
边坡稳定性预测是岩土工程中的核心问题。传统的极限平衡法或数值分析法往往受限于地质条件的复杂性和参数不确定性。BP神经网络虽能逼近任意非线性映射,但极易陷入局部极小、收敛慢,且初始权值和阈值的选择对性能影响巨大。遗传算法(GA) 是一种全局寻优的进化算法,用其优化BP网络,能有效克服上述缺陷,显著提升预测精度和泛化能力。
以下是这一方法的完整解析。
一、为什么用 GA 优化 BP 网络
| BP 神经网络的缺点 | GA 的优化作用 |
|---|---|
| 随机初始权值和阈值,易致网络不稳定 | 在全局解空间中搜索最优初始权值和阈值,为BP训练提供理想起点 |
| 梯度下降法易陷入局部极小值 | 利用选择、交叉、变异等操作,具备跳出局部最优的全局搜索能力 |
| 对初始值敏感 | 不依赖梯度信息,仅用适应度函数评价个体,鲁棒性强 |
核心思想:先用遗传算法对 BP 网络的初始权值和阈值进行全局预寻优,再将找到的最优个体赋值给 BP 网络,由 BP 算法进行局部精细训练。这是一种GA粗调 + BP精调的混合策略。
二、预测模型的完整构建流程
整个流程可分为数据准备、GA优化、BP训练与预测三个主要阶段。
1. 确定边坡稳定性影响因素与样本数据
根据工程经验和机理分析,选取影响边坡稳定的关键参数作为输入变量,如:
- 重度γ、粘聚力c、内摩擦角φ、坡角α、坡高H、孔隙水压力比ru等。
输出为稳定性系数Fs(回归问题)或稳定状态类别(分类问题,如稳定、基本稳定、危险)。
需要对原始数据进行归一化处理,映射到[-1,1]或[0,1]区间。
2. 设计BP神经网络拓扑结构
- 输入层节点数 = 影响因子个数
- 输出层节点数 = 预测值个数(通常1个)
- 隐含层:常用单隐含层,节点数通过试凑法或经验公式确定,如m=n+l+am = \sqrt{n+l} + am=n+l+a (n输入,l输出,a为1~10常数)。
- 传递函数:隐含层常用tansig或logsig,输出层常用purelin。
3. 遗传算法优化权值与阈值
这是核心步骤,将BP网络的所有待定参数编码为染色体。
① 编码与种群初始化
- 采用实数编码,每个个体为包含所有权值和阈值的实数向量。
- 个体长度 = (输入层节点数×隐含层节点数) + 隐含层阈值数 + (隐含层节点数×输出层节点数) + 输出层阈值数。
- 随机生成初始种群,每个基因取值范围通常设为[-1,1]。
② 适应度函数设计
适应度是评判个体优劣的唯一依据。目标是使网络预测误差最小,因此将误差的倒数或负值作为适应度:
F=11+E
F = \frac{1}{1 + E}
F=1+E1
其中 EEE 为训练集或验证集的均方误差(MSE):
E=1N∑k=1N(yk−y^k)2
E = \frac{1}{N} \sum_{k=1}^{N} (y_k - \hat{y}_k)^2
E=N1k=1∑N(yk−y^k)2
或加入权值衰减项防止过拟合。
③ 遗传操作
- 选择:用锦标赛选择或轮盘赌策略,保留精英个体直入下一代。
- 交叉:实数编码常用算术交叉,如 Xchild=αXparent1+(1−α)Xparent2X_{child} = \alpha X_{parent1} + (1-\alpha) X_{parent2}Xchild=αXparent1+(1−α)Xparent2。
- 变异:以较小概率对基因施加高斯扰动或均匀随机扰动,增加种群多样性。
- 重复进化,直到达成最大代数或适应度收敛。
④ 获取最优初始参数
记录末代种群中适应度最高的个体,解码得到最优的初始权值和阈值,赋值给BP网络。
4. BP网络精细训练与预测
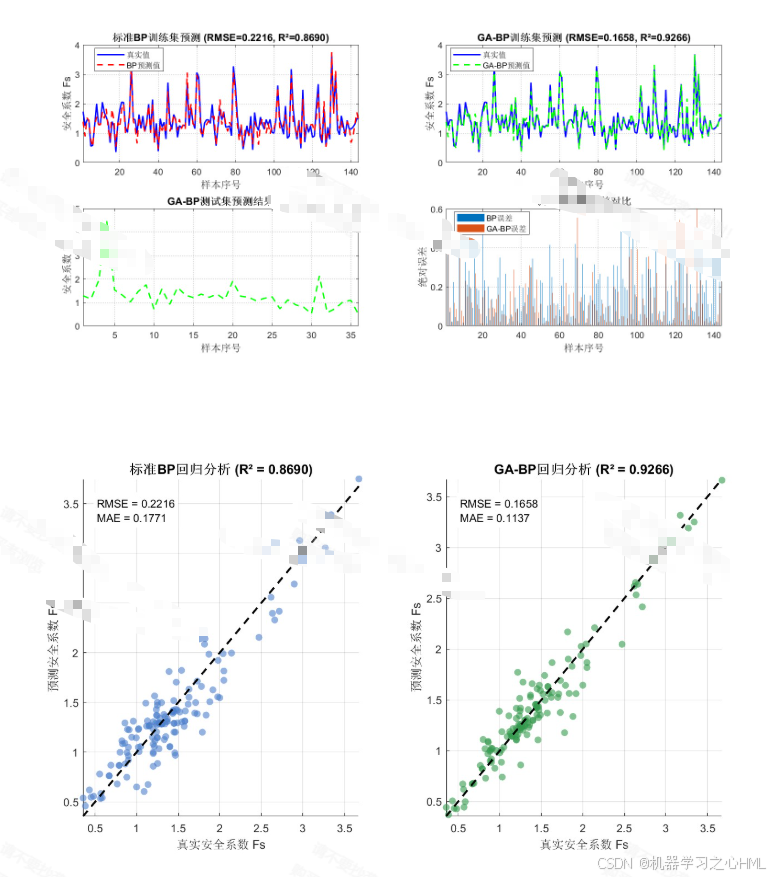
用训练数据对获得了优良初始值的BP网络进行常规训练(如LM算法或梯度下降)。收敛后,用测试样本评估模型泛化性能(如MAPE、相关系数R²等)。最终模型可用于新边坡的稳定性预测。
三、该方法的核心优势与注意事项
✅ 优势
- 预测精度高、泛化能力强:GA-BP比单一BP、传统统计模型或经验公式的误差显著降低。
- 自适应性:能自动从数据中学习复杂非线性关系,无需人为建立显式数学方程。
- 鲁棒性强:对参数扰动和部分数据含噪的情况表现出较好的容错能力。
⚠️ 关键注意事项
- 数据质量与数量:高质量、覆盖范围广的样本是根本。样本数过少可能过拟合。
- 过拟合防治:可采用“训练集+验证集+测试集”划分,在GA适应度评价时关注验证集误差,或加入正则项。
- 效率权衡:GA全局搜索耗时较长,当网络规模庞大时计算成本急剧上升。可合理设置种群大小与进化代数。
- 参数多样性:除基本力学参数,必要时可引入岩体结构、节理发育程度等定性指标的量化描述。
- 与其他算法对比:可进一步与粒子群优化BP(PSO-BP)、支持向量机、随机森林等模型比较,验证所选方法的优越性。
四、一个简化的代码框架(Matlab伪代码)
% 1. 数据准备
inputs = ...; targets = ...;
[input_train, input_test, output_train, output_test] = divide_data(inputs, targets);
% 2. BP网络结构定义
inputnum = size(input_train,1); hiddennum = 10; outputnum = size(output_train,1);
net = newff(input_train, output_train, hiddennum);
% 3. 遗传算法优化
% 计算个体长度
num_all = inputnum*hiddennum + hiddennum + hiddennum*outputnum + outputnum;
% 设置GA参数
options = optimoptions('ga', 'PopulationSize', 50, 'MaxGenerations', 100, ...
'CrossoverFraction', 0.8, 'MutationRate', 0.1);
% 适应度函数(误差越小,适应度越大)
fitnessFcn = @(x) ga_bp_fitness(x, inputnum, hiddennum, outputnum, input_train, output_train);
% 执行GA
[best_x, fval] = ga(fitnessFcn, num_all, [], [], [], [], -ones(1,num_all), ones(1,num_all), [], options);
% 4. 将最优个体赋给BP,训练并预测
net = assign_best_weights(net, best_x, inputnum, hiddennum, outputnum); % 自定义函数
net = train(net, input_train, output_train);
y_pred = sim(net, input_test);
% 计算评价指标,绘图...
五、总结
基于遗传算法优化BP神经网络的边坡稳定性预测,本质是利用GA的全局搜索能力为BP寻找最佳的初始连接权和阈值,从而实现“全局粗搜索 + 局部精搜索”的有机结合。该方法充分发挥了两种算法的长处,在高效处理边坡非线性、多因素耦合问题上表现出色,已成为岩土工程智能分析领域中一种成熟且有效的解决方案。
转载自CSDN-专业IT技术社区
原文链接:https://blog.csdn.net/2301_82065768/article/details/160603193

