



【前言】
在当今数据驱动的时代,数据库是后端开发、数据分析的核心基础设施。
MySQL作为全球最流行的开源关系型数据库,以其高性能、高可靠性和易用性成为了开发者的首选。无论你是后端工程师、数据分析师还是运维人员,掌握 MySQL 都是职场必备技能。 这篇博客将带你从 0 到 1,系统学习 MySQL 的基础知识、库操作、数据类型与表操作四大核心模块,内容包含实战代码、原理剖析和避坑指南。
一、什么是数据库?
1.数据库的定义
数据库(Database)顾名思义就是储存数据的一个容器,就像数组,链表,站和队列…是按照数据结构来组织、存储和管理数据的仓库。数据库技术主要是⽤来解决数据处理的⾮数值计算问题,数据处理的主要内容是数据的存储、查询、修改、排序和统计等.
2.关系型数据库
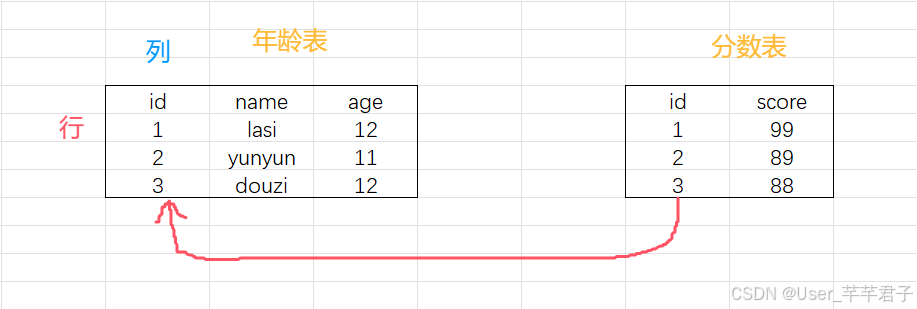
关系型数据库(如 MySQL、Oracle)以表的形式存储数据,表与表之间可以通过关联建立关系,以行和列的形式储存数据,可以理解为一个二维表格模型,这让数据的一致性和完整性得到保障。
如下图:两个表格通过id建立关系,每个数据的行和列都是对应的
3.使用数据库的好处
- 数据持久化:数据库可以将数据保存在存储介质中,即使应⽤程序关闭或服务器重启,数据也不会丢失。
- 数据结构化:数据库能够以结构化的⽅式存储数据,使得数据易于管理和查询。
- 数据完整性:数据库管理系统(DBMS)提供了数据完整性的保障,确保数据的准确性和⼀致性。
- 并发控制:数据库可以处理多个⽤⼾或进程同时访问和修改数据,同时确保数据的⼀致性。
- 安全性:数据库提供了多种安全机制,如访问控制、加密等,保护数据不被未授权访问。
- 可扩展性:随着数据量的增⻓,数据库可以⽔平或垂直扩展,以适应不断增⻓的数据需求。
- 备份和恢复:数据库⽀持数据的备份和恢复,以防数据丢失或损坏。
- 查询优化:数据库系统提供了⾼效的查询优化器,可以快速执⾏复杂的查询操作。
- 事务管理:⼤部分关系型数据库都⽀持事务,确保⼀系列操作要么完全成功,要么完全失败,提⾼ 了操作的可靠性。
- 多⽤⼾⽀持:数据库允许多个⽤⼾同时访问和操作数据,适合多⽤⼾环境。
4.数据库操作
要使用MySQL首先要安装配置好环境,哎,我安装了不下8次,说出来都丢人。but相信很多小伙伴和我一样,都卡在了第一步,安装教程就不说了,市面上很多,都能搜到。
这是MySQL自带的客户端,因为编码方式不同所以有两个
- 第一个是utf8mbt编码支持完整的 Unicode 字符集,包括中文、emoji 等。
- 第二个是系统本地编码

打开之后要先输入密码,切记密码别搞的太复杂,没人会盗取你的数据。如果忘记了密码就只能重装了。
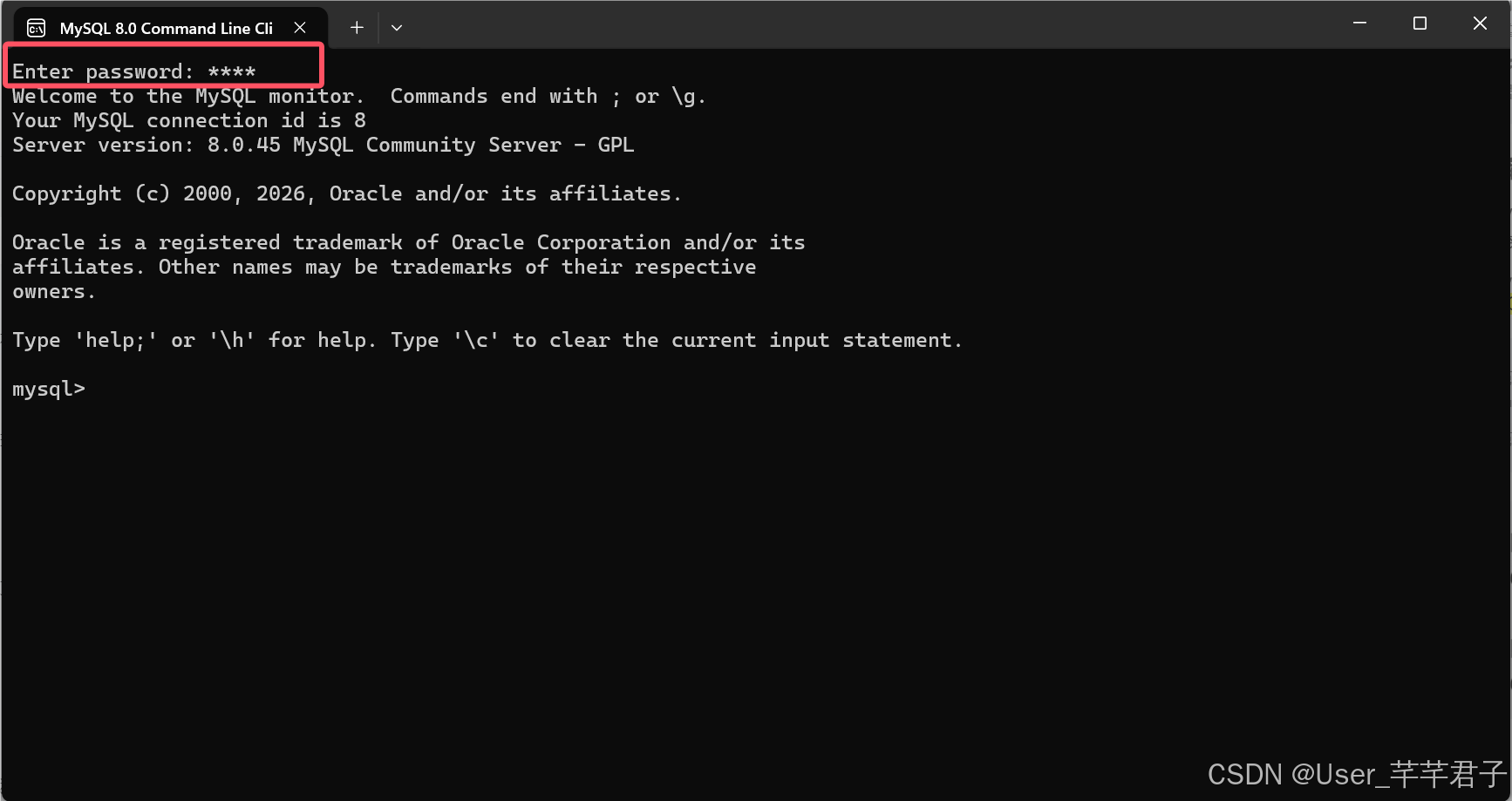
这个黑框框用的属实不舒服,我用的图形化客户端是navicat,业内⼴泛使⽤的可视化客⼾端⼯具,这个版本免费,(MySQL也自带了一个图形化客户端workbench)都可以用

打开以后先建立链接,选择我们使用的MySQL
输入连接名称和密码就欧克了
二、库的操作
1.查看数据库
1.1语法
show database;
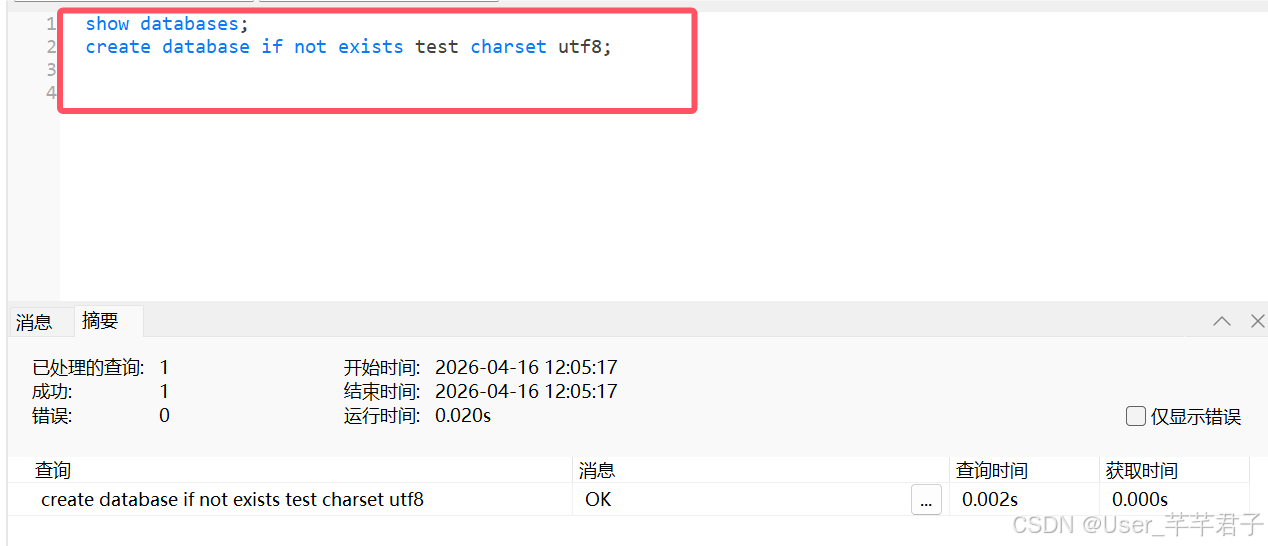
2.创建数据库
2.1 语法
create database [if not exists] name [charset utf8];
- name不能和关键字重复,除非使用反引号
name; - if not exists : 判断重复;
- charset utf8:指定字符集(保存汉字需要指定);
mysql中utf8是utf8完整体的子集;
utf8mb4–>完全体utf8;
3.选中数据库
use 数据库名;
4.删除数据库(危险操作)
drop database 数据库名;
选中本行:
光标在行首,shift + end;
光标在行尾,shift + home;
三、数据类型
- 数据值类型;
- 字符串类型;
- 二进制类型;
- 日期类型
1.类型列表
| 类型 | 大小 | 说明 |
|---|---|---|
| tinyint | 1byte | 取值范围-2^7 ~ 2^7-1 ,⽆符号取值范围2^8-1 |
| smallint | 2byte | 取值范围-2^15 ~ 2^15-1 ,⽆符号取值范围2^16-1 。 |
| int | 4byte | 取值范围 -2^31 ~ 2^31-1 ,⽆符号取值范围2^32-1 |
| bigint | 8byte | 取值范围-2^63 ~ 263-1,⽆符号取值范围264-1 |
| double | 8byte | 双精度浮点型,M是总位数,D是⼩数点后⾯的位数,⼤约可以精确到⼩数点后15位。 |
| decimal | 动态 | 不存在精度损失,M是总位数,D是⼩数点后的位数。DECIMAL的最⼤位数(M)为65,最⼤⼩数位数(D)为30。如果省略M,则默认为10,如果省略D,则默认为0。M中不计算⼩数点和负数的-号,如果D为0,则值没有⼩数点和⼩数部分。 |
decimal:能准确表示浮点数,但存储空间大,运算速度慢
2.字符串类型
| 类型 | 说明 |
|---|---|
| varchar(更实用) | 可变⻓度字符串,M表⽰字符最⼤⻓度,取值范围0 ~ 65535,有效字符个数取决于实际字符数和使⽤的字符集 |
| longtext | ⼤⽂本类型,最⼤⻓度为4,294,967,295即4GB(2^32-1)个字节,有效字符个数取决于使⽤的字符集 |
| mediumtext | 中⽂本类型,最⼤⻓度为16,777,215(2^24-1)个字节,有效字符个数取决于使⽤的字符集 |
二进制数据:图片,视频,音频(一般不会直接存储在数据库,而是按照文件的方式存储在硬盘上,把文件路径作为字符串填写到数据库表中)
3.日期类型
| 类型 | 大小 |
|---|---|
| TIMESTAMP[fsp] | 4bytes |
| DATETIME(fsp) | 8bytes |
(⽇期类型和时间类型的组合)
四、表的操作
1.语法
show tables;
2. 创建表
2.1语法
create [temporary] table [if not exists] test(
field datatype[约束][comment ' 注解内容'],
...
)[engine 存储引擎] [charset set 字符集] [collate 排序规则];
- temporary : 临时表;
- field : 列名;
- datatype : 数据类型;
- comment : 注释;
- engine : 存储引擎(MySQL服务器很多模块中的一个,负责数据如何在硬盘上存储)MySQL是把数据保存在硬盘上,在硬盘上创建了文件,文件也是保存在硬盘上的。
- charset set :字符集,不指定则使⽤默认字符集;
- collate :排序规则,不指定则使⽤默认排序规则;
3.查看表结构
desc 表名;
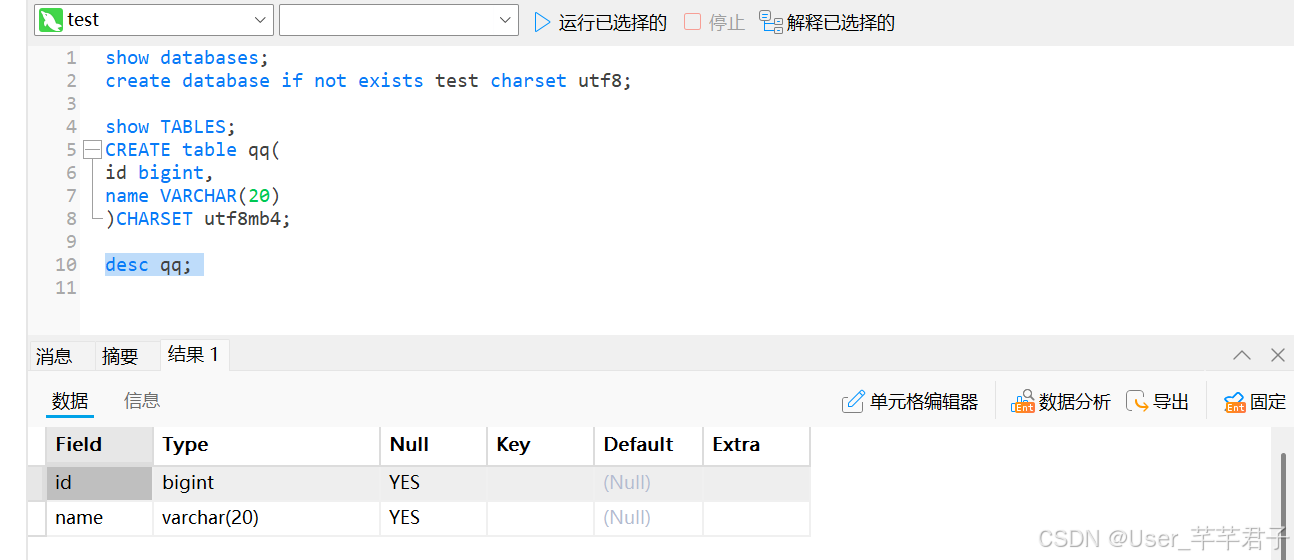
Null:表示表中这一列是否可以为空,不填
4.修改表(低频操作)
alter table 表名 动作 列名 类型;
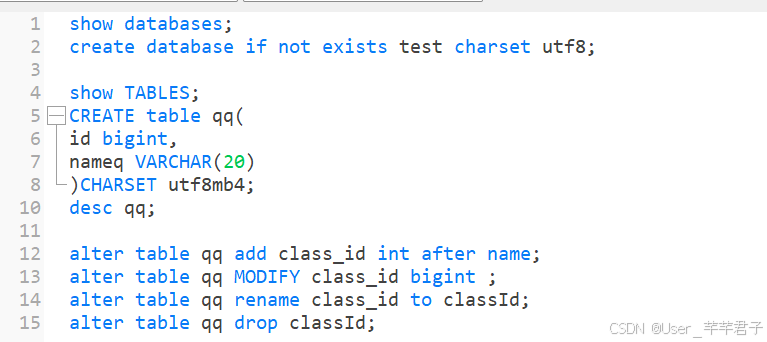
- add : 添加列;
- modify : 修改现有的列;
- drop : 删除现有的列;
- rename : 重命名
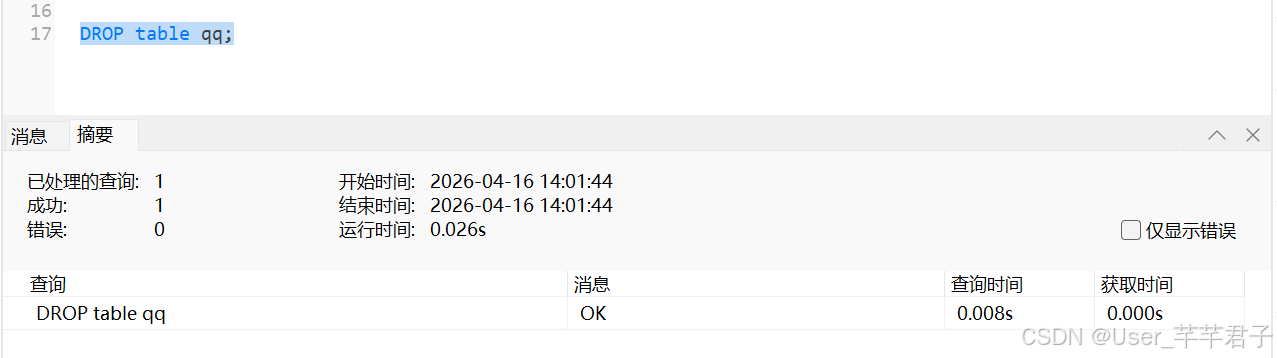
5.删除表
drop table 表名;
五、增删改查
CRUD
- Create;
- Retrieve;
- Update;
- Delete
1.新增Create
insert into 表名 values();
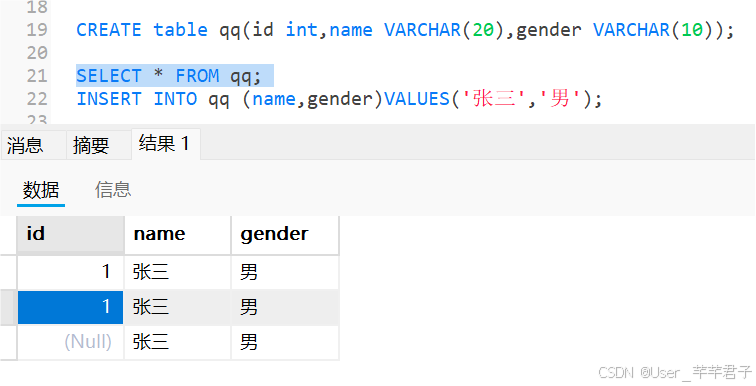
sql中存在类型转换,即使你values 后面写的值,类型上不是严格匹配,但MySQL会尽力尝试转换,转换失败才会保存
2.检索Retrieve
2.1全列查询
select*from 表名;
2.2 指定列查询
select 列名,列名...from 表名;
2.3 表达式查询
select 表达式,列名 from 表名;
2.4 指定别名查询
select 表达式 as 别名 from 表名;
2.5 查询时去重
select distinct 列名 from 表名;
2.6 条件查询
select 列名 from 表名 where 条件;
- 遍历每一条记录;
- 取出记录代入条件;
- 条件成立,这一行就放到最终结果里;
- 条件不成立,pass,下一条
2.7 排序查询(针对查询结果排序)
select 列名 from 表名 order by 列名,列名...;
-
默认是升序排序,放在前面的列优先级更高空值是最小的;也可以写asc显式指定升序,asc可省略;
-
针对临时表操作,不影响数据库服务器硬盘上存储的原始数据
-
如果一个sql没有指定order by ,此时意味着查询结果的顺序是未定义的;
-
order by可以使用别名作为排序规则;
-
order by 执行顺序是在表达式计算之后的,别名先定义出来了,然后才运行到order by;
2.8 分页查询
就相当于我们用浏览器搜索一个东西,然后会有很多搜索结果,分成n个页面。如果都放一个页面,用户看不过来还影响程序效率
select 列名 from 表名 where 条件 order by 列名 limit N offset M;
-
limit 子句来实现分页查询:获取N条数据;
-
offset : 偏移量,相当于数组下标;从第M条记录开始,往后获取N条记录
3.Update修改
update 表名 set 列名 = 值 where 条件 order by 列名 limit N;
-
这里修改的不是临时表,而是服务器硬盘原始数据了;
-
=:相当于赋值了; -
以原值的基础上做变更时,不能使⽤math+=30这样的语法;
-
不加where条件时,会导致全表数据被列新,谨慎操作
4.delete 删除
delete from 表名 where 条件 order by 列名 limit N;
where 条件 order by 列名 limit N:如果不写这些条件等子句限定要删除哪些内容,就会删除所有数据,OMG了~
5.截断表
更快速的清空表
TRUNCARTE [TABLE] name;
6.插入查询结果
查询出来的列数和类型要和前面插入的表结果匹配
insert into 被插入表名 select * from 要插入的表名;
7.聚合函数
查询时,指定表达式---->进行列与列之间运算
聚合查询,就是行与行之间运算
select count(行名) from 表名;
先执行select (行名) from 表名;
再对结果进行count;
常用函数
| 函数 | 说明 |
|---|---|
COUNT([DISTINCT] expr) | 统计查询结果的数据数量 |
SUM([DISTINCT] expr) | 计算查询结果的数据总和(仅适用于数字类型) |
AVG([DISTINCT] expr) | 计算查询结果的数据平均值(仅适用于数字类型) |
MAX([DISTINCT] expr) | 返回查询结果中的最大值(仅适用于数字类型) |
MIN([DISTINCT] expr) | 返回查询结果中的最小值(仅适用于数字类型) |
8.Group by分组查询(聚合查询的一个环节)
把表的若干列进行分组,需要指定分组依据
select count(行名) from 表名 group by 指定的列;
having子句
使⽤group by对结果进⾏分组处理之后,对分组的结果进⾏过滤时,不能使⽤使⽤where,要使用having ⼦句
Having与Where的区别
-
Having⽤于对分组结果的条件过滤
-
Where⽤于对表中真实数据的条件过滤
9.内置函数
9.1 日期函数
| 函数 | 说明 |
|---|---|
CURDATE() | 返回当前日期,同义词:CURRENT_DATE, CURRENT_DATE() |
CURTIME() | 返回当前时间,同义词:CURRENT_TIME, CURRENT_TIME([fsp]) |
NOW() | 返回当前日期和时间,同义词:CURRENT_TIMESTAMP, CURRENT_TIMESTAMP() |
DATE(data) | 提取 date 或 datetime 表达式的日期部分 |
ADDDATE(date,INTERVAL expr unit) | 为日期添加时间间隔,同义词:DATE_ADD() |
SUBDATE(date,INTERVAL expr unit) | 为日期减去时间间隔,同义词:DATE_SUB() |
DATEDIFF(expr1,expr2) | 计算两个日期的天数差(expr1 - expr2) |
9.2 字符串处理函数
| 函数 | 说明 |
|---|---|
CHAR_LENGTH(str) | 返回给定字符串的长度,同义词 CHARACTER_LENGTH() |
LENGTH(str) | 返回给定字符串的字节数,与当前使用的字符编码集有关 |
CONCAT(str1,str2,...) | 返回拼接后的字符串 |
CONCAT_WS(separator,str1,str2,...) | 返回拼接后带分隔符的字符串 |
LCASE(str) | 将给定字符串转换成小写,同义词 LOWER() |
UCASE(str) | 将给定字符串转换成大写,同义词 UPPER() |
HEX(str),HEX(N) | 对于字符串参数str,HEX()返回str的十六进制字符串表示形式;对于数字参数N,HEX()返回一个十六进制字符串表示形式 |
INSTR(str,substr) | 返回子串第一次出现的索引 |
INSERT(str,pos,len,newstr) | 在指定位置插入子字符串,最多不超过指定的字符数 |
SUBSTR(str,pos)SUBSTR(str FROM pos FOR len) | 返回指定的子字符串,同义词 SUBSTRING(str,pos)、SUBSTRING(str FROM pos FOR len) |
REPLACE(str,from_str,to_str) | 把字符串str中所有的from_str替换为to_str,区分大小写 |
STRCMP(expr1,expr2) | 逐个字符比较两个字符串,返回 -1,0,1 |
LEFT(str,len),RIGHT(str,len) | 返回字符串str中最左/最右边的len个字符 |
LTRIM(str),RTRIM(str),TRIM(str) | 删除给定字符串的前导、末尾、前导和末尾的空格 |
TRIM([{LEADING TRAILING BOTH} remstr FROM] str) | 删除给定字符串的前导,末尾或前导和末尾的指定字符串 |
五、总结
本文系统梳理了 MySQL 入门核心知识,从数据库基础概念、库的创建 / 查看 / 删除操作,到数据类型、表的创建 / 维护,再到增删改查(CRUD)全流程,涵盖查询、排序、分页、分组聚合等高频实操,帮零基础读者快速搭建 MySQL 知识体系,轻松掌握数据库开发必备技能。
转载自CSDN-专业IT技术社区
原文链接:https://blog.csdn.net/user340/article/details/157909078

