
前言
目前基于大规模离线数据预训练的通用机器人策略如VLA,虽然具有很强的基础能力,但仅靠离线数据不足以让它们在真实的复杂环境中直接稳健地部署
而在真实世界中部署时,机器人会面临数据分布偏移、长尾失效、任务多样性变化等问题,这些是固定的离线演示数据集无法完全覆盖的
来自的研究者提出,部署不应被视为模型训练的终点,而应被视为持续改进策略的数据来源 。作者提出,要获得高性能,策略必须能够从部署经验中不断学习,形成“数据飞轮”
而对应的解决方案便是 LWD (Learning While Deploying),这是一个面向集群级部署的离线到在线(Offline-to-Online)RL 框架
- 系统闭环:该框架将“部署、共享物理经验、策略改进、重新部署”这一过程形成了一个闭环
- 数据飞轮效应:通过在多台机器人(集群)上部署一个共享模型,机器人自主收集在线交互数据(包含成功、失败、恢复、人类干预等),这些新数据与离线经验回放缓冲区混合以更新模型,更新后的模型再重新部署以收集更丰富的数据
- 两阶段训练:
阶段 1(离线预训练):在静态离线缓冲区『包含人类专家演示、历史策略回放数据、人类探索失败模式的游玩数据』上训练策略、评论家(Critic)和价值模型,为部署提供良好的初始化
阶段 2(在线持续后训练):将策略部署到机器人集群进行自主运作,将收集到的在线数据(含人类干预)与离线数据以 1:1 的比例混合,持续更新模型并定期将新权重同步给机器人集群
而集群收集的数据存在异构、奖励稀疏且包含大量失败或部分成功案例的问题 。为了能在这种复杂数据上稳定训练基于流匹配的生成式 VLA 模型,LWD 结合了两个关键算法:
A. 价值学习:DIVL (Distributional Implicit Value Learning)
- 抛弃标量,预测分布:在传统的隐式Q学习(IQL)中,模型预测的是一个标量期望值,这容易将集群数据中罕见但可复现的高回报(成功)行为与大量的失败行为平均化,从而掩盖了学习信号
DIVL 改为学习动作回报的概率分布,从而保留了高回报的多模态特征 - 分位数目标提取:DIVL 提取该分布的特定分位数(Quantile)作为时间差分(TD)的自举目标,这样可以在不查询分布外动作的情况下提供稳定的学习信号
- 自适应乐观度 (
):在混合任务中,LWD 根据预测价值分布的归一化熵(不确定性)来动态调整分位数参数
当模型对状态不确定(分布发散)时,降低
B. 策略提取:QAM (Q-learning via Adjoint Matching)
- 梯度反传的困境:VLA 策略使用了生成式的流模型(Flow-based policy),如果直接将 Critic 的动作梯度穿过流模型的多步生成过程进行反向传播,不仅计算昂贵,而且极不稳定
- QAM 的解决方式:QAM 将这种轨迹级别的策略优化转化为了沿参考流的局部回归目标 。它利用 DIVL 学到的 Critic 梯度在动作终点初始化伴随状态,并将其转化为对流模型每一步的直接监督信号
这使得生成式 VLA 能够稳定地吸收从强化学习中获得的价值提升
第一部分 Learning while Deploying: Fleet-ScaleReinforcement Learning for Generalist RobotPolicies
1.1 引言与相关工作
1.1.0 与π*0.6中RECAP的相同与不同
π*0.6 中的 RECAP 和这篇论文提出的 LWD 目标非常相似,但在底层技术路线和工程落地的思路上有着本质的不同
简单来说,两者都是为了解决同一个难题:VLA 模型在预训练之后,如何利用机器人在真实部署中产生的海量、杂乱的数据(包括成功、失败、部分成功、人类干预控制)来进行持续提升(Post-training)
以下是它们的核心异同点:
本质相同点
-
超越纯粹的模仿学习:两者都不再像 SFT (监督微调) 那样只能被动地模仿完美的专家演示数据。它们都能利用自主运行(Autonomous rollouts)产生的数据,即使这次运行最终失败了,它们也能从中榨取价值
-
引入价值函数(Value Function):两者都训练了一个额外的价值模型/Critic,用来评估某一个状态或动作到底“有多好”,以此作为改进策略的依据
本质不同点
这才是区分两者的关键。为了保证工程落地时的稳定性与上限,它们选择了截然不同的更新策略:
1. 策略更新机制:优势过滤的模仿学习 vs. 端到端强化学习梯度(核心差异)
- RECAP:本质上是一种基于优势加权的模仿学习 (Advantage-Conditioned Imitation Learning)
它使用学到的价值模型来计算轨迹或动作的优势Advantage,以此来判断这步动作好不好
然后,它设定一个阈值来进行数据过滤
接着,拿着这些被筛选出的“好数据”去执行标准的模仿学习。从工程维稳的角度来看,这种将 RL 降级为“自动挑选好数据”,最后依然走模仿学习路线的做法,往往更容易控制,不容易把模型训崩。但它的上限受限于你能挑出的最好数据的水平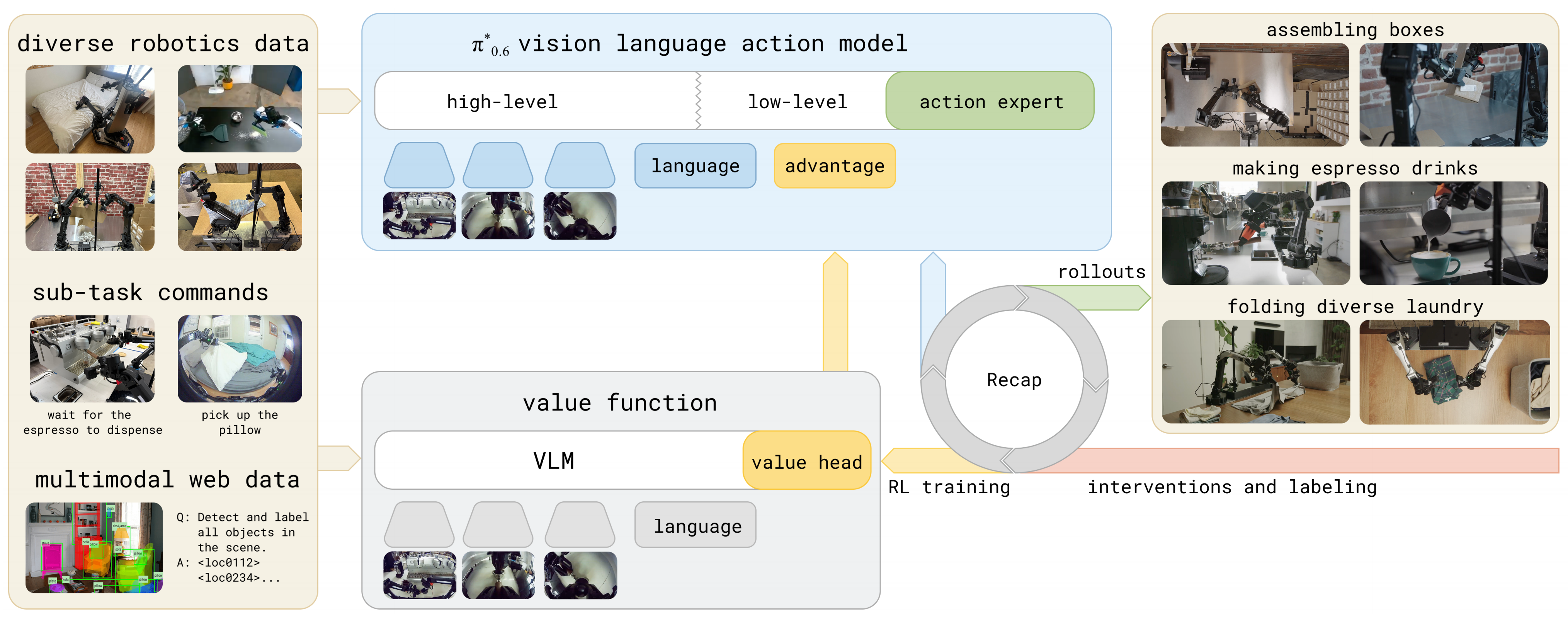
比如在这篇 LWD 论文复现 RECAP 作为基线对比时,就是算出优势值后,只保留排名前 30% 的优质数据以及人类干预的数据 - LWD:采用了更纯粹、更直接的强化学习优化。 它不走过滤数据做监督学习的路子,而是直接计算 Critic 网络对动作的梯度
,并通过伴随匹配技术 (QAM) 直接指导流模型 (Flow-based VLA) 调整动作生成的向量场
这是一种直接把强化学习学到的“价值提升”灌入生成式 VLA 的端到端优化机制
2. 价值估计的维度:标量期望 vs. 概率分布
- RECAP:通常预测一个标量的期望回报来计算 Advantage
- LWD:作者认为真实的机器人集群数据极其异构,如果用标量去平均化回报,会掩盖掉那些罕见但完全可复现的高回报(成功)模式
因此,LWD 提出了 DIVL (分布隐式价值学习),它预测的是动作回报的概率分布(保留了多模态特征),而不是一个干瘪的平均数
3. 训练飞轮的节奏:迭代式离线 vs. 持续在线异步
- RECAP:是一种典型的“收集-训练-部署”的迭代式离线 RL (Iterative offline RL) 。你需要先派机器人出去跑一批数据,收集回来,离线算 Advantage,过滤数据,微调模型,然后再把新模型推向业务线。LWD论文指出,这种方式适应分布偏移的速度较慢
- LWD:被设计成了一个持续在线的集群系统 (Continuous online system)。前线的机器人集群不断执行任务产生数据(无论成败),后方的中心学习器异步地将新收集的在线数据和底层的离线数据混合(50% 对 50%),持续计算梯度更新模型,并定期将最新的权重下发给前方机器人 。它实现了一个真正意义上的实时“数据飞轮”
总结
- RECAP 的底层逻辑是:用强化学习的眼光去“挑出好数据”,然后退回到模仿学习的舒适区去微调策略,求稳求顺
- LWD 的底层逻辑是:正面强攻,用分布式的价值评估直接算出强化学习梯度去硬改流模型(Flow-matching)的输出,并且通过集群异步架构把它做成了一个边运行边升级的在线系统
1.1.1 引言
如原论文所述,要在真实世界中部署通用机器人,就需要高性能的通用策略:这类策略必须能够在多样的物体、环境、用户指令和运行条件下,可靠地完成广泛的任务
- 近期的VLA策略 [1-RT1, 2-Rt-2, 3-Octo, 4-Openvla, 5-π0, 6-π0.5] 通过利用大规模离线机器人数据集学习广泛的能力,为这一目标提供了有力基础
- 然而,仅依靠离线预训练并不足以让策略具备可部署性
真实世界部署并不是一个固定的测试分布:随着机器人在越来越多的家庭、商店、工作场所和用户之间被广泛使用,它们会遇到预训练数据覆盖范围之外的新任务、新物体实例、新配置、新偏好以及罕见的失败模式
因此,要获得高性能,就需要使策略能够持续从部署过程中的经验中不断改进,使得适应能力可以随着使用过程中产生的数据而扩展
而要实现这种形式的持续改进,需要具备既广泛又持续更新的部署经验 - 对于通用型机器人策略而言,最有价值的部署经验自然而然是在有舰队规模下收集到的
任何单个机器人仅能采样到已部署分布中的一小部分,而一个机器人舰队则横跨多样化的任务、环境、物体和用户指令,从而产生异质性的经验,这些经验包括成功、失败、恢复、部分进展、罕见边缘情形以及偶发的人类干预
————
通过共享策略聚合这些物理经验,可以形成一个闭环的数据飞轮:已部署的机器人在目标部署分布上生成经验,而共享的策略从聚合数据中不断改进,而改进后的策略会被重新部署,以收集更广泛且信息量更高的经验
作者将这一设定称为部署中学习(Learning WhileDeploying, LWD):即由已部署机器人集群在真实世界中持续自主交互所累积的经验驱动的持续策略改进
然而,要将这一数据飞轮转化为一种学习算法,需要一个能够从自主交互结果中改进的训练目标,而不是把部署数据仅仅当作模仿学习的信号
- 交互式模仿学习方法 [7-Hg-dagger: Interactive imitation learning with human experts] 可以在部署期间引入专家示范、纠正和干预,但它们主要将部署过程视为监督学习中动作标签的来源
因此,它们只利用了可用经验的一部分,而且缺乏一种有原则的机制来利用包含成功、失败、恢复、部分进展以及任务奖励等信息的自主试验 - 强化学习在原理上提供了这样一种机制,它通过任务结果和策略交互经验来优化策略行为
8-Q-learning
9-Addressing function approximation error in actor-critic methods
10-Continuous control with deep reinforcement learning
11-Soft actor-critic: Off-policy maximum entropy deep reinforcement learning with a stochastic actor
然而,现有的机器人强化学习方法通常局限于小规模、短时程或任务特定的设定,并且经常是在一个预训练的通用策略基础上专门化到某个狭窄任务
12-Rl-100: Performant robotic manipulation with real-world reinforcement learning
13-Gr-rl: Going dexterous and precise for long-horizon robotic manipulation
14-Conrft: A reinforced fine-tuning method for vla models via consistency policy
即,一种既能在部署后基于集群部署经验对端到端 VLA 策略进行后训练、又能保持其通用性、同时具备可扩展性的方法,仍然是一个尚未解决的开放问题
要弥补这一空白,需要一种用于 LWD 的强化学习(RL)算法:它既要与预训练的 VLA 策略兼容,又能够利用大规模离线和 off-policy 数据集进行学习,并且还能在新的部署数据不断流入时快速适应
这些需求同时对强化学习方法的两大组成部分提出了压力
- 价值学习必须能够在异质的off-policy 数据、稀疏奖励以及罕见的高回报轨迹条件下,产生可靠的估计
- 策略提取则必须能在不破坏模型稳定性的前提下,将学到的价值转化为来自大型生成式 VLA 策略的更优动作
然后,现有工作仅部分满足这些要求
- Amin 等人 [15-π*0.6 : a vla that learns from experience] 将离线价值学习与迭代式离线 RL 结合,但其过程较为缓慢,并且没有直接利用从已学习价值函数中得到的动作梯度
- Luo等人[16-SERL, 17-HIL-SERL] 展示了在线 RL 可以通过真实世界交互在较短时间内学会具有挑战性的机器人操作任务,但其是从零开始训练任务特定策略,而不是在此基础上改进一个预训练的通才策略
- 基于 on-policy 的 VLA 微调方法
18-Vla-rl
19-Interactive post-training for vision-language-action models,即RIPT-VLA
在传统的"预训练 + 监督微调(SFT)"两阶段范式之上,引入第三个阶段——基于强化学习的交互式后训练,仅利用稀疏的二元成功/失败奖励
20-πrl: Online rl fine-tuning for flow-based vision-language-action models
21-Flow-grpo: Training flow matching models via online rl
22-Reinflow: Finetuning flow matching policy with online reinforcementlearning
直接利用在线 rollout 对预训练策略进行更新,但并未设计为高效复用大规模离线或off-policy 部署缓冲区的数据
这类方法也不会学习显式的动作价值评论家(action-value critic),因此无法利用动作空间上的评论家梯度来指导策略改进综合来看,这些局限性共同促使作者采用一种“离线到在线”的 RL 思路:既能复用异质的部署数据,又能在保持稳定性的前提下改进预训练的生成式 VLA 策略
由此,作者提出了车队规模的离线到在线强化学习(Fleet-Scale Offline-to-Online RL),这是一个用于在大规模真实部署系统中对端到端 VLA 策略进行后训练的离线到在线框架
该框架由两部分组成:
- 基于离线数据的分布式价值学习
- 以及来自自主部署的经验,并通过稳定的策略提取机制,将价值提升迁移为基于流(flow-based)的 VLA 策略
具体而言
- 在价值学习方面,作者提出了分布式隐式价值学习(Distributional Implicit Value Learning,DIVL)
DIVL 构建在 Implicit Q-Learning [23-Offline reinforcement learning with implicit q-learning] 的价值学习组件之上,但用分布式价值模型替代了标量 expectile 价值回归
这一选择在规模部署场景中尤为关键:机器人在不同策略版本下、跨异质场景、以异步方式收集数据,且奖励稀疏,包含失败、部分恢复以及偶发的人类干预
因此,同一状态-动作对所对应的回报可能呈现多峰分布且具有重尾特性
标量评论器(scalar critic)可能会将这些结果压缩为一个平均值,从而掩盖罕见但可复现的成功;而分布式评论器(distributional critic)则可以保留这些高回报模态
因此,DIVL 在保持隐式价值学习“在支持集内(in-support)策略改进”性质的同时,学习多步回报分布
这样一来,就能从大规模离策略部署缓冲区中获得稳定的学习信号,而无需策略去查询分布外的动作
- 在策略提取方面,作者采用带有 Adjoint Matching的 Q-learning(QAM)——以专门解决扩散/流匹配策略的策略提取难题
critic 能为动作提供有用的梯度,但若将这些梯度沿着流式策略的完整多步去噪过程反向传播,则会变得不稳定且代价高昂
QAM 将在去噪动作处得到的 critic 梯度转换为针对流模型的逐步监督
这样一来,就能在保持生成式动作建模表达能力的同时,为从学习到的价值函数中稳定地更新 VLA 策略提供一种方法
总之,QAM 将 Domingo-Enrich 等人提出的 Adjoint Matching 技术从生成模型领域引入 RL,把 critic 的动作梯度转换为逐步step-wise目标函数。这使其能够:
完全避免通过多步去噪过程的不稳定反向传播
在理论上无偏地收敛到最优行为约束策略
保留多步流策略的完整表达能力
完整系统分为两个阶段:
- 首先在来自多种来源的混合数据上进行离线预训练
- 随后利用部署阶段的数据进行快速在线微调
两个阶段都优化相同的强化学习RL目标,这减轻了一种常见的“离线到在线”不匹配问题:离线阶段学到的 critic 可能会过于保守,并且对后续的在线微调校准不佳,而在线性能提升则依赖于对新访问动作的价值进行外推 [26-Cal-ql: Calibrated offline rl pre-training for efficient online fine-tuning]
关于Cal-ql,详见本博客的解读《Calibrated Q-learning(简称Cal-QL)——为高效在线微调而对“离线RL预训练”做校准:让学到的Q值有上界(保持标准CQL已做到的相对保守),但保守得有底线(不能过分保守)》
最终,作者在一支由 16 台双臂机器人组成的机队上对其进行实例化,覆盖八个操作任务。在这些任务中,RL 可以通过多步动态规划传播回报,并将跨越部分进展的价值估计“拼接”起来,而模仿学习方法则更严重地受到误差累积的影响,而该 LWD 流程在典型情况下只需要数小时的真实世界交互
1.1.2 相关工作
首先,对于机器人通用策略的后训练
通用机器人策略,包括VLA 模型,通过在大规模、多样化的多模态数据上进行预训练来获取广泛的能力[2-Rt-2, 3-Octo, 4-Openvla, 6-π0.5]
为了将这些策略适配到下游部署,近期工作探索了多种后训练策略
27-Grape: Generalizing robot policy via preference alignment
20-πRL
12-RL100
15-π*0.6
28-Rlinf-vla: A unified and efficient framework for vla+ rl training
29-What can rl bring to vla generalization? an empirical study
其中一个方向研究离线(RL)后训练,即使用先前收集的rollouts来改进策略[27-Grape, 15-π*0.6, 30-RLDG]
- π∗0.6 将离线价值学习与迭代离线RL 相结合,在单个真实世界任务上取得了显著提升[15]
- RLDG使用专门的RL 来生成用于策略蒸馏的数据,提供了另一种引入RL 监督的方式[30]
详见本博客中的解读《知识蒸馏RLDG:先基于精密任务训练RL策略(HIL-SERL),得到的RL数据去微调OpenVLA,最终效果超越人类演示数据》
然而,仅使用离线的后训练遵循 “收集-训练-部署” 的循环,无法立刻利用在部署过程中收集到的经验,从而使得对分布偏移的适应较为缓慢[15, 30]
LWD 则是在部署期间更新策略,使新收集到的经验能够快速纠正此类偏移
另一类相关工作使用在线RL进行后训练
- 包括 VLA-RL [18] 和 RIPT [19],在模拟任务中的专用策略上取得了显著提升
31-Behavior-1k: A benchmark for embodied ai with 1,000 everyday activities and realistic simulation
32-Maniskill: Generalizable manipulation skill benchmark with large-scale demonstrations
33-Libero: Benchmarking knowledge transfer for lifelong robot learning
34-Robotwin: Dual-arm robot benchmark with generative digital twins (early version)
20-πRL
35-Rlinf-user: A unified and extensible system for real-world online policy learning inembodied ai36-Wovr: World models as reliable simulators for post-training vla policies with rl
——
然而,这些方法通常依赖于 on-policy 的数据收集方式,对于现实世界机器人而言,这种方式在样本利用上效率较低且成本较高 [20-πRL, 37-Simplevla-rl: Scaling vla training via reinforcement learning]- 相较之下,LWD 从大规模离线数据集学习,并结合 off-policy 的在线重放,从而提升了现实世界后训练的可行性
当然了,近期方法也将离线与在线阶段相结合:先在rollout 数据集上进行离线预训练,然后通过实时交互进行在线细化
- 13-Gr-rl,详见本博客中的解读《GR-RL——首个让机器人系鞋带的VLA:先离线RL训练一个“分布式价值评估器”以做任务进度预测,后数据增强,最后在线RL》
- 14-Conrft
对于Conrft,详见本博客中的解读《ConRFT——Consistency Policy下RL微调VLA的方法:先通过示教数据离线微调(Cal-QL的Q损失基础上引入BC损失),后在线RL微调(引入RLPD的新老数据对称采样及人工干预)》 - 12-Rl-100,详见本博客中的解读《RL-100——基于真实世界RL的高性能灵巧操作:先基于人类演示做模仿学习预训练,再做迭代式离线RL,最后真机在线RL》
不过,以往方法通常学习的是针对单一任务定制的专用策略,从而限制了在多样化部署场景中的泛化能力 [13, 12]
总之,LWD 在本质上与这些工作不同:它对通用机器人策略执行从离线到在线的后训练,而不是学习针对特定任务的专用策略。这使得能够在多个真实世界任务上对单一策略进行可扩展的后训练,其中包括具有稀疏奖励的长时间跨度任务
其次,对于离线到在线的强化学习
离线到在线的强化学习(offline-to-online RL)先在多样化的离线数据上进行预训练,然后通过在线交互持续优化
38-Flow q-learning
25-Q-learning with adjoint matching
39-Uni-o4: Unifying online and offline deep reinforcement learning with multi-step on-policy optimization
40-Offlineto-online reinforcement learning via balanced replay and pessimistic q-ensemble
12-Rl-100
14-Conrft
30-Rldg
41-Reincarnating reinforcement learning: Reusing prior computation to accelerate progress
42-Efficient online reinforcement learning with offline data,详见本博客中的解读《RLPD——利用离线数据实现高效的在线RL:不进行离线RL预训练,直接应用离策略方法SAC,在线学习时对称采样离线数据》

- Luo 等人[16-SERL, 17-HIL-SERL] 利用少量人类示范来启动策略学习,并随后通过真实世界交互对单一机器人技能进行专门化
然而,LWD 与这一方法不同之处在于:它在多任务上对一个共享的通用 VLA 策略进行后训练,将离线与在线的回放统一在一个学习循环中,并在分布式、车队级部署环境下运行 - 近期研究采用不同的策略提取机制,在在线改进阶段重用离线数据
25-Q-learning with adjoint matching
43-Awac:Accelerating online reinforcement learning with offline datasets
44-Hybrid rl: Using both offline and online data can make rl efficient
45-Steering your diffusion policy with latent space reinforcement learning
————
然而,现有方法尚未在通用型 VLA 策略的稳定车队级后训练方面得到验证。LWD 针对这一问题进行研究,并采用 QAM,在大规模真实世界部署中实现离线到在线的强化学习
近期的机器人后训练方法引入了离线到在线的强化学习offline-to-online RL以改进策略
- 13-Gr-rl
- 12-Rl-100
- 14-Conrft
- 30-RLDG,详见本博客中的解读《知识蒸馏RLDG:先基于精密任务训练RL策略(HIL-SERL),得到的RL数据去微调OpenVLA,最终效果超越人类演示数据》
然而,这些方法通常侧重于针对特定任务的策略,在离线到在线各阶段之间的训练目标不一致,并且仅在受限的部署规模下运行
相比之下,LWD 通过车队级的离线到在线强化学习,在多样化任务上训练通用策略。它在离线和在线阶段采用统一的训练方法,从而提升了训练的稳定性和可扩展性
最后,对于大规模机器人强化学习系统
大规模机器人强化学习(RL)系统通过汇聚分布式执行体(actors)的经验并训练集中式学习器,从而改进机器人策略,使策略性能可以超越仅依赖孤立任务级数据采集所能达到的水平
46-Qt-opt: Scalable deep reinforcement learning for vision-based robotic manipulation
47-Mt-opt: Continuous multi-task robotic reinforcement learning at scale
48-Pi-qt-opt: Predictive information improves multi-task robotic reinforcement learning at scale
49-Sop: A scalable online post-training system for vision-language-action models
50-Robocat: A self-improving generalist agent for robotic manipulation
51-Impala: Scalable distributed deep-rl with importance weighted actor-learner architectures
52-Deep rl at scale: Sorting waste in office buildings with a fleet of mobile manipulators
- Kalashnikov 等人 [46, 47] 展示了如何通过异步机器人数据采集与集中式 Q 函数优化,将离线策略强化学习从基于视觉的抓取扩展到多任务操作
尽管这些系统主要聚焦于短时域操作任务,并且策略大多从零开始学习,LWD 则是在多样化的真实世界任务(包括长时域操作)上对一个预训练的通用 VLA 策略进行后训练 - Bousmalis 等人 [50-Robocat]和 Herzog 等人[52-Deep rl at scale] 进一步研究了如何从大规模机器人经验中学习,但前者依赖行为克隆,而后者则针对废物分拣的任务特定 RL
————
最新地,SOP Pan 等人 [49-Sop] 形式化提出了用于可扩展在线后训练 VLA策略的系统基础架构,将分布式机器人群与集中式云端学习器以及异步策略同步机制相结合
在这一部署基础上,LWD 采用离线到在线 RL 来具体实现学习算法
它联合利用先前的离线数据和新近收集的车队经验,在长时域的真实世界任务中持续改进单一的通用策略
这种区分将贡献点从仅仅是分布式执行,转移到由强化学习驱动的数据“飞轮”上,在该机制中,大规模部署会持续为策略改进提供经验数据
1.1.3 问题设定与符号说明、隐式 Q 学习、流匹配与结合伴随匹配的 Q-learning
第一,对于问题设定与符号说明
作者将机器人控制形式化为马尔可夫决策过程,其中
是折扣因子
- 且考虑由
索引的一组任务,每个状态
由机器人观测
和指定任务
的语言指令
组成
对于长时间跨度任务, - 在作者的设定中,使用稀疏二值奖励,当一次试验成功终止时
,否则
LWD 在所有任务上训练一个共享的通用 VLA 策略。在时间步 ,该策略将状态
作为输入,并输出一个动作块(action chunk)
该动作块会在重新规划之前被执行。对应的块奖励为
因此,混合任务重放样本可以抽象地写为,其中
表示重放分布
- 在离线阶段,
由来自
的样本所诱导
- 在在线阶段,它由来自
的混合重放所诱导
在整个方法中,通才策略和评价器都在动作块上进行操作
第二,对于隐式 Q 学习(Implicit Q-Learning)
隐式Q学习(Implicit Q-Learning, IQL)[23-Offline reinforcement learning with implicit q-learning] 通过拟合一个标量状态价值函数到数据集中动作价值的高分位期望(expectile),从而避免了显式的动作最大化『Implicit Q-Learning (IQL) [23] avoids explicit action max-imization by fitting a scalar state-value function to a high expectile of dataset action-values』
- 沿用上文中关于(
,
) 的分块记号,IQL 拟合
且
并且表示目标网络,其参数通过指数移动平均进行更新
- 而评论器
通过基于价值的TD 目标进行训练
通过
当时,这个价值估计会偏向于数值较高的数据集动作,从而给出一个隐式的提升目标而不需要使用
形式的回溯
在 LWD 中,作者保留这一不对称自举(bootstrap)原则,但将标量期望分位值回归替换为分布式价值模型,并采用基于分位数的价值提取方式
第三,对于流匹配与结合伴随匹配的 Q-learning
Flow Matching(FM)[53-Flow matching for generative modeling] 将生成策略表示为一个与时间相关的向量场。给定数据动作片段 和高斯噪声
,FM 定义插值
并训练一个条件向量场来匹配速度
。基于流的VLA 策略将这一结构用作动作生成头[5, 6]
- 对于对于策略提取,流策略必须通过多步生成过程进行优化,这使得直接的评论家反向传播代价高且可能不稳定
- 带有伴随匹配的Q 学习(QAM)[25-Q-learning with adjoint matching,2026] 通过将TD 评论家学习与伴随匹配的策略更新相结合来解决这个问题
即给定一个预训练的参考流 和一个评论家
,QAM 定义了KL正则化的改进目标
其中 为温度系数。由此得到的策略更新可以写成沿参考流轨迹进行的局部回归目标——定义为公式9:
其中且
为伴随状态,其终端条件为——定义为公式10
LWD 使用 QAM [25] 作为其策略提取机制,利用由DIVL 学得的评论家来为流策略构造局部回归目标
1.2 部署中学习的完整方法论
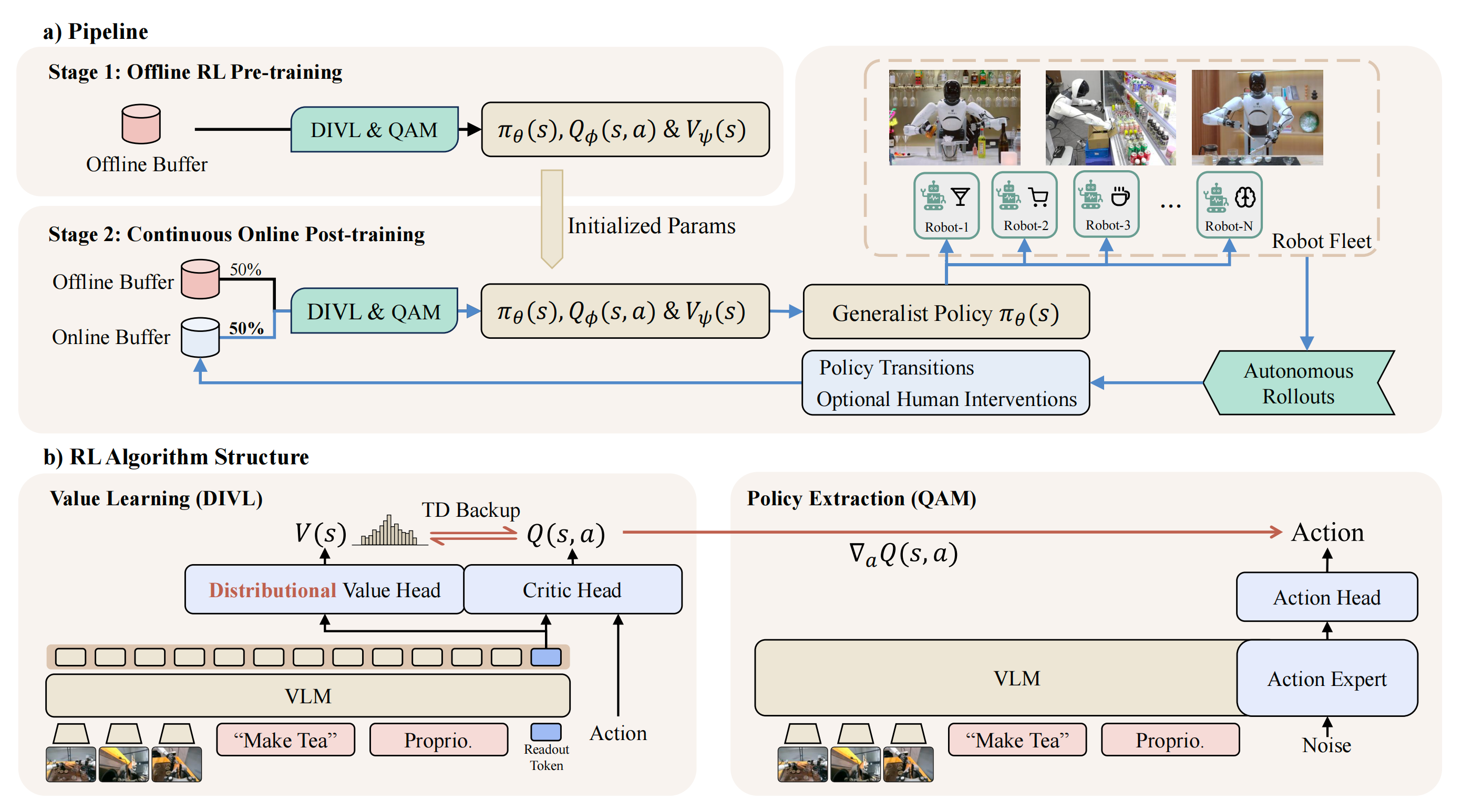
LWD 遵循图2(a) 所示的offline-to-online 循环『a)流水线。训练被组织为两个阶段。阶段 1 在离线缓冲区上执行离线强化学习预训练。阶段 2 进行持续的在线后训练(post-training),其重放数据由静态离线缓冲区与持续更新的在线缓冲区混合构成。一组执行体(actors)被自动部署到多种真实世界机器人任务上以采集在线数据,并将其追加到持续更新的在线缓冲区中』
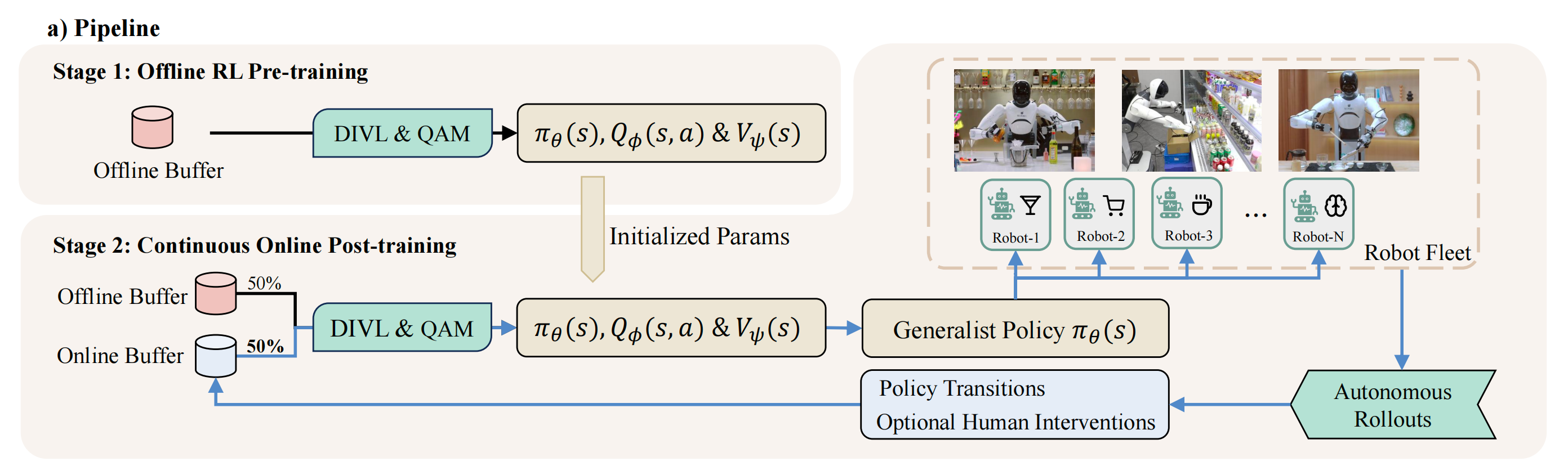
- 离线阶段在静态重放缓冲区
上训练策略
、评论家
,为部署提供初始化
The offline stage trains the policy, critic, and distributional value model on a static replay buffer Boff - 在线阶段将当前策略部署到一队机器人执行体上进行自主rollouts,从而用策略转移和可选的人类干预填充
『which populate Bon with policy transitions and optional human interventions』
学习器在来自的混合重放上更新
,并周期性地重新部署更新后的策略
这形成一个数据飞轮:机器人rollouts 扩展重放数据,混合重放更新策略,而更新后的检查点被重新部署到整支队伍中,而在该循环中,学习器结合了两个优化组件
- 首先,分布式隐式价值学习(DIVL)训练评论家
- 其次,基于QAM 的策略提取使用从DIVL 中学习到的
1.2.1 分布式隐式价值学习
分布式隐式价值学习(DIVL)是LWD 的价值学习组件。它学习一个关于重放动作价值的分布,并使用该分布的一个分位数作为块级评论家的自举目标
这样的设计在避免使用单一标量期望分位目标的同时,保留了IQL [23] 的不对称自举原理
- 具体而言,分布式价值模型
表示数据集中动作价值的、以状态为条件的分布 [54]:
其中表示在条件状态
下的经验回放动作分布
- 因此,
相反,它表示在状态
作者通过最小化来自指数滑动平均(EMA)评论器
在作者的实现中,表示为类别离散化;附录A1 给出了细节
————
与 IQL 中使用的标量回归相比,这种分布式参数化形式与 LWD的契合度更高
此前研究[55] 发现,对回报值进行类别分布表示在多样的多任务离线强化学习设置中是有帮助的
此外,它支持下面使用的两种设计:
- 自举统计量被选为
的一个分位数,而无需重新拟合标量价值函数
- 并且
故,作者使用的
分位数作为自助法统计量
其中是由
诱导的累积分布函数
这得到TD 目标
以及评论器损失(定位为公式15)
这与离线强化学习的设定相契合,其中目标应当偏向于高价值的重放动作,而不过度向数据之外外推- 总之,IQL 使用标量期望分位(expectile)价值回归来解决同一问题
DIVL 保持了这种非对称价值学习的原理,但通过分布式模型和分位数统计来实现它
为了将这种联系表达得更为明确,作者在一个广义的非对称损失族下写出价值目标:
其中,
给出了IQL 使用的期望分位形式,而
给出了DIVL 使用的分位数形式
进一步的,作者在原论文中提出了
命题 1(非对称价值学习的分布视角):
- 对于该族中任意一个固定的非对称损失,直接进行标量回归
和- 采用作者的两步过程——先拟合价值分布,再从中提取相应的非对称统计量
这两种方法在最优时得到的标量价值是相同的
至于证明见附录 A2。该命题表明,DIVL 通过两步过程(先进行分布式价值估计,再提取
如原论文所说,这一结果支持在固定
- 较大的
- 较小的
在混合任务回放中,同一水平的乐观程度不一定适用于每个状态,因此作者利用学习到的价值分布中的不确定性,自适应地调整
- 具体而言,作者使用范化后的熵(normalized entropy)来度量在状态
下的类别分布
的不确定性信号:
其中是类别数,
是分配给类别
的概率
- 然后,自适应调度为
其中,是对置信状态的目标值,
控制不确定性敏感度,超参数取值在附录B2 中给出
————
弥散的分布会被赋予较小的
且作者在计算TD 目标时,将视为停止梯度处理
1.2.2 通过 QAM 进行策略抽取
LWD 中的策略提取从一个预训练的flow-matching VLA开始,旨在在保持生成式动作头不变的前提下,利用DIVL评论器(DIVL critic)改进其动作分布
- 现有的离线RL 方法通常在不对
这一更新方式与基于flow 的VLA 策略不太匹配,因为它需要在多步flow 生成策略下评估动作块的对数似然
——
更一般地,KL 正则化的策略改进目标具有玻尔兹曼形式,其归一化因子需要在高维动作块上进行积分 - 另一种方法是使用一阶动作梯度
来改进采样得到的动作片段
然而,对于flow 策略,通过对完整的多步生成过程进行直接反向传播来应用该更新,在计算上代价高昂且在数值上不稳定(分析见附录A3)
这使得直接评论家反向传播难以作为大型VLA 策略的优化方法使用
因此,作者采用如图2(b) 右侧所示的QAM 进行策略提取[25]。如第III-C 节所述,QAM 将轨迹层面的策略优化重构为沿参考流的局部回归目标
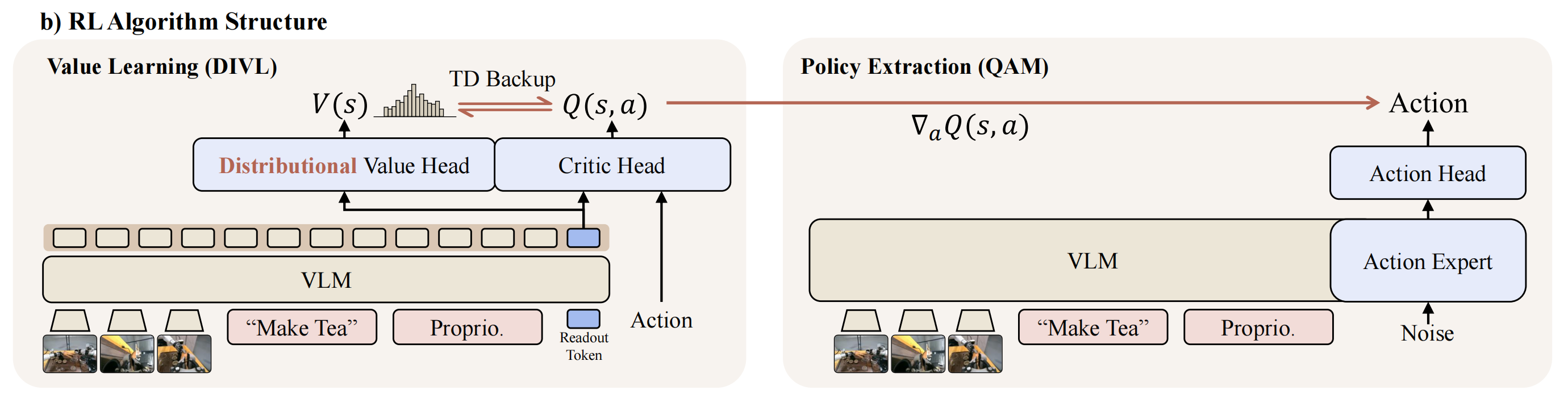
- 具体而言,DIVL 评论家
,而该状态反过来又引导策略向量场的精炼(Eq. (10))
- 特别地,如原论文所说,作者将
保持固定,作为离线强化学习之前通过行为克隆初始化的流,并在整个离线和在线训练过程中优化
对于每个回放小批量,如算法2 的第5-7 行所示
作者对状态和高斯噪声进行采样,展开
算法二是训练循环内部的微观数学引擎——核心思想:VLA 模型与 RL 的稳定融合引擎 (DIVL + QAM)
如果直接把 RL 的价值梯度穿透庞大的流匹配Flow-Matching生成式 VLA 模型去反传,极易导致训练崩溃且计算昂贵
算法 2 将其巧妙地拆分为两步:
- 先用 DIVL 预测价值分布(找准方向)
- 再用 QAM 伴随匹配技术把价值梯度“翻译”成流模型能听懂的局部回归目标(教给手脚)
逐行解读:
输入 (Require): 接收一个 Mini-batch 的数据块(包含当前状态、动作、奖励、下一状态)、Critic 网络、分布式价值网络、当前策略
以及冻结的参考策略
第一部分:分布隐式价值学习 DIVL
Line 1: 通过最小化交叉熵损失(Eq 12)
拟合当前状态的价值概率分布
这使得模型能记住罕见的高分操作,而不是把它平均化Line 2: 计算 TD 目标值
(Eq 19)
这里不再取均值,而是提取价值分布的特定分位数Quantile,并辅以自适应的不确定性调节Line 3: 使用标准的均方差(MSE)损失(Eq 15)
让 Critic 网络向刚才算出的
Line 4: 动量软更新目标 Critic 网络,维持训练的平滑
第二部分:基于伴随匹配的策略提取 (QAM)
Line 5-6: 针对当前状态,采样高斯噪声,并利用那套冻结的参考策略(行为克隆打底的模型)
跑出一个基准的流匹配动作轨迹
Line 7: 确定动作轨迹的终点
Line 8: 最核心的一步
在动作轨迹的终点,计算出刚才学到的 Critic 对动作的梯度
将这个带有明确“好坏”方向的梯度设定为伴随状态(Adjoint State),反推出对流模型向量场的局部回归约束(Eq 9)
从而稳稳地把强化学习的奖励导向,注入到 VLA 策略Line 9: 返回更新完毕的所有网络参数,结束一次微观迭代


1.2.3 从离线到在线的强化学习训练流程
如图2(a) 中的LWD 循环所示
训练后处理分为两个阶段,这两个阶段共享相同的价值学习和策略提取目标,但在数据来源上有所不同
离线阶段在离线缓冲区 上进行训练,如图2(a) 的阶段1 以及算法1 的第4-7 行所示
该离线缓冲区包含三种来源:
- 示范数据,即由专家收集的成功轨迹
- 回放数据,即由历史策略生成的轨迹,包括成功和失败
- 以及游戏数据,即由人类引导对失败模式进行探索的数据
所有这三类数据都被转换为与在线回放相同的分块转移格式,终止时的成功或失败标签用于赋予稀疏的二元奖励。数据结构的细节如表IV 所示
总之,LWD 利用离线缓冲区对策略、评论者
和分布式价值
进行预训练,为在线阶段的部署和训练提供一个良好的初始化
此外,由于长时间跨度的任务会持续数千个步骤且奖励极其稀疏,式(14)中
的单步目标只能非常缓慢地传播成功信号。因此,在离线阶段使用 n 步分块级 TD 目标来冷启动评论器和分布式价值模型——定义为公式19
其中,短期任务(例如杂货补货任务)取n = 1,而长期任务取n = 10。如果一个episode 在n 步窗口内终止,作者在终止片段处截断回报并移除bootstrap 项。该目标通过固定的离线重放缓冲区加速稀疏奖励的传播
- 然,在在线训练过程中,作者发现冗长的多步骤目标效果不佳,作者宣称,一个可能的原因是,在线轨迹将策略自身的状态转移与人工干预混杂在一起。较长的回溯更有可能跨越这两类来源,因此 TD 路径可能不再对应于一次单一策略的执行
- 鉴于评论器和价值模型已经通过离线数据完成了初始化,因此作者在在线更新时使用 1 步、以片段为粒度的 TD 目标
在线阶段将离线初始化得到的策略部署到机器人集群上,如图 2(a) 的阶段 2
以及算法 1 的第 8–31 行所示
机器人执行当前策略检查点,并异步地将策略转移流式写入在线缓冲区
干预片段在的常规在线回放过渡段进行存储
- 得到的表示被输入到一个采用截断双 Q(clippeddouble-Q)结构的两个标量评论器(critic)头中,在该结构中,使用两个评论器估计中的最小值来构造 DIVL 目标并进行 TD 回传,以缓解 Q 值过高估计的问题
算法一描述的是 LWD 的宏观系统管线——核心思想:打造集群级的异步“数据飞轮” Pipeline
它不是一个单纯的数学优化循环,而是一套融合了离线静止数据、线上集群持续收集、异步中心训练以及版本分发的工程调度框架 。它的精妙之处在于将机器人的“部署测试”转变成了“持续造血”的过程
逐行解读:
准备阶段 (Require): 定义了所需的离线缓冲区
(其中包含纯净的专家演示数据
)、在线缓冲区
、机器人执行端集群Actor Fleet,以及各项训练周期和同步频率的参数
Line 1-3 (初始化): 系统的冷启动。首先用专家演示数据对策略网络
然后将这个预训练模型锁定为一个不可变的参考策略Line 4-7 (Stage 1: 离线预训练): 在纯离线数据集
LEARNER——即上面介绍过的算法二,让策略网络和价值网络初步掌握“什么动作是高价值的”Line 8-24 (Stage 2: 在线执行端 Actor Process): 这是一个部署在边缘侧机器人上的异步进程,相当于前线打工人
即多台物理机器人在真实世界里不断执行任务。遇到搞不定的,人类就上去帮一把(接管干预)。机器人会把每次任务的录像、动作和最终结果(成功还是失败)打包,不断往云端数据库里传
Line 10-20: 机器人单次任务的执行循环。如果当前任务需要人类干预,人类操作员就会介入并提供纠正动作
执行动作后更新观测状态,直到任务超时、失败或成功Line 22-23: 这里非常关键,分配稀疏的二值奖励(成功才给 1,否则给 0),并打包成动作块(Chunked)级别的奖励 。然后将这段新经历塞入在线缓冲区
Line 24: 边缘端定期拉取云端下发的最新策略权重,准备下一轮执行
Line 25-31 (Stage 2: 在线训练端 Learner Process): 这是一个部署在云端的异步中心化训练进程,相当于后方大脑
即云端服务器不干活,只负责疯狂学习。它从数据库里随机抓取数据(50% 离线的旧数据 + 50% 刚刚传回来的新数据),不断更新模型参数。每隔一段时间(比如 50 步),就把练好的新模型“空投”给前线所有机器人,覆盖它们的老脑子
Line 26-27: 它不断地从混合了离线和在线数据的池子中(保持约 1:1 的比例)采样,调用
LEARNER更新算法计算梯度,刷新模型参数
Line 28-30: 每隔一定的训练步数(如 50 步),就将最新的策略模型






该执行体遵循π0.5 基于flow 的VLA 架构[6]。它由一个PaliGemma视觉-语言骨干网络组成,该骨干网络由Gemma-2B 语言模型和SigLIP 视觉编码器实例化,并配备一个用于基于flow 的动作生成的Gemma-300M 动作专家
- 在离线强化学习阶段
actor 和 value/critic 网络都被完全微调;微调得到的权重用于初始化在线训练 - 在在线 QAM 更新过程中
策略 VLM 主干(backbone)被冻结,仅更新动作专家(actionexpert),而 value 和 critic 网络则在混合回放数据上继续进行完全微调
这一设计既保证了在线策略更新的高效性并保留了预训练的视觉—语言表示,又允许 value 和 critic 网络适应不断变化的回放分布,从而提供更新的策略改进信号
// 待更
转载自CSDN-专业IT技术社区
原文链接:https://blog.csdn.net/v_JULY_v/article/details/160663927

