
 hello大家好 欢迎来到小四季豆的博客
hello大家好 欢迎来到小四季豆的博客 ![]()
很多同学在刷算法题时都会遇到一个最大的痛点:两个都能算出正确结果的代码,为什么一个能 AC,一个会超时?其实是算法复杂度决定了代码的运行效率和资源占用
复杂度是衡量一个算法优劣的核心指标,也是面试和刷题中绕不开的考点。学会它,你才能看懂算法优劣、做题优化、面试答题。
这篇博客,我们就来深度剖析时间复杂度和空间复杂度(怎么快速估算、怎么识别陷阱、怎么做取舍)
一、什么是数据结构?
数据结构(Data Structure)是计算机存储、组织数据的方式。简单来说,它就是相互之间存在一种或多种特定关系的数据元素的集合。
没有一种单一的数据结构适用于所有算法,不同的算法,对数据的操作需求不同,对应的最优数据结构也不同。
1. 数据结构的基本组成
一个完整的数据结构,由数据元素、数据项、数据关系、基本操作四部分组成。
-
数据项:数据结构中最小的不可分割单位,是描述事物的基础信息。举例:存储学生信息时,姓名、学号、年龄、成绩,每一项都是独立的数据项。
-
数据元素:数据的基本处理单位,由一个或多个数据项组合而成 。举例:将一名学生的学号、姓名、成绩整合在一起,整体称为一个数据元素。数组、链表中每一个节点,本质都是数据元素。
-
数据关系:指各个数据元素之间存在的逻辑关联,这是区分不同数据结构的核心依据。比如数组元素前后依次相邻、栈遵循后进先出规则、树存在父子层级关系,都属于数据关系。
-
基本操作:针对数据元素实现的通用功能,所有数据结构都离不开五类基础操作:
|
查找 | 根据条件定位指定数据 |
| 插入 | 向结构中新增数据元素 |
| 删除 | 移除指定数据元素 |
| 修改 | 更新已有数据的内容 |
| 遍历 | 依次访问结构中所有数据 |
2.数据结构的两大核心结构
2.1 逻辑结构
逻辑结构是数据之间的抽象关系,它不依赖于数据在内存的存储方式,它是我们对数据结构问题抽象出来的模型。(思维层面)
举个例子:你要统计一个班的成绩,即使把名字乱序排列,在大家心里默认就是按“学号1→学号2→学号3……”这样的逻辑顺序统计
逻辑结构主要分为两类(线性/非线性)
- 线性结构:数据元素之间存在一对一的前后顺序关系
例如:像排队一样,除了第一个和最后一个,每个人前后都有一个人。
- 非线性结构:数据元素之间存在一对多或多对多或松散的关系
(1)一对多关系:树形结构,一个元素可以有多个后继,但只有一个前驱、
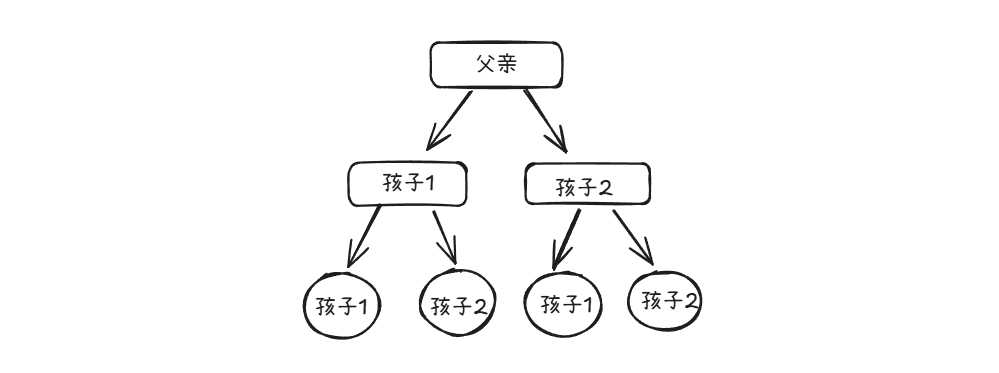
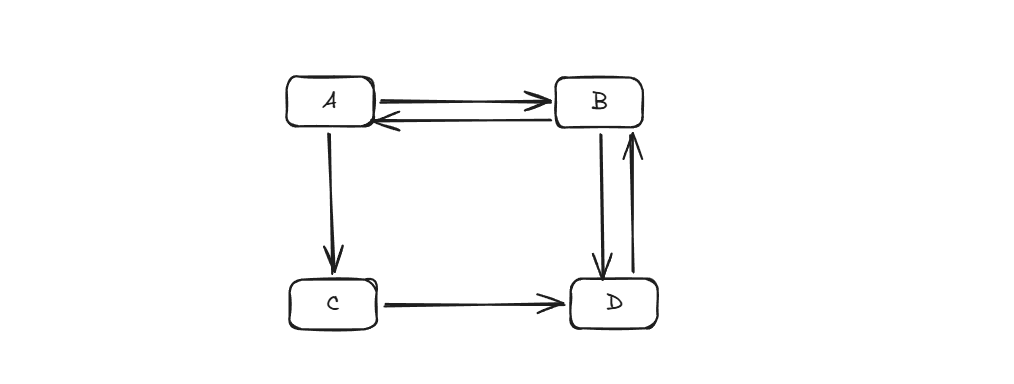
(2)多对多关系:图形结构,元素之间可以有多个前驱节点和后继,关系复杂
(3)松散关系:集合结构,元素之只同属于一个集合,无其他关系
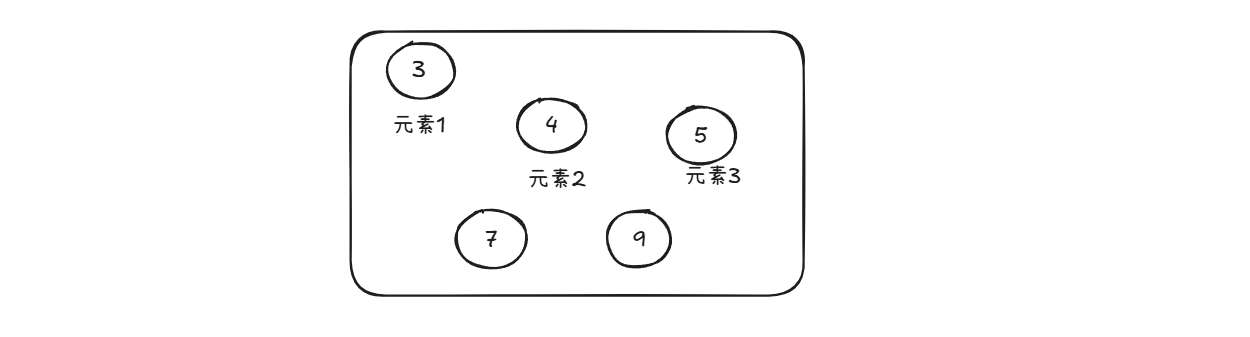
例如:一颗大树有n个分支,地铁图(多站地多路线)
2.2 物理结构
物理结构也叫存储结构,它依赖于计算机硬件结构是数据结构在计算机内存中的实际存储方式
举个例子:你统计成绩姓名学号的实际统计方式,eg:用表格,按学号排序填入连续的行;每个学生自己写,标注下一位学号是xxx;按姓名首字母统计;
物理结构主要分为四类(线性/链式/索引/散列)
- 顺序存储结构:数据元素按逻辑顺序依次存放在连续的内存(逻辑&&物理 相邻连续空间)
eg:数组数据的存放,在内存中是连续存放的
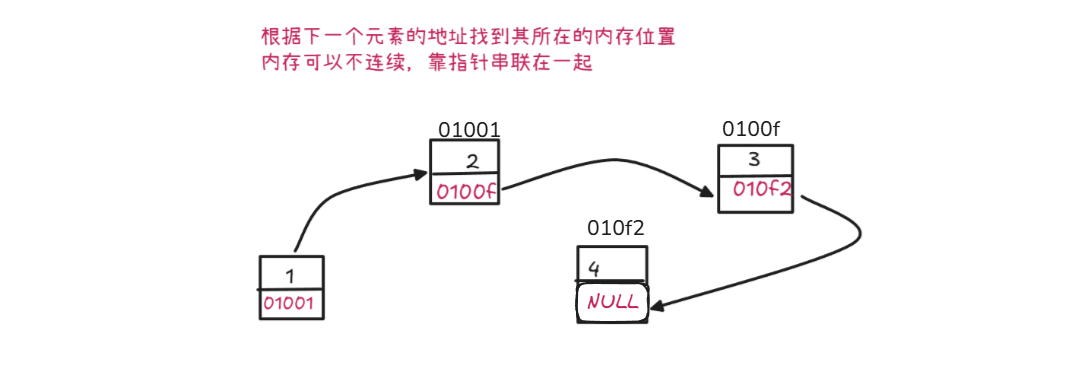
- 链式存储结构:数据元素可以存储在任意的、不连续的存储单元中,通过指针(或引用)将元素链接起来。(逻辑相邻,物理不一定相邻)
- 散列存储结构:散列存储结构也叫哈希存储结构,通过一个哈希函数将数据元素的关键字映射到存储地址。
eg:按学号分配座位,直接按学号就能找到座位,不用一个一个找
- 索引储存结构:为数据建立一个索引表,索引表中包含关键字与对应数据元素的存储地址。
eg:就像一本书的目录,按照目录就能找到对应的页数,能做到快速定位
二、什么是算法复杂度?
简单来说算法复杂度期数就是我们用来衡量一个算法好不好的标准,它剥离硬件,同一算法不计算不同电脑配置或运行环境的差异,只计算算法的运行时间和内存占用
算法复杂度主要分为两个维度:时间复杂度和空间复杂度
1.时间复杂度
时间复杂度是用来描述算法执行时间随输入数据量 n 增长的变化趋势的函数
![]() 注意:时间复杂度并不是指程序运行的时间,而是指算法中指令的执行次数
注意:时间复杂度并不是指程序运行的时间,而是指算法中指令的执行次数
程序运行时间=二进制指令运行时间*执行次数
单层循环执行
n次指令双层循环执行
n²次指令硬件只能让这些次数整体变快或变慢,但改变不了「n²次」和「n次」的相对增长趋势所以我们假设二进制指令运行时间相同,程序运行的时间就取决于算法中指令的执行次数
- 时间复杂度用T(n)=O(f(n))表示(大O渐进表示法)
T(n):算法的实际运行时间(和输入数据量n相关)
O(f(n)):渐进时间复杂度,描述当n足够大时,运行时间随n增长的变化趋势
f(n):代码执行次数的近似表达式
- 大O表示法的计算规则:只关注增长趋势最快的一项
(1)忽略低阶项:时间复杂度T(n)中,只保留最高阶项,去掉低阶项
eg:O(n² + n) 中,n² 增长最快,所以记为 O(n²)
(2)忽略常熟系数:如果最高阶项存在且系数不是1,则取出1这个项的常数系数
eg:O(2n) 记为 O(n)
(3)常数项记为O(1):T(N)中如果没有N相关的项,只有常数项,用常数1表示
eg:程序执行10次,执行次数与n无关,记为O(1)
![]() 注意: 大O的渐进表示法一般关注的算法的上界(最坏运行情况)
注意: 大O的渐进表示法一般关注的算法的上界(最坏运行情况)
------------------常见时间复杂度解析------------------
分析时间复杂度的核心:看循环看迭代
- O(1) 常数阶
代码执行次数固定,和输入量n无关
int b = arr[5]; // 1次访问,无论数组多大,只取第6个元素
int c = a + b * 2; // 常数次运算- O(log n) 对数阶
代码每执行一次数据缩减为原来的常数倍
时间复杂度只关注n足够大时的增长趋势,与对数的底数无关,因此统一记作 O(log n)
// 假设 n = 1024,循环只需要执行 10 次(2的10次方=1024)
int i = 1;
while (i < n) {
i = i * 2;
}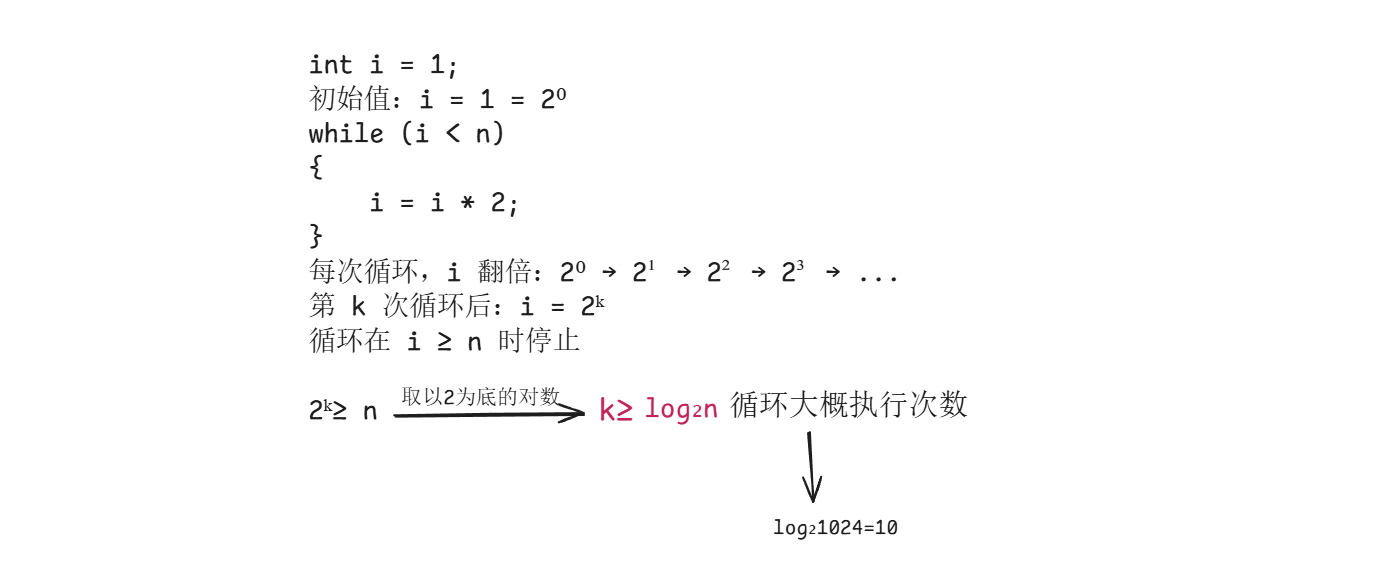
通过这个例子我们可以得到一个结论:对数阶在巨大数据量下,执行次数较少,是处理大数据量的利器。但对数阶也有不适用的场景,不能盲目的使用
- O(n) 线性阶
数据量多大就执行多少次
//n是几就打印几次
for(i=0;i<n;i++){
printf("%d",i);
}
while(n){
printf("%d",n);
n--;
}- O(n log n)线性对数阶
进行了n次对数阶的代码执行(一层O(n)循环嵌套一层O(log n))
// 外层循环执行 n 次,内层循环是对数阶
for (int i = 0; i < n; i++) {
int j = 1;
while (j < n) {
j = j * 2;
}
}- O(n²) 平方阶
进行了数据量的平方次的代码执行(双层嵌套循环每层都是O(n))
(n²的增长趋势相对来说是比较迅速的,当n较大时程序运行效率会明显下降)
// 外层执行 n 次,内层也执行 n 次,总次数为 n * n
for (int i = 0; i < n; i++) {
for (int j = 0; j < n; j++) {
// 执行 O(1) 的操作
}
}- O(2ⁿ)指数阶
数据量每增加1个,执行次数就翻倍
(2ⁿ的增长趋势是极其恐怖的,数据量为30时就达到了惊人的10亿次,程序面临超时/卡死)
// 暴力递归,每次调用 fib 都会分裂出两个新的调用
int fib(int n) {
if(n <= 1) return n;
return fib(n-1) + fib(n-2);
}仅适用于 n ≤ 20 的极小数据量
2.空间复杂度
空间复杂度是用来描述算法在运行过程中,额外占用的内存空间随输入数据量 n 增长的变化趋势的函数
![]() 注意:空间复杂度不计算输入数据本身占用的空间,只计算算法为了完成计算而额外开辟的临时空间。
注意:空间复杂度不计算输入数据本身占用的空间,只计算算法为了完成计算而额外开辟的临时空间。
- 空间复杂度用S(n)=O(g(n))表示(大O渐进表示法)
S(n):算法运行时额外占用的内存空间总量
g(n):由算法的内存分配行为抽象出的函数(如 1、n、\(\log n\) 等)
(Og(n)):渐进空间复杂度,描述当n足够大时,运行占用内存随n增长的变化趋势
------------------常见空间复杂度解析------------------
- O(1)常数阶
原地算法,算法运行过程中,只是用固定数量的临时变量
eg:只定义变量,固定大小数组,没有额外空间的分配
//交换数据
// 无论 n 如何改变,只用了 i, j, temp 这三个变量
void swap_elements(int arr[], int n) {
int i = 0, j = n - 1;
int temp;
while (i < j) {
temp = arr[i];
arr[i] = arr[j];
arr[j] = temp;
i++; j--;
}
}- O (log n) 对数阶
递归函数在调用时,系统会在内存的“栈”中为每一层递归保存临时数据
每次调用一个函数,系统都会在调用栈上创建一个栈帧,用来保存: 函数的局部变量、参数 ,函数返回地址 ,寄存器状态等信息
递归深度 = 栈的最大占用层数
// 有序数组二分查找,递归实现
int binarySearch(int arr[], int left, int right, int target)
{
if (left > right)
return -1;
int mid = (left + right) / 2;
if (arr[mid] == target)
return mid;
else if (arr[mid] > target)
// 左半区间递归
return binarySearch(arr, left, mid - 1, target);
else
// 右半区间递归
return binarySearch(arr, mid + 1, right, target);
}- O(n) 线性阶
额外开辟了n个空间
// 额外开辟了一个长度为 n 的新数组
void new_arr(int arr[], int n) {
int* newArr = (int*)malloc(n * sizeof(int));
for (int i = 0; i < n; i++) {
newArr[i] = arr[i];
}
free(newArr);
}- O(n²) 平方阶
数据量为n,额外开辟n²
//额外开辟 n × n 个 int 类型的空间
int **arr = (int **)malloc(n * sizeof(int *));
for (int i = 0; i < n; i++) {
arr[i] = (int *)malloc(n * sizeof(int));
}3.时间与空间的取舍
在刷算法题时,我们往往面临这二者的取舍问题,为了优化其中一个,往往需要舍弃另一个
- 空间换时间:为了提高运行速度,多消耗一些内存
- 时间换空间:为了用更少的内存,加大了重复计算
由于现在计算机内存通常比较充足,在日常开发中,我们优先选择用空间换时间,但取舍不是绝对的,我们要根据实际情况进行二者的平衡。
看懂复杂度只是第一步,接下来我们要学习各类数据结构,在后续数据结构的学习中我们对数据存储的认知会不断刷新继而循序渐进的提升算法思维
此篇到这里就结束啦~~ 希望本篇内容能帮大家理清思路哦~~ 我们下期再见![]()
如果觉得这篇文章对你有帮助,别忘了点赞收藏哦~~
转载自CSDN-专业IT技术社区
原文链接:https://blog.csdn.net/WHJJJJ_/article/details/161544145

