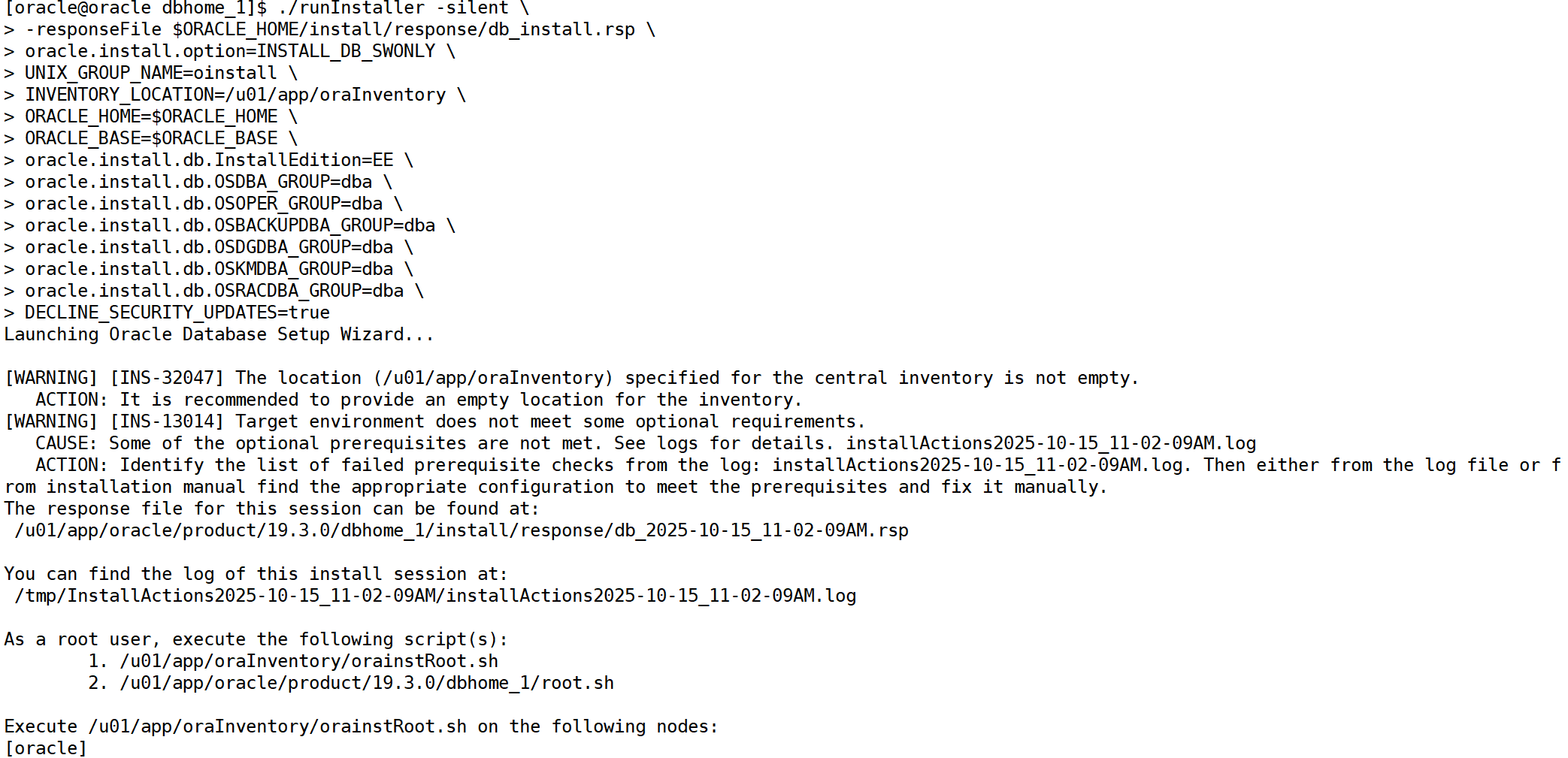

🧱 六、创建数据库实例(静默方式)
进入oracle用户模式执行:
dbca -silent -createDatabase \
-gdbname orcl \
-sid orcl \
-responseFile NO_VALUE \
-templateName General_Purpose.dbc \
-sysPassword oracle \
-systemPassword oracle \
-createAsContainerDatabase false \
-databaseType MULTIPURPOSE \
-memoryMgmtType auto_sga \
-storageType FS \
-datafileDestination '/u01/app/oracle/oradata' \
-redoLogFileSize 50 \
-emConfiguration NONE
✅ 七、验证安装
登录 SQL*Plus:
sqlplus / as sysdba检查数据库状态:
SELECT instance_name, status FROM v$instance;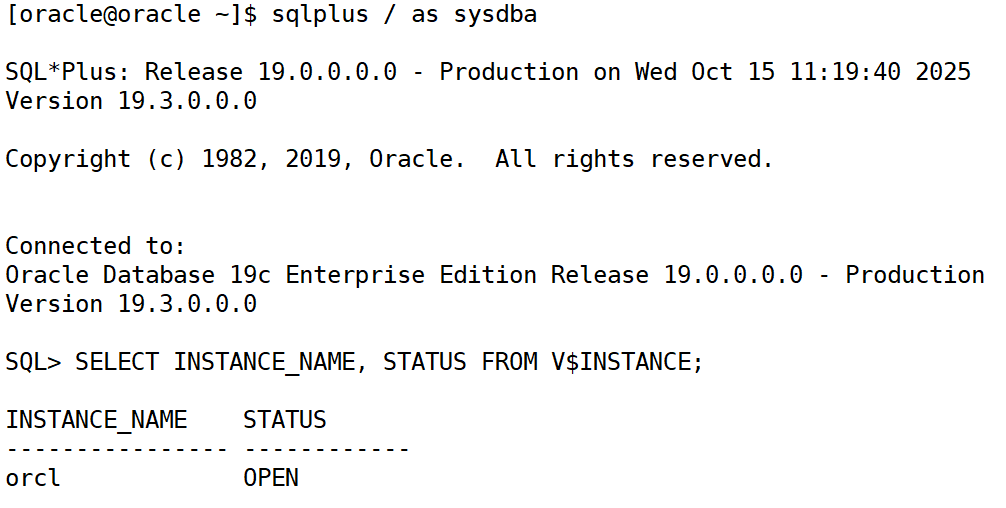
🧹 八、开机自启(可选)
编辑 /etc/oratab,把最后一行改为:
orcl:/u01/app/oracle/product/19.3.0/dbhome_1:Y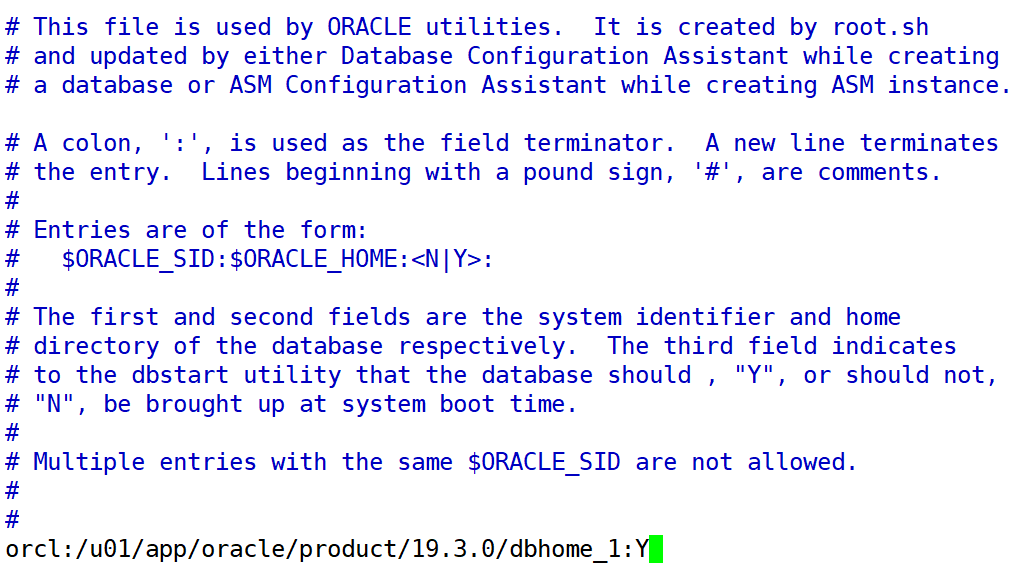
🚀 Oracle 数据库 Demo
1. 登录数据库
首先,确保你以 oracle 用户登录,并使用 sqlplus 连接到数据库实例:
su - oracle
sqlplus / as sysdba2. 创建表
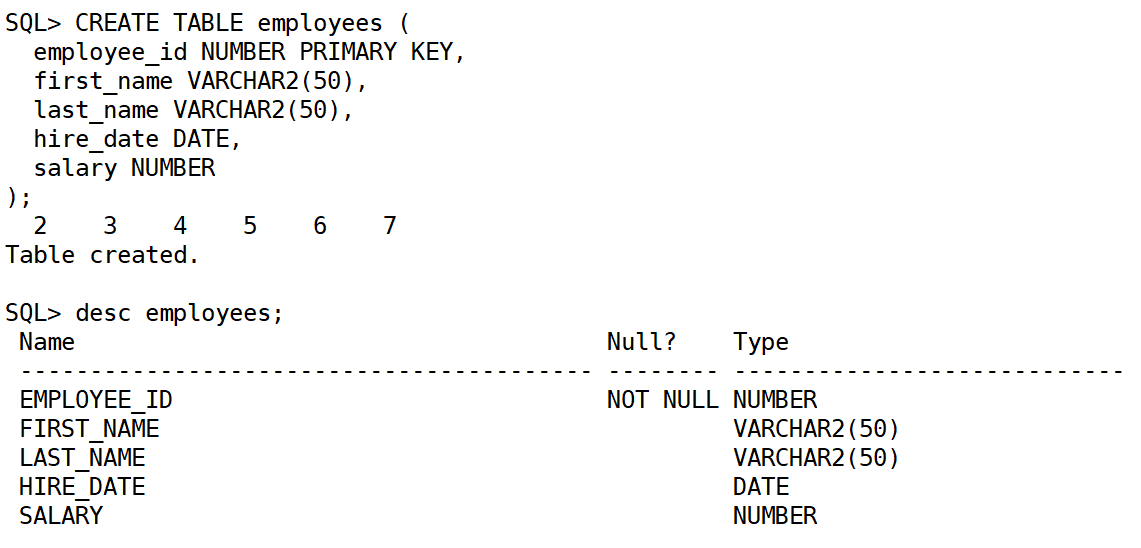
创建一个员工表:
CREATE TABLE employees (
employee_id NUMBER PRIMARY KEY,
first_name VARCHAR2(50),
last_name VARCHAR2(50),
hire_date DATE,
salary NUMBER
);在 SQL*Plus 中,执行 DESC 命令查看表的结构时,默认情况下输出结果并不像在图形界面中那样显示成表格样式,而是以文本形式呈现。
3. 插入数据
INSERT INTO employees (employee_id, first_name, last_name, hire_date, salary)
VALUES (1, 'Alice', 'Johnson', TO_DATE('2023-01-01', 'YYYY-MM-DD'), 8000);
INSERT INTO employees (employee_id, first_name, last_name, hire_date, salary)
VALUES (2, 'Bob', 'Smith', TO_DATE('2023-03-15', 'YYYY-MM-DD'), 9500);
INSERT INTO employees (employee_id, first_name, last_name, hire_date, salary)
VALUES (3, 'Charlie', 'Brown', TO_DATE('2023-07-10', 'YYYY-MM-DD'), 7500);
INSERT INTO employees (employee_id, first_name, last_name, hire_date, salary)
VALUES (4, 'David', 'Wilson', TO_DATE('2023-09-01', 'YYYY-MM-DD'), 10000);4. 查询数据
1.查询所有员工信息:
SELECT * FROM employees;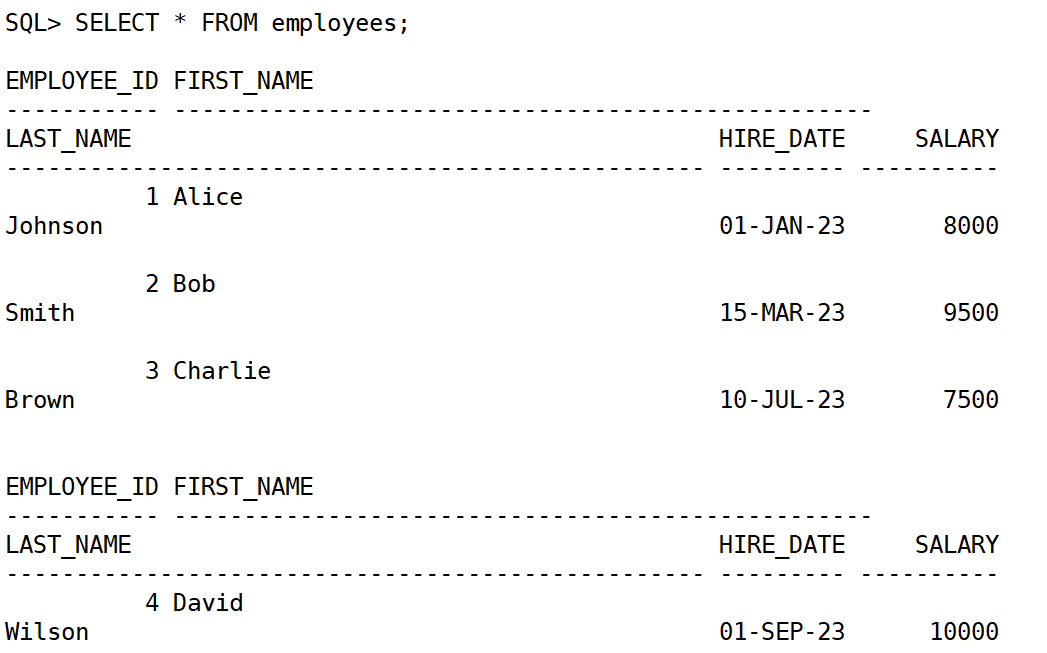
2.查询特定员工(例如,员工 ID 为 2 的员工):
SELECT * FROM employees WHERE employee_id = 2;
3.查询薪水高于 8000 的员工:
SELECT first_name, last_name, salary FROM employees WHERE salary > 8000;
5. 更新数据
例如,增加员工 Bob 的薪水:
UPDATE employees SET salary = 10500 WHERE employee_id = 2;

6. 删除数据
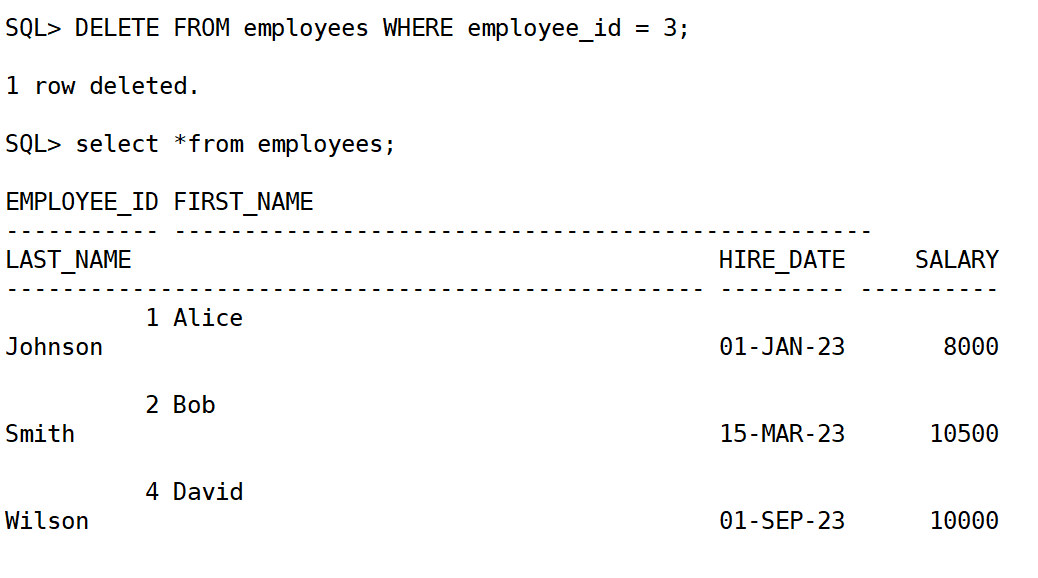
删除员工 ID 为 3 的员工:
DELETE FROM employees WHERE employee_id = 3;
7. 附加 SQL 查询示例
1.查询员工的薪资总和
SELECT SUM(salary) FROM employees;
2.查询薪资的平均值:
SELECT AVG(salary) FROM employees;
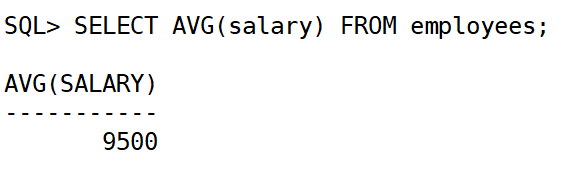
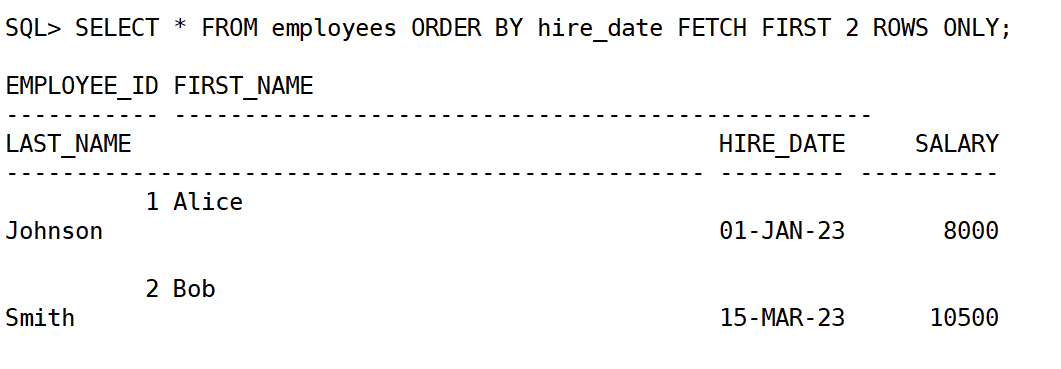
3.按照入职日期排序,显示前 2 个员工:
SELECT * FROM employees ORDER BY hire_date FETCH FIRST 2 ROWS ONLY;
8.筛选数据 (WHERE)
使用 WHERE 子句来筛选符合条件的数据。
SELECT * FROM employees WHERE salary > 8000;

使用逻辑运算符:
-
AND:同时满足多个条件。 -
OR:满足任意一个条件。 -
NOT:排除某些条件
SELECT * FROM employees WHERE salary > 8000 AND EMPLOYEE_ID=2;
使用 BETWEEN 筛选范围:
SELECT * FROM employees WHERE salary BETWEEN 8000 AND 10000;
使用 IN 筛选多个值:
SELECT * FROM employees WHERE EMPLOYEE_ID IN (1, 2, 3);

使用 LIKE 进行模糊查询:
SELECT * FROM employees WHERE first_name LIKE 'A%'; -- 姓名以A开头

9. 排序数据 (ORDER BY)
使用 ORDER BY 子句对查询结果进行排序,默认是按 升序 (ASC),如果需要降序则使用 DESC。
SELECT * FROM employees ORDER BY salary DESC;

10. 限制查询结果 (LIMIT / ROWNUM)
Oracle 不支持 LIMIT 语句,但可以使用 ROWNUM 或 FETCH FIRST 来限制返回的行数。
SELECT * FROM employees WHERE ROWNUM <= 5;

11. 聚合函数 (GROUP BY)
聚合函数 用于对结果集进行汇总、统计或计算。常见的聚合函数有:SUM、AVG、COUNT、MAX、MIN。
示例:计算每个部门的平均薪资
SELECT department_id, AVG(salary) AS avg_salary
FROM employees
GROUP BY department_id;示例:计算每个部门的员工人数
SELECT department_id, COUNT(*) AS num_employees
FROM employees
GROUP BY department_id;
示例:计算每个部门的薪资总和,并筛选薪资总和大于 20,000 的部门
SELECT department_id, SUM(salary) AS total_salary
FROM employees
GROUP BY department_id
HAVING SUM(salary) > 20000;
12. 联接查询 (JOIN)
Oracle 支持多种类型的 联接,用于在查询中连接多个表。常见的联接类型有:INNER JOIN、LEFT JOIN、RIGHT JOIN、FULL JOIN。
示例:INNER JOIN(内联接)
返回两个表中匹配的行:
SELECT e.first_name, e.last_name, d.department_name
FROM employees e
INNER JOIN departments d ON e.department_id = d.department_id;
示例:LEFT JOIN(左外联接)
返回左表所有行,即使右表没有匹配的行:
SELECT e.first_name, e.last_name, d.department_name
FROM employees e
LEFT JOIN departments d ON e.department_id = d.department_id;
示例:RIGHT JOIN(右外联接)
返回右表所有行,即使左表没有匹配的行:
SELECT e.first_name, e.last_name, d.department_name
FROM employees e
RIGHT JOIN departments d ON e.department_id = d.department_id;
示例:FULL JOIN(全外联接)
返回两个表的所有行,不管是否有匹配的行:
SELECT e.first_name, e.last_name, d.department_name
FROM employees e
FULL JOIN departments d ON e.department_id = d.department_id;
13.常用的 Oracle 查询方法:
| 方法 | 描述 |
|---|---|
SELECT | 用于从数据库中提取数据。 |
WHERE | 用于过滤查询结果。 |
ORDER BY | 用于对查询结果进行排序。 |
GROUP BY | 用于将结果按指定字段分组并进行聚合。 |
JOIN | 用于在多个表之间建立关系,进行联接查询。 |
| 子查询 | 在查询中嵌套其他查询,用于更复杂的条件判断。 |
| 视图 | 用于将复杂查询封装为一个虚拟表,简化查询。 |
ROWNUM / FETCH | 用于限制查询结果的行数,进行数据分页。 |
其他的查询语句以及方法后续会更新,喜欢的朋友可以点点关注点点赞哦😁
转载自CSDN-专业IT技术社区
原文链接:https://blog.csdn.net/qq_75004480/article/details/153272903

